第 3 章 数据模型与查询语言
我的语言之界限,即我的世界之界限。
——Ludwig Wittgenstein,《逻辑哲学论》(1922)
数据模型也许是软件开发中最重要的部分,因为它对软件的写法影响如此之深,更深刻地影响着我们如何思考所要解决的问题。
大多数应用都是把一种数据模型层叠在另一种之上构建出来的。对每一层,关键问题是:它如何用更低一层的术语表示出来?下面给出从最高层到最低层的一组应用层级示例:
- 作为应用开发者,你观察现实世界(其中有人、组织、商品、行为、资金流动、传感器等等),并用应用代码中的对象、数据结构以及操作这些数据结构的 API 来对它建模——这些通常是为你这一应用而设计的。
- 当你想存下这些数据结构时,会以一种通用的数据模型来表达:例如 JSON 或 XML 文档、关系型数据库中的表,或图中的顶点与边。这些数据模型就是本章的主题。
- 实现数据库软件的工程师又决定了一种方式,用内存、磁盘或网络上的字节来表示这些文档、关系或图数据。这种表示让数据能以多种方式被查询、搜索、操控与处理。我们将在第 4 章讨论这些存储引擎的设计。
- 在更低层,硬件工程师又琢磨出如何用电流、光脉冲、磁场等等来表示字节。
在复杂应用中,可能还有更多中间层级(例如建立在 API 之上的 API),但基本思想仍然一样:每一层都通过提供一个清晰的数据模型,把它下层的复杂度藏起来。这些抽象让不同人群——例如数据库厂商的工程师与使用其数据库的应用开发者——能高效地协作。
实践中常用的数据模型有几种,分别用于不同目的。某些种类的数据与查询在一种模型里很容易表达,在另一种里却很别扭。本章我们会通过比较关系模型、文档模型、基于图的数据模型、事件溯源与 DataFrame 来探讨这些权衡。我们也会简要看看用以操作这些模型的查询语言。这样的比较将帮你判断何时该用哪种模型。
术语:声明式查询语言
本章讨论的许多查询语言(如 SQL、Cypher、SPARQL 与 Datalog)是声明式的——意思是你只指定结果应当满足的模式:要满足哪些条件、数据要如何被转换(例如排序、分组、聚合)——而不是如何达成这一目标。数据库的查询优化器可以决定使用哪些索引和连接算法,以及以何种顺序执行查询的各个部分。
相对地,对多数编程语言(如 Python 与 Java)来说,你必须写一个算法告诉计算机依次执行哪些操作。声明式查询语言之所以吸引人,是因为它通常比显式算法更简洁、更易写。更重要的是:它隐藏了查询引擎的实现细节,使得数据库系统能在不修改查询的前提下引入性能改进 [1, 2]。
例如,数据库可以并行地在多个 CPU 核心与多台机器上执行一条声明式查询,而无需你操心这种并行如何实现 [3]。如果是手写算法,要自己实现那样的并行执行工作量会非常大。
关系模型 vs 文档模型
今天最为人所熟知的数据模型大概是 SQL;它基于 Edgar Codd 1970 年提出的关系模型 [4]。在该模型中,数据被组织为关系(在 SQL 中称为表,tables),每个关系是一个无序的元组(tuples)集合(在 SQL 中称为行)。
关系模型最初是一项理论上的提议,许多人当时怀疑它能否被高效实现。然而到 1980 年代中期,关系型数据库管理系统(RDBMS)与 SQL 已成为首选工具——对大多数需要存储与查询规则结构数据的人而言。许多数据管理用例——例如商业分析(参见"用于分析的星型与雪花型模式",第 77 页)——几十年后仍由关系模型主导。
时光流转,曾出现许多与之竞争的数据存储与查询方案。1970 年代到 1980 年代初,网状模型与层次模型是主要替代方案,但都被关系模型压倒。对象数据库(不要与今天流行的"用作大文件存储的对象存储"云服务混淆)在 1980 年代末至 1990 年代初出现又消退。XML 数据库出现于 2000 年代初,但采用度有限。每一个挑战者都在自己的时代制造了不少炒作,但没有一个能长久 [5]。SQL 反而吸纳了其他类型的数据——例如增加了对 XML、JSON 与图数据的支持 [6]。
在 2010 年代,NoSQL 是最近一波试图推翻关系型主导地位的潮流。NoSQL 不指代任何单一技术,而是一组围绕新数据模型、模式灵活性、可扩展性以及向开源许可模型靠拢的松散观念。一些数据库把自己冠以 NewSQL 之名,反映出它们旨在提供 NoSQL 系统的可扩展性,同时保留传统关系型数据库的数据模型与事务保证。NoSQL 与 NewSQL 思想对数据系统的设计影响深远,但当其原则被广泛采纳之后,这两个词的使用也逐渐淡化。
NoSQL 运动留下的一项持续影响是*文档模型(document model)*的流行;它通常以 JSON 表示数据。这一模型最初由 MongoDB、Couchbase 等专门的文档数据库推广,尽管如今大多数关系型数据库也已增加了 JSON 支持。与常被视作模式僵硬、不可变的关系表相比,JSON 文档被认为更灵活。
文档数据与关系数据的优劣已被广泛讨论。我们来看这场争论中的几个关键点。
对象-关系阻抗失配
如今许多应用开发使用面向对象编程语言,从而引出了对 SQL 数据模型的一种常见批评:如果数据存在关系表中,应用代码中的对象与数据库的"表-行-列"模型之间需要一层笨拙的转换。两种模型之间的脱节有时被称作阻抗失配(impedance mismatch)。
阻抗失配这个词借自电子学。每个电路在其输入与输出处都有一定的阻抗(对交流的阻力)。当你把一个电路的输出接到另一个电路的输入时,若两电路的输出与输入阻抗匹配,则连接处的功率传输最大化。阻抗不匹配会导致信号反射等问题。
对象-关系映射
ActiveRecord、Hibernate 等对象-关系映射(ORM)框架减少了这种转换层所需的样板代码量,但也常受批评 [7]。常被提到的问题包括:
- ORM 复杂,且无法完全隐藏两种模型之间的差别,因此开发者最终仍要同时考虑数据的关系表示与对象表示。
- ORM 通常只用于 OLTP 应用开发(参见"事务处理与分析处理的特征",第 5 页);让数据可供分析的数据工程师必须直接与底层关系表示打交道,因此即便使用 ORM,关系模式的设计依然重要。
- 许多 ORM 只能配合关系型 OLTP 数据库工作。组织若拥有搜索引擎、图数据库、NoSQL 系统等多样化的数据系统,可能会发现 ORM 支持不足。
- 一些 ORM 会自动生成关系模式,但这些模式可能对直接访问关系数据的用户用起来不便,且在底层数据库上效率可能不高。定制 ORM 的模式与查询生成可能很复杂,反而抵消了使用 ORM 的初衷。
- ORM 让人很容易在不经意间写出低效的查询。一个例子是 N+1 查询问题 [8]。假设你想在页面上显示一个用户评论列表,于是先做一次查询返回 N 条评论,每条都含其作者的 ID。要显示每条评论的作者名,你还得再去 users 表查 ID。手写 SQL 时,你会在查询里做一次连接,让作者名与每条评论一并返回。但用 ORM 时,你可能会对这 N 条评论各自单独查询一次 users 表来取作者,结果一共做 N+1 次数据库查询——这比在数据库里做一次连接慢得多。要避免这个问题,你可能需要告诉 ORM 在取评论的同时把作者信息一并取来。
不过 ORM 也有好处:
- 对于很适合关系模型的数据,持久关系表示与内存对象表示之间总免不了某种转换,ORM 减少了这一转换所需的样板代码。复杂查询仍可能要在 ORM 之外处理,但 ORM 能帮你应付简单与重复的情形。
- 一些 ORM 可以帮助缓存数据库查询结果,从而减少数据库负载。
- ORM 也能帮助管理模式迁移与其他管理工作。
文档数据模型用于一对多关系
并非所有数据都适合用关系来表示。我们来看一个例子,借此探讨关系模型的一项局限。图 3-1 展示了如何用关系模式表达一份简历(如 LinkedIn 资料)。整份资料可由唯一标识符 user_id 标识。first_name 与 last_name 这类字段每位用户恰好对应一个值,因而可以建模为 users 表中的列。
大多数人在职业生涯中担任过不止一份工作(职位),可能也有若干段教育经历以及多种联系方式。表示这种一对多关系的一种方式,是把职位、教育与联系信息分别放进独立的表中,每张表都通过外键引用 users 表,如图 3-1 所示。
另一种表达同样信息的方式——也许更自然,且与应用代码中的对象结构更接近——是采用 JSON 文档,如示例 3-1。
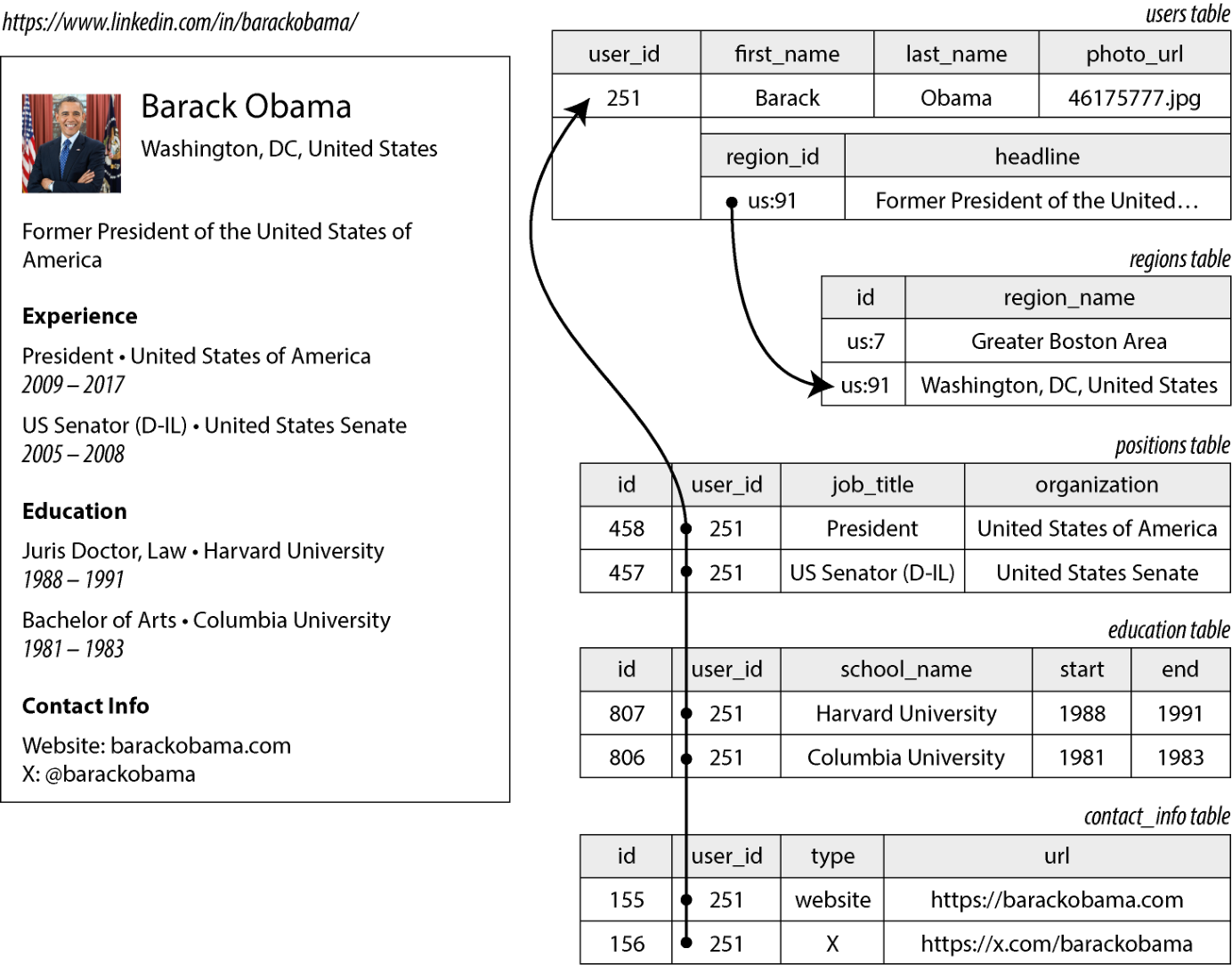
图 3-1. 使用关系模式表示一份 LinkedIn 资料
图示文字描述: 图示 LinkedIn 页面"Barack Obama, Washington, DC, United States, Former President of the United States of America";其右侧用关系模式表示:users 表(user_id=251、first_name=Barack、last_name=Obama、photo_url=46175777.jpg、region_id=us:91、headline=Former President...),regions 表(id us:7→Greater Boston Area;us:91→Washington, DC, United States),positions 表(id 458, user_id 251, job_title=President, organization=United States of America;id 457, user_id 251, job_title=US Senator (D-IL), organization=United States Senate),education 表(id 807, user_id 251, school_name=Harvard University, start=1988, end=1991;id 806, user_id 251, school_name=Columbia University, start=1981, end=1983),contact_info 表(id 155, user_id 251, type=website, url=https://barackobama.com;id 156, user_id 251, type=X, url=https://x.com/barackobama)。
示例 3-1. 把一份 LinkedIn 资料表示为 JSON 文档
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"headline": "Former President of the United States of America",
"region_id": "us:91",
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "President", "organization": "United States of America"},
{"job_title": "US Senator (D-IL)", "organization": "United States Senate"}
],
"education": [
{"school_name": "Harvard University", "start": 1988, "end": 1991},
{"school_name": "Columbia University", "start": 1981, "end": 1983}
],
"contact_info": {
"website": "https://barackobama.com",
"x": "https://x.com/barackobama"
}
}一些开发者认为,JSON 模型缩小了应用代码与存储层之间的阻抗失配。"无模式"也常被列为一项优势;我们将在"文档模型中的模式灵活性"(第 80 页)中讨论这一点。然而正如第 5 章会看到的,把 JSON 当作数据编码格式也并非没有问题。
JSON 表示的*局部性(locality)*优于图 3-1 的多表模式(参见"读写的数据局部性",第 82 页)。如果你想取一份资料,在关系示例里要么得做多次查询(按 user_id 查每张表),要么得在 users 表与其下属表之间做一次零碎的多路连接 [9, 10]。在 JSON 表示里,所有相关信息都在一个地方,查询既更快也更简单。
从用户资料到职位、教育历程与联系信息的一对多关系隐含着数据中的树状结构,JSON 表示让这种树状结构显式可见(如图 3-2)。
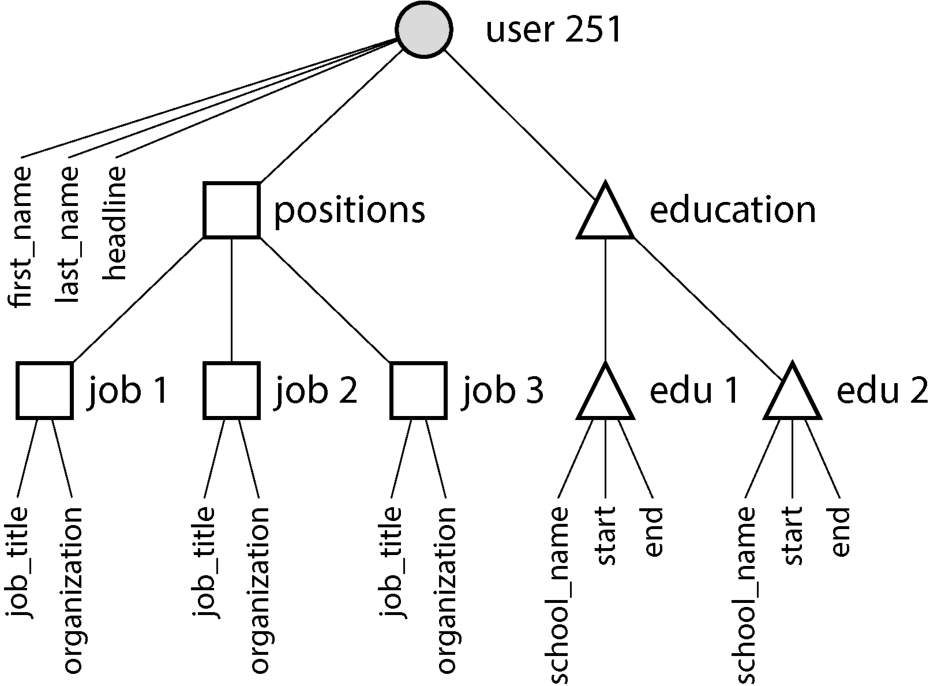
图 3-2. 一对多关系构成的树状结构
图示文字描述: 图示根节点 user 251 携带 first_name、last_name、headline;下挂 positions 与 education 两个分支:positions 下三个 job 节点(job 1/2/3),各含 job_title、organization;education 下两个 edu 节点(edu 1/2),各含 school_name、start、end。
一对多关系有时也叫一对少(one-to-few)——因为简历通常只有少量职位 [11, 12]。如果你确实有大量相关条目(比如某名人社媒帖子下成千上万条评论),把它们全部嵌入同一份文档可能太笨重,反倒是图 3-1 那种关系做法更可取。
规范化、反规范化与连接
在前一节的示例 3-1 中,region_id 是以 ID 形式给出的,而不是直接以纯文本字符串 Washington, DC, United States 存放。为什么?
如果 UI 中的"地区"是一个自由文本字段,把它存成纯字符串就行。但准备一份标准化的地理区域列表、让用户从下拉框或自动补全里选择,有以下几个好处:
- 各份资料之间风格与拼写一致
- 避免歧义(若多个地方同名怎么办?例如仅"Washington, DC",是指华盛顿特区还是华盛顿州?)
- 易于更新——名字只存一处,所有引用处一改即改(例如因政治事件而改城市名)
- 支持国际化——网站翻译为其他语言时,标准化列表也可被本地化,从而以查看者的语言显示地区
- 更好的搜索功能(例如搜索"美国东海岸的人"可匹配此资料,因为地区列表里能编码出"华盛顿位于东海岸"这一事实——而仅看"Washington, DC"这串字符是看不出来的)
存 ID 还是存文本字符串,是*规范化(normalization)的问题。使用 ID 时,数据更规范化:对人有意义的信息(如文本"华盛顿特区")只存一处,所有引用它的地方都用 ID(这个 ID 仅在数据库内部有意义)。直接存文本时,则会在使用它的每条记录里都复制一份对人有意义的信息;这种表示是反规范化(denormalized)*的。
使用 ID 的好处是:因为它对人没有意义,便永远不需要变——即便它所标识的信息变了,ID 也可保持不变。任何对人有意义的东西将来都可能改变;如果该信息被复制了,所有冗余副本都需要更新。这需要更多代码、更多写入操作、更多磁盘空间,并且有出现不一致(部分副本被更新而其他没有)的风险。
规范化表示的代价是:每次想显示一条含有 ID 的记录时,必须再做一次查找,把这个 ID 解析为人能看懂的内容。在关系模型中,这通常用*连接(join)*完成。例如:
SELECT users.*, regions.region_name
FROM users
JOIN regions ON users.region_id = regions.id
WHERE users.id = 251;文档型数据库可以同时存放规范化与反规范化的数据,但它们常常与反规范化挂钩——一方面 JSON 数据模型让"再加一些反规范化字段"变得很容易;另一方面许多文档数据库对连接支持较弱,让规范化用起来不便。一些文档数据库根本不支持连接,所以必须在应用代码里做——也就是先取一份含有 ID 的文档,再做第二次查询把那个 ID 解析成另一份文档。在 MongoDB 中,也可以用聚合管道里的 $lookup 算子做连接:
db.users.aggregate([
{ $match: { _id: 251 } },
{ $lookup: {
from: "regions",
localField: "region_id",
foreignField: "_id",
as: "region"
} }
])规范化的取舍
在简历这个例子里,region_id 字段引用了一组标准化的地区,但 organization(此人工作过的公司或政府)与 school_name(其就读的学校)只是字符串。这种表示是反规范化的:很多人可能在同一家公司工作过,但没有 ID 把它们关联起来。
值得考虑的是:把组织与学校也设为实体,并通过 ID 引用它们,是不是更好?前面引用 region ID 的那些理由,同样适用于此处。例如,假设我们除名称外,还想显示学校或公司的徽标:
- 在反规范化表示中,我们会把徽标的图片 URL 放在每个人的资料里。一旦徽标改了,就很麻烦——得找到旧 URL 出现的所有位置并逐一更新 [11]。
- 在规范化表示中,我们会创建一个表示组织或学校的实体,把名字、徽标 URL 以及(可能还有)描述、动态等其他属性作为该实体的一部分只存一次。每份提及该组织的简历则只引用其 ID,更新徽标也就很容易。
作为一般原则:规范化数据写入通常更快(只需更新一份副本),但查询更慢(需要连接);反规范化数据读取通常更快(连接更少),但写入更贵(更多副本要更新,占用更多磁盘空间)。把反规范化看作派生数据的一种形式或许有助于理解(参见"真实数据源与派生数据",第 10 页):你需要为更新冗余副本建立一套流程。
除了执行这些更新的成本之外,你还要考虑:当某个进程在更新到一半时崩溃,数据库的一致性会怎样?提供原子事务(参见"原子性",第 280 页)的数据库让保持一致更容易做到,但并非所有数据库都跨多份文档提供原子性。也可以通过流处理来确保一致性,第 12 章会讨论。
规范化往往对 OLTP 系统更合适——读写都需要快;而分析系统通常用反规范化数据效果更好,因为它们以批量方式做更新,且只读查询的性能是首要关注点。在中小规模系统中,规范化的数据模型通常是最佳选择——你不必担心保持多份副本一致,连接的代价也可接受。然而在非常大规模的系统中,连接的代价可能成为问题。
社交网络案例研究中的反规范化
在"案例研究:社交网络主页时间线"(第 34 页)中,我们比较了规范化表示(图 2-1)与反规范化表示(预先计算的物化时间线)。在那里 posts 与 follows 之间的连接代价过高,物化时间线则是该连接结果的缓存。把新帖插入关注者时间线的扇出过程,正是我们用来保持反规范化表示一致的手段。
然而 X(前身 Twitter)上物化时间线的实现并不存放每条帖子的实际文本。每个条目只存帖子 ID、发帖人 ID 和少量用以识别"转发"和"回复"的额外信息 [13]。换言之,它大致是下面这条查询的预先计算结果:
SELECT posts.id, posts.sender_id FROM posts
JOIN follows ON posts.sender_id = follows.followee_id
WHERE follows.follower_id = current_user
ORDER BY posts.timestamp DESC
LIMIT 1000这意味着每次读取时间线时,服务仍然需要做两次连接:根据帖子 ID 取实际帖子内容(以及点赞数、评论数等统计),并按 ID 取发帖人资料(以拿到用户名、头像等细节)。这种"按 ID 查找人能看懂的信息"的过程称为水合(hydrating) IDs,本质上就是在应用代码里做的连接 [13]。
只在预计算时间线里存 ID 的原因,是它所引用的数据变化很快。一条热门帖子的点赞数与回复数可能每秒变化多次,部分用户也会偶尔改用户名或头像。既然时间线被读取时应当显示最新的点赞数与头像,那把这些信息反规范化进物化时间线就没有意义了。况且这种反规范化还会显著增加存储成本。
这个例子表明:必须做连接才能读出数据,并不像有时人们说的那样,是构建高性能、可扩展服务的障碍。水合 post 与 user 的 ID 实际上相当容易扩展,因为它并行性好,且代价并不取决于你关注了多少账户或有多少粉丝。
如果你需要在自己的应用中决定是否反规范化,社交网络案例研究表明这个选择并非显而易见;最具可扩展性的做法可能是把某些数据反规范化,让另一些保持规范化。你必须仔细考量信息变化的频率,以及读写的成本(这些成本可能被离群值主导——例如典型社交网络中关注者/粉丝众多的用户)。规范化与反规范化本身并无绝对好坏,二者只是在读写性能与实现工作量上的取舍。
多对一与多对多关系
图 3-1 中的 positions 与 education 表是一对多或一对少关系的例子(一份简历有若干职位,但每个职位仅属于一份简历),而 region_id 字段则是多对一关系的例子(许多人住在同一地区,但我们假定一个人某时刻只住在一个地区)。
如果我们为组织与学校引入实体,并在简历中按 ID 引用它们,便也有了多对多关系(一个人可能在若干组织工作过,一个组织也有若干过去或现在的雇员)。在关系模型里,这种关系通常用关联表或*连接表(associative/join table)*来表示,如图 3-3 所示:每个职位把一个用户 ID 与一个组织 ID 关联起来。
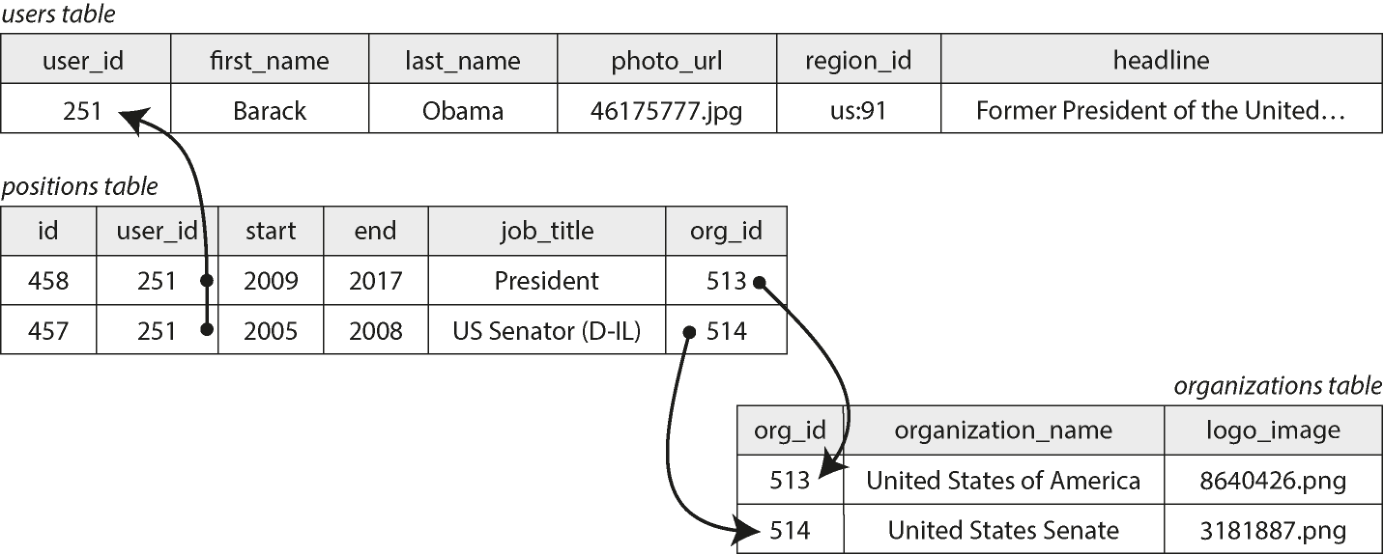
图 3-3. 关系模型中的多对多关系
图示文字描述: 图示 users 表(user_id 251, Barack Obama, photo_url, region_id us:91, headline...);positions 表新增 org_id 列:(id 458, user_id 251, start 2009, end 2017, job_title President, org_id 513)(id 457, user_id 251, start 2005, end 2008, job_title US Senator (D-IL), org_id 514);右下 organizations 表(org_id 513 United States of America 8640426.png;org_id 514 United States Senate 3181887.png)。
多对一与多对多关系不容易纳入一份自包含的 JSON 文档;它们更适合规范化的表示。文档模型中的一种做法见示例 3-2 并由图 3-4 演示:每个虚线矩形内的数据可以合并为一份文档,但到组织与学校的链接最好用对其他文档的引用来表达。
示例 3-2. 一份按 ID 引用组织的简历
{
"user_id": 251,
"first_name": "Barack",
"last_name": "Obama",
"positions": [
{"start": 2009, "end": 2017, "job_title": "President", "org_id": 513},
{"start": 2005, "end": 2008, "job_title": "US Senator (D-IL)", "org_id": 514}
],
...
}多对多关系常需要从"两个方向"查询——例如,既要找出某人工作过的所有组织,也要找出在某组织工作过的所有人。实现这种查询的一种方式是双向存 ID:简历里包含此人工作过的每个组织的 ID,组织文档里则包含所有提及该组织的简历的 ID。这种表示是反规范化的,因为关系被存在两处,可能彼此不一致。
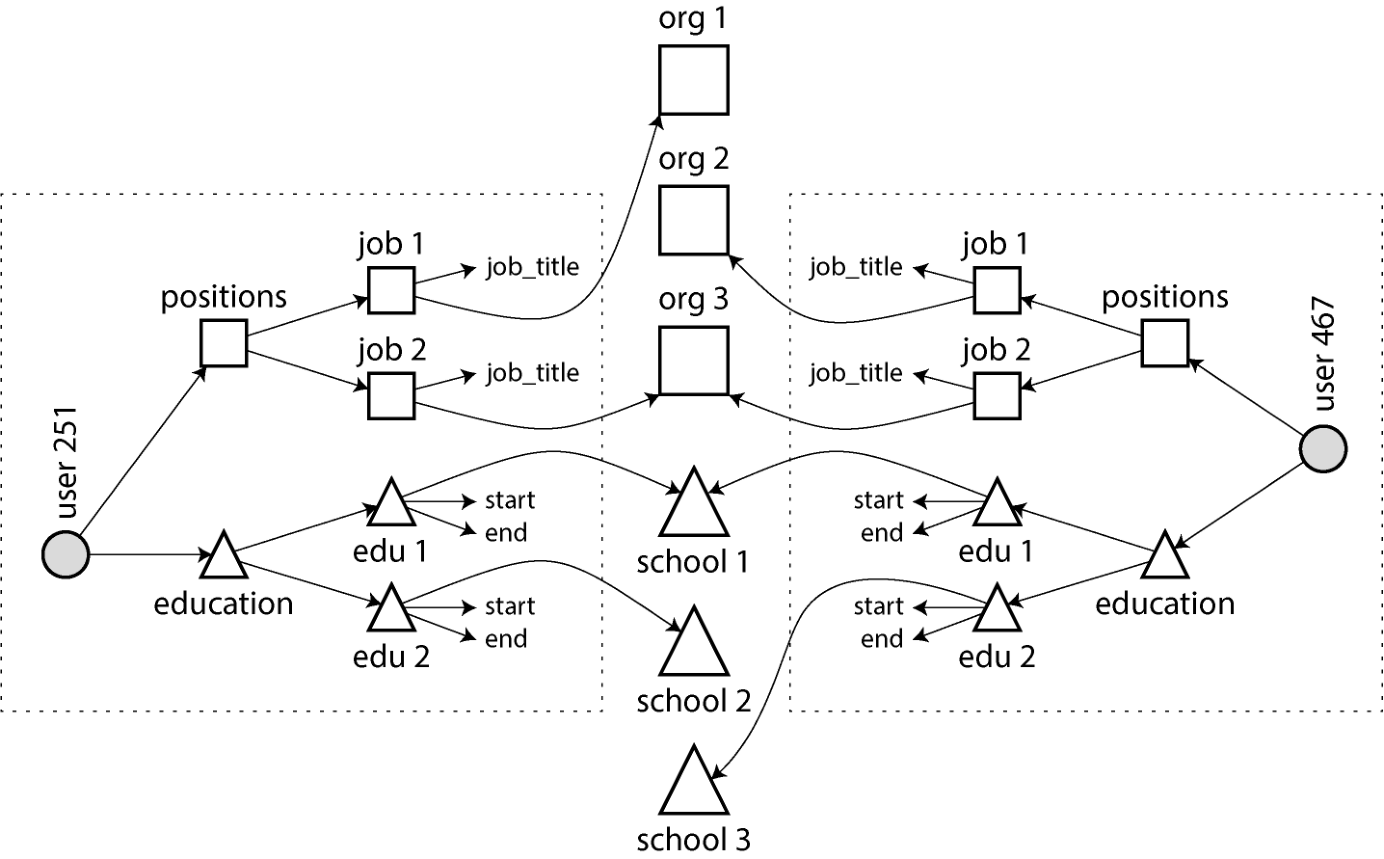
图 3-4. 文档模型中的多对多关系——每个虚线框内的数据可合并为一份文档
图示文字描述: 图示左侧 user 251 文档框内含 positions(含 job 1/2,每个 job 关联 org_id),education(edu 1/2,每个 edu 关联 school_name);中部独立的 org 1/2/3 与 school 1/2/3 文档框由箭头连入两侧 user 文档;右侧 user 467 框内同样含 positions(job 1/2)与 education(edu 1)。
规范化的表示只把关系存在一处,依靠*二级索引(secondary indexes,第 4 章讨论)*让该关系能在两个方向上被高效查询。在图 3-3 的关系模式中,我们会让数据库为 positions 表的 user_id 与 org_id 两列都建索引。
在示例 3-2 的文档模型中,数据库需要为 positions 数组里对象的 org_id 字段建索引。许多文档数据库以及带有 JSON 支持的关系数据库都可以在文档内部的值上建立这样的索引。
用于分析的星型与雪花型模式
数据仓库(参见"数据仓库",第 7 页)通常是关系型的,业内也有几种被广泛使用的仓库表结构约定,包括星型模式、雪花模式、维度建模 [14] 与"一张大表(OBT)"。这些结构都针对业务分析师的需求做了优化。ETL 流程把数据从运营系统转换到所选模式。
图 3-5 演示了某零售商数据仓库中可能见到的星型模式。模式中央是事实表(fact table)(这里叫 fact_sales)。事实表的每一行表示某一时刻发生的事件(这里每行表示一名顾客购买一件商品)。如果我们分析的是网站流量而非零售销售,每行可能表示一次用户的页面浏览或点击。
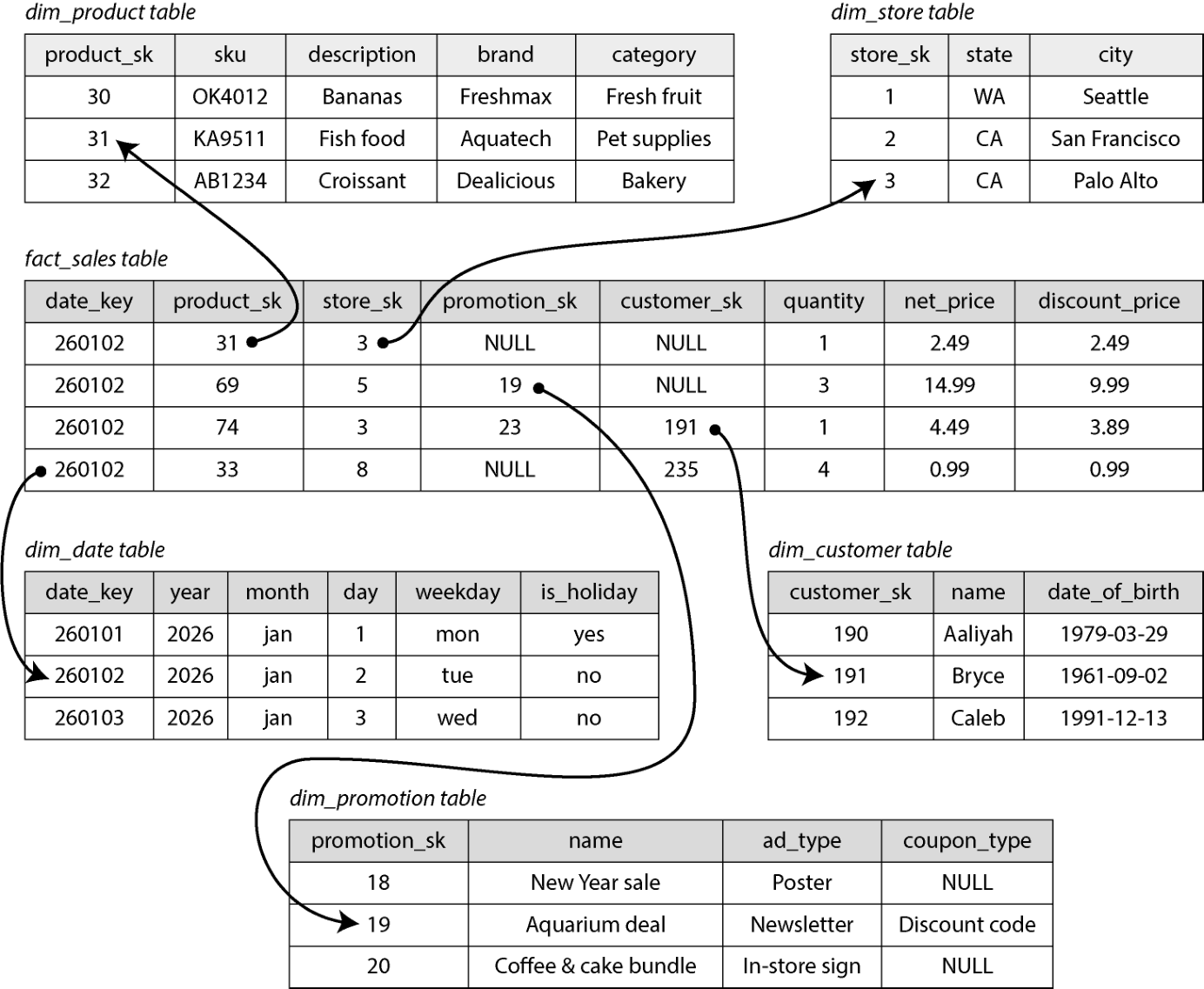
图 3-5. 用于数据仓库的星型模式
图示文字描述: 图示中部 fact_sales 表(date_key、product_sk、store_sk、promotion_sk、customer_sk、quantity、net_price、discount_price),事实表四周环绕维度表:dim_product(product_sk、sku、description、brand、category)、dim_store(store_sk、state、city)、dim_date(date_key、year、month、day、weekday、is_holiday)、dim_customer(customer_sk、name、date_of_birth)、dim_promotion(promotion_sk、name、ad_type、coupon_type)。事实表中各 _sk 字段以箭头连向各维度表对应行。
事实通常以单条事件的形式被记录下来,因为这为后续分析带来最大的灵活性。这意味着事实表会非常大:一个大型企业的数据仓库里可能有许多 PB 的交易历史,绝大多数都以事实表的形式存放。
事实表中的某些列是属性,例如商品的售价、向供应商进货的成本(用以计算毛利)。其余列则是指向其他表(称为维度表,dimension tables)的外键。由于事实表中的每行都表示一次事件,维度便表示了事件的 who、what、where、when、how、why。
例如在图 3-5 中,其中一个维度是"所售商品"。dim_product 表的每行表示一种在售商品,包含其 SKU、描述、品牌名、品类、脂肪含量、包装尺寸等。fact_sales 表的每行通过一个外键指出此次交易里卖了哪种商品。查询中常涉及对多个维度表的多次连接。
甚至日期与时间也常用维度表来表示,因为这样可以在日期上编码额外信息(如公共假日),让查询能区分节假日与非节假日的销售。
"星型模式"得名是因为:当把表关系画出来时,事实表在中央,被维度表环绕(如图 3-5);它连向各表的连线就像星星射出的光。
这一模板的一个变体是雪花模式,其中维度被进一步拆分为子维度。例如品牌与品类可以各自有独立的表,dim_product 表中的每行将品牌与品类作为外键引用,而不是把它们作为字符串存进 dim_product。雪花模式比星型模式更规范化,但分析师常更偏爱星型模式,因为它对分析师更简单 [14]。
在典型的数据仓库里,表常常很宽:事实表常有过百列,有时甚至几百列。维度表也可能很宽,因为它们包含一切可能与分析相关的元数据——例如 dim_store 表可能含每家店是否提供烘焙、店面平方英尺数、店首次开业日期、上次重装日期、距最近高速公路距离等细节。
星型或雪花模式主要由多对一关系组成(例如多次销售关联到同一具体商品、同一具体门店),表现为事实表持有指向维度表的外键、维度持有指向子维度的外键。原则上其他类型的关系也可能存在,但常被反规范化以简化查询。例如,若一个客户一次购买若干件不同商品,这次多商品交易并不会被显式表示——而是事实表中每件所购商品各占一行,这些行的 customer ID、store ID 与 timestamp 恰好相同。
某些数据仓库模式更进一步反规范化,索性不要维度表,把维度信息折叠进反规范化的事实表列中(本质上是把事实表与维度表的连接预先算好)。这种做法称为"一张大表(OBT)";虽然它要消耗更多存储空间,但有时能让查询更快 [15]。
在分析的语境下,这种反规范化没什么问题,因为数据通常是不会变的历史日志(除非偶尔做错误修正)。OLTP 系统中由反规范化引发的数据一致性与写入开销问题,在分析里也没那么紧迫。
何时使用哪种模型
支持文档数据模型的主要论点是:模式灵活、由于局部性带来更好的性能,且对某些应用而言更贴近应用所使用的对象模型。与之相对,关系模型则为连接、多对一与多对多关系提供了更好的支持。下面进一步细看这些理由。
如果你应用中的数据具有类文档结构(即一对多关系的树状数据,通常一次性整树加载),那么用文档模型大概是个好主意。把类文档结构*碎裂(shredding)*到多张表(如图 3-1 中的 positions、education、contact_info)的关系做法可能带来繁琐的模式与不必要的复杂应用代码。
文档模型也有其局限。例如你不能直接引用文档内嵌的项目;你需要说"用户 251 的职位列表里的第二项"。如果你需要引用嵌套项目,关系做法更合适——因为你可以直接用其 ID 引用任何项目。
某些应用允许用户自行选择项目顺序——例如待办列表或缺陷追踪器,用户可以拖放任务以重新排序。文档模型对这类应用支持良好——因为项目(或其 ID)只要存进 JSON 数组就能决定顺序。在关系数据库里,没有标准方式来表示这种可重排序的列表,常用的几种技巧有:用整数列排序(往中间插入时需要重新编号)、维护 ID 的链表、使用分数索引 [16, 17, 18]。
文档模型中的模式灵活性
大多数文档数据库与关系数据库中的 JSON 支持都不会强制对文档中的数据施加任何模式。关系数据库中的 XML 支持通常带有可选的模式校验。"无模式"意味着任意键值都可以被加入文档,读取时客户端无法保证文档里会有哪些字段。
文档数据库有时被称为"无模式(schemaless)",但这种说法有些误导:因为读取数据的代码通常会假定数据具有某种结构——也即存在一个隐式的模式,只是数据库不去强制它。更准确的术语是读时模式(schema-on-read)(数据结构是隐式的,仅在读取时被解释),与之相对的是关系数据库的传统做法写时模式(schema-on-write)(模式是显式的,数据库在写入时确保所有数据都符合该模式)[20]。
读时模式类似于编程语言里的动态(运行时)类型检查,写时模式则类似于静态(编译时)类型检查。正如静态与动态类型检查的拥护者就两者优劣争论不休 [21],数据库是否强制模式也是争议话题,总体上没有清晰的赢家。
两种做法的差异在应用想改变数据格式时尤为明显。例如,假设你目前把每位用户的全名存在一个字段中,现在想分开存名与姓 [22]。在文档数据库里,你只要开始用新字段写新文档,并在应用里加代码处理读到的旧文档即可:
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2023 don't have first_name
user.first_name = user.name.split(" ")[0];
}这种做法的代价是:应用中所有从数据库读取的部分,都得能应付那些以旧格式写入、已经存在很久的文档。在写时模式的数据库里,你通常会做下面这样的迁移:
ALTER TABLE users ADD COLUMN first_name text DEFAULT NULL;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL在多数关系数据库里,加一列、默认值为空这件事很快、不会出问题,即便在大表上也是如此。然而 UPDATE 语句在大表上很可能慢——因为每行都要重写;其他模式操作(例如改一列的数据类型)通常也需复制整张表。
已有多种工具可以在后台执行此类模式更改、不必停机 [23, 24, 25, 26],但在大数据库上做这种迁移在运维上仍颇具挑战。复杂的迁移可以借助"以默认 NULL 加 first_name 列(很快),并在读时按需填值"的做法来避开——这正是你在文档数据库里会做的。
如果集合中各项的结构并不一致(即数据是异构的),读时模式更具优势;例如:
- 对象类型很多,把每种类型放进自己的表并不可行。
- 数据结构由你无法控制的外部系统决定,且可能随时变化。
在这类情形下,模式可能有害无益,无模式文档可能是更自然的数据模型。但当我们期望所有记录都具有相同结构时,模式仍然是用来记录并强制该结构的有用机制。我们会在第 5 章更详细地讨论模式与模式演进。
读写的数据局部性
文档通常以 JSON、XML 或它们的二进制变体(如 MongoDB 的 BSON)编码,作为单一连续字符串存储。如果你的应用经常需要访问整份文档(例如把它渲染到网页上),这种存储局部性能带来性能优势。如果数据像图 3-1 那样被分散到多张表,要把它全部取出来就需要多次索引查找,这可能要更多磁盘寻址,更耗时。
局部性的优势只有在你需要同时使用文档大部分内容时才适用。数据库通常需要把整份文档加载进来,如果你只需访问一份大文档的一小块,这就过于浪费了。此外,更新一份文档时通常要把整份文档重写。出于这些原因,一般建议把文档保持较小,并避免频繁的小幅更新。
不过,把相关数据放在一起以获得局部性并不限于文档模型。例如 Google Spanner 数据库在关系数据模型中也提供了同样的局部性特性——它允许模式声明把某张表的行嵌入(嵌套)到一个父表内 [27]。Oracle 也允许同样的做法,使用一项称为多表索引簇表(multi-table index cluster tables)的特性 [28]。Google Bigtable 所推广、并被 HBase 和 Accumulo 使用的宽列(wide-column)数据模型有列族(column families),目的也类似——管理局部性 [29]。
文档查询语言
关系数据库与文档数据库的另一个差异是用于查询的语言或 API。多数关系数据库用 SQL 查询,文档数据库的情况则更为分散。一些只允许按主键的键值访问,有些也提供二级索引来按文档内的值查询,还有一些提供丰富的查询语言。
XML 数据库常用 XQuery 和 XPath 查询,二者旨在支持复杂查询,包括跨多份文档的连接,并把结果格式化为 XML [30]。JSON Pointer [31] 与 JSONPath [32] 为 JSON 提供了 XPath 的对应物。MongoDB 的聚合管道(其用于连接的 $lookup 算子已在"规范化、反规范化与连接",第 72 页中见过)便是 JSON 文档集合上的一种查询语言示例。
我们再看一个例子来感受这种语言——这次做一次聚合(在分析中尤为常见)。设想你是海洋生物学家,每次在海中看到动物就往数据库里添加一条观察记录。现在你想生成一份报告,列出每月发现的鲨鱼数量。在 PostgreSQL 中,你可能这样表达:
SELECT date_trunc('month', observation_timestamp) AS observation_month, -- ❶
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;❶ date_trunc('month', observation_timestamp) 函数确定包含 timestamp 的日历月份,并返回另一个表示该月之始的时间戳。换句话说,该函数把时间戳向下截断到最近的月份。
这条查询先把 observations 过滤为只属于 Sharks 科的物种,再按发生的日历月份分组,最后把当月所有观察记录中的动物数加起来。同样的查询用 MongoDB 的聚合管道可表达为:
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
} }
]);聚合管道语言在表达力上类似于 SQL 的一个子集,但使用 JSON 风格的语法而非 SQL 的英文句式语法。这种差异也许仅是口味问题。
文档库与关系库的融合
文档数据库与关系数据库起初是处理数据的两种迥异方式,但随着时间推移它们越来越相似 [33]。关系数据库添加了对 JSON 类型与查询算子的支持,并能为文档内属性建立索引。一些文档数据库(如 MongoDB、Couchbase 与 RethinkDB)也加入了对连接、二级索引与声明式查询语言的支持。
模型的这种融合对应用开发者来说是好消息——因为关系模型与文档模型在能于同一数据库中结合使用时表现最好。许多文档数据库都需要对其他文档做关系式引用,许多关系数据库也有受益于模式灵活性的场合。关系-文档混合是一种强大的组合。
Codd 对关系模型的最初描述 [4] 允许在关系模式内出现类似 JSON 的结构。他称之为非简单域(nonsimple domains)。其想法是:行中的某个值未必非得是数字或字符串这类原始数据类型;它也可以是嵌套的关系(表),所以你可以把任意嵌套的树结构作为值。这种构造与 30 多年后才被加入 SQL 的 JSON、XML 支持颇为相似。
类图数据模型
我们前面看到,关系的类型是区分数据模型的一个重要维度。如果你应用中的关系大多是一对多(树状数据),且记录之间没有太多其他关系,文档模型就很合适。
但若你的数据里多对多关系非常普遍呢?关系模型可以处理简单的多对多关系,但当数据内部的连接变得更复杂时,把数据建模为图就更自然了。
一个图由两类对象组成:顶点(vertices)——也称节点或实体——和边(edges)——也称关系或弧。许多种数据都能被建模为图,典型例子包括:
社交图 :顶点是人,边表示彼此认识。
Web 图 :顶点是网页,边表示指向其他页面的 HTML 链接。
公路或铁路网络 :顶点是路口,边表示路口之间的道路或铁路线。
著名算法可在这些图上运行——例如地图导航 App 在公路网中搜索两点间最短路径,PageRank 可用于 Web 图以判定网页流行度并据此排序搜索结果 [34]。
图可以用几种方式表示。在邻接表(adjacency list)模型中,每个顶点存放其一条边可达的邻居顶点的 ID。或者你也可以用邻接矩阵(adjacency matrix)——一个二维数组,其中每行每列各对应一个顶点,行顶点与列顶点之间无边时取值为 0,有边时取值为 1。邻接表适合图遍历,矩阵适合机器学习(参见"DataFrame、矩阵与数组",第 105 页)。
在上述例子中,图中所有顶点都代表同类对象(分别是人、网页、路口)。然而图并不限于这种*同质(homogeneous)*数据。图的另一种同样强大的用法是:在同一个数据库中为各种完全不同的对象提供一种一致的存储方式。例如:
- Facebook 维护着一张包含多种顶点与边的图。顶点表示人、地点、事件、签到与用户的评论;边表示哪些人是好友、谁在哪里签到、谁评论了哪条帖子、谁参加了哪个活动等等 [35]。
- 搜索引擎用知识图谱来记录搜索查询中常出现的实体(如组织、人与地点)的相关事实 [36]。这些信息通过爬取并分析网站的文本得到;某些网站(如 Wikidata)也以结构化形式发布图数据。
图为构建与查询数据提供了几种不同但相关的方式。本节我们将讨论*属性图(property graph)模型(由 Neo4j、Memgraph、KùzuDB [37] 等实现 [38])与三元组存储(triple store)*模型(由 Datomic、AllegroGraph、Blazegraph 等实现)。这两种模型在表达力上颇为相近,一些图数据库(如 Amazon Neptune)同时支持两者。
我们还会看四种图查询语言(Cypher、SPARQL、Datalog 与 GraphQL),以及用 SQL 查询图。还有别的图查询语言,如 Gremlin [39],但以上几种已能给出有代表性的概览。
为演示这些语言与模型,本节用图 3-6 作为贯穿全节的示例。它可以取自社交网络或家谱数据库;图中显示两个人:来自 Idaho 的 Lucy 与来自法国 Saint-Lô 的 Alain。他们已婚并住在 London。每个人与每个地点都用一个顶点表示,他们之间的关系用边表示。这个例子能演示一些在图数据库里轻而易举、在其他数据模型里却很困难的查询。
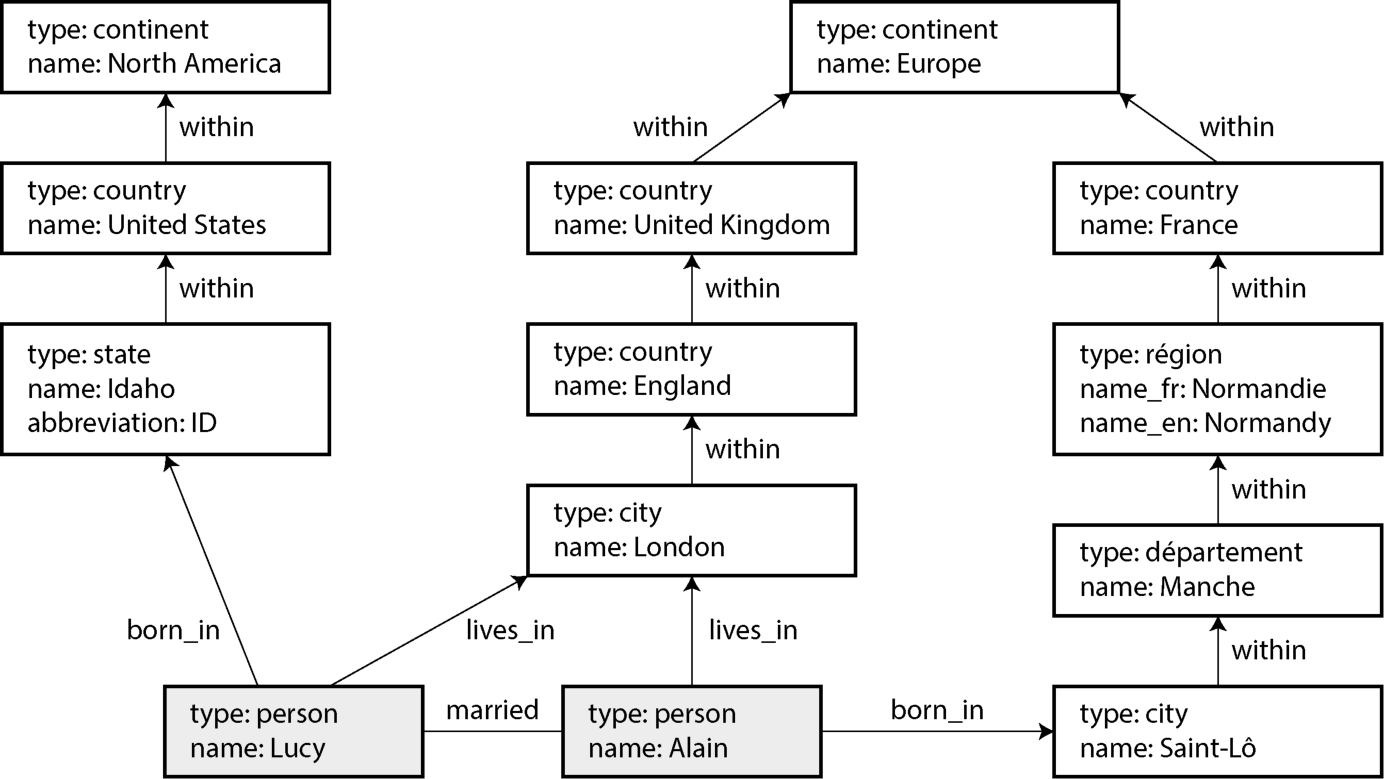
图 3-6. 图结构数据(方框表示顶点,箭头表示边)
图示文字描述: 图示中每个 type/name 标签都是一个矩形顶点。地理顶点:North America(continent) ↑ United States(country) ↑ Idaho(state);Europe(continent) ↑ United Kingdom(country) ↑ England ↑ London(city);Europe ↑ France(country) ↑ région: Normandie/Normandy ↑ département: Manche ↑ city: Saint-Lô。两个 person 顶点:Lucy 与 Alain。边:Lucy --born_in→ Idaho;Lucy --lives_in→ London;Lucy --married→ Alain;Alain --lives_in→ London;Alain --born_in→ Saint-Lô;地理之间的 within 边构成层次。
属性图
在属性图(也称带标签的属性图)模型中,每个顶点由以下部分组成:
- 一个唯一标识符
- 一个标签(字符串),描述此顶点表示的对象类型
- 一组出边
- 一组入边
- 一组属性(键值对)
每条边由以下部分组成:
- 一个唯一标识符
- 边起始的顶点(尾顶点,tail vertex)
- 边终止的顶点(头顶点,head vertex)
- 一个标签,描述两顶点间的关系类型
- 一组属性(键值对)
可以把图存储看成由两张关系表构成:一张顶点表、一张边表,如示例 3-3 所示(该模式使用 PostgreSQL 的 jsonb 数据类型来存放每个顶点或边的属性)。每条边都记录了头顶点与尾顶点;如果你想取某顶点的入边或出边集合,可以分别按 head_vertex 或 tail_vertex 查询 edges 表。
示例 3-3. 用关系模式表示一个属性图
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
label text,
properties jsonb
);
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFERENCES vertices (vertex_id),
label text,
properties jsonb
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);这一模型有几个重要方面:
- 任何顶点都可以有边连向任何其他顶点。不存在某种模式来限定哪些种类的事物可以或不可以被关联起来。
- 给定任意顶点,你可以高效地找到它的入边与出边,从而在图中遍历——即沿一连串顶点形成的路径前后行进。(这正是示例 3-3 在
tail_vertex与head_vertex上都有索引的原因。) - 通过对不同种类的顶点与关系使用不同的标签,你可以在同一张图中存放多种信息,同时仍能保持数据模型的清晰。
edges 表就像我们在"多对一与多对多关系"(第 75 页)中见到的多对多关联表(join table),只是经过推广,可以把多种类型的关系都存放在同一张表里。也可以在标签与属性上建索引,以便高效地按属性找到具有特定属性的顶点或边。
图模型的一个限制是:一条边只能关联两个顶点,而关系型连接表可通过在一行内使用多个外键引用,表示三向乃至更高阶的关系。要在图中表示这种关系,可以这样做:为连接表中的每行新建一个对应的顶点,并连入/连出该顶点;或使用超图(hypergraph)。
这些特性赋予图极大的数据建模灵活性,如图 3-6 所示。该图演示了几件事:传统关系模式难以表达的内容(比如不同国家的不同区域结构——法国有 départements 与 régions,美国有 counties 与 states);某些历史上的奇怪情形(一个国家在另一个国家"内部"——这里我们暂且忽略主权国家与民族的复杂性);以及粒度差异(Lucy 的现住地精确到城市,而出生地仅精确到州)。
你可以想象进一步扩展该图,加入许多关于 Lucy、Alain 或其他人的事实。例如可用图来表示他们的任何食物过敏(为每种过敏原引入一个顶点,并在人与过敏原之间用边表示一种过敏关系),并把过敏原与一组表示哪些食物含哪些物质的顶点连起来。然后你就能写一个查询,找出每个人能安全食用的食物。图对可演化性十分友好:随着你给应用增加新功能,图可以方便地扩展以容纳应用数据结构的变化。
Cypher 查询语言
Cypher 是一种属性图查询语言,最初为 Neo4j 图数据库而创建,后来发展为一项开放标准——openCypher [40]。除 Neo4j 外,Memgraph、KùzuDB [37]、Amazon Neptune、Apache AGE(在 PostgreSQL 上提供存储)等也都支持 Cypher。这门语言的名字源自电影《黑客帝国》中的一个角色,与密码学中的 cipher 无关 [41]。
示例 3-4 展示了如何用 Cypher 把图 3-6 左侧的部分插入图数据库;其余部分可以照样添加。每个顶点都会被赋予一个符号名(如 usa 或 idaho)。这些名字并不会存进数据库,仅在查询内部用于创建顶点之间的边——使用箭头记法:(idaho) -[:WITHIN]-> (usa) 创建一条标签为 WITHIN 的边,尾节点为 idaho,头节点为 usa。
示例 3-4. 把图 3-6 中部分数据用 Cypher 表达
CREATE
(namerica :Location {name:'North America', type:'continent'}),
(usa :Location {name:'United States', type:'country' }),
(idaho :Location {name:'Idaho', type:'state' }),
(lucy :Person {name:'Lucy' }),
(idaho) -[:WITHIN ]-> (usa) -[:WITHIN]-> (namerica),
(lucy) -[:BORN_IN]-> (idaho)当图 3-6 的所有顶点与边都加进数据库后,我们就能问一些有趣的问题。例如,假设我们想找出"出生在美国但移居到欧洲的所有人"的姓名。我们可以这样做:找出所有这样的顶点——它有一条 BORN_IN 边连向位于美国某地的位置,又有一条 LIVES_IN 边连向位于欧洲某地的位置——并返回这些顶点的 name 属性。
示例 3-5 展示了如何用 Cypher 表达这一查询。在 MATCH 子句中同样使用箭头记法在图中查找模式:(person) -[:BORN_IN]-> () 匹配任何由一条标签为 BORN_IN 的边相连的两个顶点。该边的尾顶点会被绑定到变量 person,头顶点不命名。
示例 3-5. 一段 Cypher 查询:从美国移民到欧洲的人
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (:Location {name:'Europe'})
RETURN person.name这条查询可如下解读:
找出任何同时满足下面两个条件的顶点(称为
person):
person有一条出边BORN_IN,从该顶点出发,可沿一连串WITHIN出边走到一个Location类型的顶点,其name属性等于United States。- 同一个
person顶点也有一条LIVES_IN出边,之后再接连若干WITHIN出边,最终到达一个Location类型的顶点,其name属性等于Europe。对每个这样的
person顶点,返回其name属性。
执行这条查询有几种可能的方式。这里描述的做法是:先扫描数据库中所有人,检查每个人的出生地与居住地,只返回符合条件的人。
另一种等效的做法是从两个 Location 顶点开始反向走。如果 name 属性上有索引,你可以高效地找到分别代表"美国"与"欧洲"的两个顶点。然后沿着所有入向的 WITHIN 边,找到所有位于其中的地点(州、地区、城市等等)。最后,在某个地点顶点处寻找"通过入向的 BORN_IN 或 LIVES_IN 可达"的人。
用 SQL 做图查询
示例 3-3 暗示图数据可以在关系型数据库中表示。但如果我们把图数据放进关系结构,能不能也用 SQL 查询它?
答案是肯定的,但有点难度。在图查询中你遍历的每一条边,实际上都是与 edges 表的一次连接。在关系数据库中,你通常预先就知道查询里需要哪些连接。但在图查询中,在找到目标顶点之前,你可能要遍历数量不定的边——也就是说,连接的次数并非预先固定。
在我们的例子里,这一点出现在 Cypher 查询的 () -[:WITHIN*0..]-> () 模式中。某人的 LIVES_IN 边可能指向任何种类的位置:一条街、一个区、一个城市、一个区域,或一个州。一座城市可能 WITHIN 一个区域,区域 WITHIN 一个州,州 WITHIN 一个国家,等等。LIVES_IN 边可能直接指向你要找的位置顶点,也可能在层级中相隔多级。
在 Cypher 里,:WITHIN*0.. 把这一事实表达得非常简洁:意为"沿 WITHIN 边走零次或多次"。它就像正则表达式中的 * 算子。
这种可变长度遍历路径的思想在 SQL 中可用递归公共表表达式(recursive common table expressions)(即 WITH RECURSIVE 语法)表达。示例 3-6 用这一技术展示了同一查询——找出从美国移民到欧洲的人——的 SQL 写法(以 -- 开头的行是注释)。可见与 Cypher 相比,其语法相当笨重。
示例 3-6. 与示例 3-5 同样的查询,用 SQL 借助递归公共表表达式书写
WITH RECURSIVE
-- in_usa is the set of vertex IDs of all locations within the United States
in_usa(vertex_id) AS (
SELECT vertex_id FROM vertices
WHERE label = 'Location' AND properties->>'name' = 'United States' -- ❶
UNION
SELECT edges.tail_vertex FROM edges -- ❷
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'within'
),
-- in_europe is the set of vertex IDs of all locations within Europe
in_europe(vertex_id) AS (
SELECT vertex_id FROM vertices
WHERE label = 'location' AND properties->>'name' = 'Europe' -- ❸
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within'
),
-- born_in_usa is the set of vertex IDs of all people born in the US
born_in_usa(vertex_id) AS ( -- ❹
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in'
),
-- lives_in_europe is the set of vertex IDs of all people living in Europe
lives_in_europe(vertex_id) AS ( -- ❺
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in'
)
SELECT vertices.properties->>'name'
FROM vertices
-- join to find those people who were both born in the US *and* live in Europe
JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id -- ❻
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;❶ 先找到 name 属性为 United States 的顶点,把它作为 in_usa 顶点集的第一个元素。
❷ 沿 in_usa 集合中各顶点的所有入向 within 边走,把那些尾顶点加入同一集合,直到所有入向 within 边都被访问过。
❸ 用同样的方式从 name 为 Europe 的顶点开始,构造 in_europe 顶点集合。
❹ 对 in_usa 集中的每个顶点,沿入向 born_in 边找出生在美国某地的人。
❺ 类似地,对 in_europe 集中的每个顶点,沿入向 lives_in 边找出居住在欧洲的人。
❻ 最后,把"生在美国"的人与"住在欧洲"的人通过连接取交集。
仅 4 行的 Cypher 查询在 SQL 里要 31 行——这显示出选对数据模型与查询语言能带来多大差别。而这只是开始;还有更多需要考虑的方面,例如处理环路、在广度优先与深度优先遍历之间做选择 [42]。Oracle 有一种不同的 SQL 递归查询扩展,称为 hierarchical[43]。其他图查询语言还包括 TigerGraph 的 GSQL [44] 与 Property Graph Query Language(PGQL)[45]。
基于 Cypher 的 ISO 标准 Graph Query Language(GQL) 已于 2024 年发布 [46, 47, 48]。它尚未被广泛采用,但有望在未来数年内带来图数据库之间更多的一致性。
三元组存储与 SPARQL
三元组存储模型大体上与属性图模型等价,只是用不同的词汇来描述同样的思想。但它仍值得一谈,因为围绕三元组存储的各种工具与语言可以成为你应用构建工具箱里有价值的补充。
在三元组存储中,所有信息都以非常简单的三部分语句形式存储:(subject, predicate, object)。例如三元组 (Jim, likes, bananas) 中,Jim 是主语,likes 是谓词(动词),bananas 是宾语。
严格说,提供类似三元组数据模型的数据库通常需要在每个元组上存放一些额外的元数据。例如 AWS Neptune 通过给每个三元组加上图 ID,实际使用的是四元组(4-tuples)[49];Datomic 使用 5-tuples,把每个三元组扩展为含事务 ID 和一个表示删除的布尔值 [50]。由于这些数据库仍保留这里所讲的基本"主语-谓词-宾语"结构,本书仍称它们为三元组存储。
三元组的主语等价于图中的一个顶点。宾语则是下面两者之一:
- 一个原始数据类型(如字符串或数字)的值。这种情形下,三元组的谓词与宾语等价于主语顶点上某个属性的键与值。以图 3-6 为例,(lucy, birthYear, 1989) 相当于在顶点
lucy上附加一个属性{"birthYear": 1989}。 - 图中的另一个顶点。这种情形下,谓词是图中的一条边,主语是尾顶点,宾语是头顶点。例如 (lucy, marriedTo, alain) 中,主语与宾语 lucy 与 alain 都是顶点,谓词 marriedTo 则是连接它们的那条边的标签。
示例 3-7 用名为 Turtle 的格式(Notation3(N3) 的子集)把示例 3-4 的数据写成三元组 [51]。
示例 3-7. 把图 3-6 部分数据表示为 Turtle 三元组
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location.
_:usa :name "United States".
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location.
_:namerica :name "North America".
_:namerica :type "continent".在这个例子中,图的顶点被写为 _:someName 的形式。这些名字在文件之外没有意义;之所以需要它们,是因为否则我们就无法知道哪些三元组指代的是同一个顶点。当谓词代表一条边时,宾语是一个顶点,例如 _:idaho :within _:usa。当谓词代表一个属性时,宾语是一个字符串字面量,例如 _:usa :name "United States"。
为了表示更紧凑,可以用分号一次说出关于同一主语的多件事,如示例 3-8 所示。这让 Turtle 格式相当易读。
示例 3-8. 更简洁地写示例 3-7 中的数据
@prefix : <urn:example:>.
_:lucy a :Person; :name "Lucy"; :bornIn _:idaho.
_:idaho a :Location; :name "Idaho"; :type "state"; :within _:usa.
_:usa a :Location; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".语义网(The Semantic Web)
关于三元组存储的部分研究与开发受到语义网的启发——那是 2000 年代初为促进互联网范围数据交换所做的努力:让数据不仅作为人类可读网页发布,也以标准化、机器可读的方式发布。语义网的最初愿景虽然未能成功 [52, 53],但其遗产在不少地方延续——例如 JSON-LD [54] 等链接数据标准、生物医学领域使用的本体 [55]、Facebook 的 Open Graph 协议 [56](用于链接展开 [57])、Wikidata 等知识图谱,以及 Schema.org 维护的结构化数据标准词汇。
三元组存储是另一项在最初用例之外找到了用武之地的语义网技术;即便你对语义网毫无兴趣,三元组也可以是应用的一种良好的内部数据模型。
RDF 数据模型
我们在示例 3-8 中所用的 Turtle 语言其实是资源描述框架(Resource Description Framework,RDF) [58] 中数据的一种编码方式——RDF 是为语义网设计的数据模型。RDF 数据也可用其他方式编码,包括(更冗长的)XML,如示例 3-9。Apache Jena 等工具能在不同 RDF 编码间自动转换。
示例 3-9. 用 RDF/XML 语法表达示例 3-8 的数据
<rdf:RDF xmlns="urn:example:"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Location rdf:nodeID="idaho">
<name>Idaho</name>
<type>state</type>
<within>
<Location rdf:nodeID="usa">
<name>United States</name>
<type>country</type>
<within>
<Location rdf:nodeID="namerica">
<name>North America</name>
<type>continent</type>
</Location>
</within>
</Location>
</within>
</Location>
<Person rdf:nodeID="lucy">
<name>Lucy</name>
<bornIn rdf:nodeID="idaho"/>
</Person>
</rdf:RDF>RDF 有些特殊之处,因为它是为互联网范围的数据交换而设计的。三元组的主语、谓词、宾语常常是 URI。例如一个谓词可能是 URI,如 <http://my-company.com/namespace#within> 或 <http://my-company.com/namespace#lives_in>,而不仅仅是 WITHIN 或 LIVES_IN。这一设计的考虑是:你应该能把你的数据与别人的数据组合在一起;如果他们对 within 或 lives_in 一词赋予了不同的含义,也不会发生冲突——因为他们的谓词实际上是 <http://other.org/foo#within> 与 <http://other.org/foo#lives_in>。
URL <http://my-company.com/namespace> 不一定要能解析到任何资源——从 RDF 的视角看,它仅仅是一个命名空间。为避免与 http:// URL 的潜在混淆,本节示例使用诸如 urn:example:within 这样不可解析的 URI。所幸该前缀可以在文件顶部一次声明,之后便不必再操心。
SPARQL 查询语言
SPARQL 是一种查询语言,用以查询使用 RDF 数据模型的三元组存储 [59](这一名称是 SPARQL Protocol and RDF Query Language 的递归缩写,发音 "sparkle")。它早于 Cypher,且 Cypher 的模式匹配借自 SPARQL,因此两者看起来颇为相似。
同样的查询——找出从美国移居到欧洲的人——在 SPARQL 中和在 Cypher 中一样简洁(见示例 3-10)。
示例 3-10. 与示例 3-5 同样的查询,用 SPARQL 表达
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}结构非常类似。下面两个表达式等价(变量在 SPARQL 中以问号开头):
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher
?person :bornIn / :within* ?location. # SPARQL由于 RDF 不区分属性与边,仅用谓词同时表示二者,因此你可以用同样的语法来匹配属性。下面的表达式中,变量 usa 会被绑定到任何 name 属性值为字符串 United States 的顶点:
(usa {name:'United States'}) # Cypher
?usa :name "United States". # SPARQLAmazon Neptune、AllegroGraph、Blazegraph、OpenLink Virtuoso、Apache Jena 等多种三元组存储都支持 SPARQL [38]。
Datalog:递归关系查询
Datalog 是比 SPARQL 或 Cypher 老得多的语言,源于 1980 年代的学术研究 [60, 61, 62]。它在软件工程师中不太为人所知,主流数据库支持也不广泛,但其实理应得到更多了解,因为它的表达力很强,处理复杂查询尤其得力。Datomic、LogicBlox、CozoDB、LinkedIn 的 LIquid [63] 等若干小众数据库以 Datalog 作为查询语言。它基于关系数据模型而非图模型,但我们在此讨论它,是因为对图的递归查询正是 Datalog 的强项。
Datalog 数据库的内容被称为事实(facts),每条事实对应关系表中的一行。例如,假设我们有一张包含位置的 location 表,它有三列:ID、name 与 type。"美国是一个国家"这一事实可写为 location(2, "United States", "country"),其中 2 是美国的 ID。一般而言,语句 table(val1, val2, ...) 表示 table 含有这样一行——其第一列是 val1,第二列是 val2,依此类推。
示例 3-11 展示了如何用 Datalog 写图 3-6 左半边的数据。图的边(within、born_in 与 lives_in)被表示为两列连接表。例如 Lucy 的 ID 是 100,Idaho 的 ID 是 3,那么"Lucy 出生在 Idaho"这一关系就被表示为 born_in(100, 3)。
示例 3-11. 把图 3-6 部分数据表示为 Datalog 事实
location(1, "North America", "continent").
location(2, "United States", "country").
location(3, "Idaho", "state").
within(2, 1). /* US is in North America */
within(3, 2). /* Idaho is in the US */
person(100, "Lucy").
born_in(100, 3). /* Lucy was born in Idaho */定义好数据后,便可写出与之前一样的查询,如示例 3-12。它看起来和 Cypher 或 SPARQL 中的等价物有些不同,但请不要被它吓到。Datalog 是 Prolog 的子集——如果你学过计算机科学,可能见过它。
示例 3-12. 与示例 3-5 同样的查询,用 Datalog 表达
within_recursive(LocID, PlaceName) :- location(LocID, PlaceName, _). /* Rule 1 */
within_recursive(LocID, PlaceName) :- within(LocID, ViaID), /* Rule 2 */
within_recursive(ViaID, PlaceName).
migrated(PName, BornIn, LivingIn) :- person(PersonID, PName), /* Rule 3 */
born_in(PersonID, BornID),
within_recursive(BornID, BornIn),
lives_in(PersonID, LivingID),
within_recursive(LivingID, LivingIn).
us_to_europe(Person) :- migrated(Person, "United States", "Europe"). /* Rule 4 */
/* us_to_europe contains the row "Lucy". */Cypher 与 SPARQL 用 SELECT 直接切入主题,而 Datalog 则一步一步走。我们定义规则(rules),从底层事实派生出新的虚拟表。这些派生表就像(虚拟的)SQL 视图:它们并不真的存在于数据库里,但你可以像查询存放事实的表一样查询它们。
在示例 3-12 中我们定义了三张派生表:within_recursive、migrated 与 us_to_europe。每条规则中 :- 之前的内容定义了虚拟表的名字与列。例如 migrated(PName, BornIn, LivingIn) 是一张三列虚拟表:人的名字、其出生地的名字、其居住地的名字。
虚拟表的内容由 :- 之后的部分定义:在那里我们尝试在表中找出匹配某种模式的行。例如 person(PersonID, PName) 与行 person(100, "Lucy") 匹配,变量 PersonID 被绑定到值 100,PName 绑定到 "Lucy"。当系统能为 :- 右侧所有模式找到匹配时,规则就会被应用。规则被应用时,效果就好像 :- 左侧的内容(变量替换为它们所匹配的值)被加进了数据库一样。
应用规则的一种可能方式如下(如图 3-7 所示):
location(1, "North America", "continent")在数据库中存在,因此规则 1 适用,生成within_recursive(1, "North America")。within(2, 1)在数据库中存在,且前一步生成了within_recursive(1, "North America"),因此规则 2 适用,生成within_recursive(2, "North America")。within(3, 2)在数据库中存在,且前一步生成了within_recursive(2, "North America"),因此规则 2 适用,生成within_recursive(3, "North America")。
通过反复应用规则 1 与 2,within_recursive 虚拟表能告诉我们数据库里属于北美洲(或其他任何地点)的所有位置。
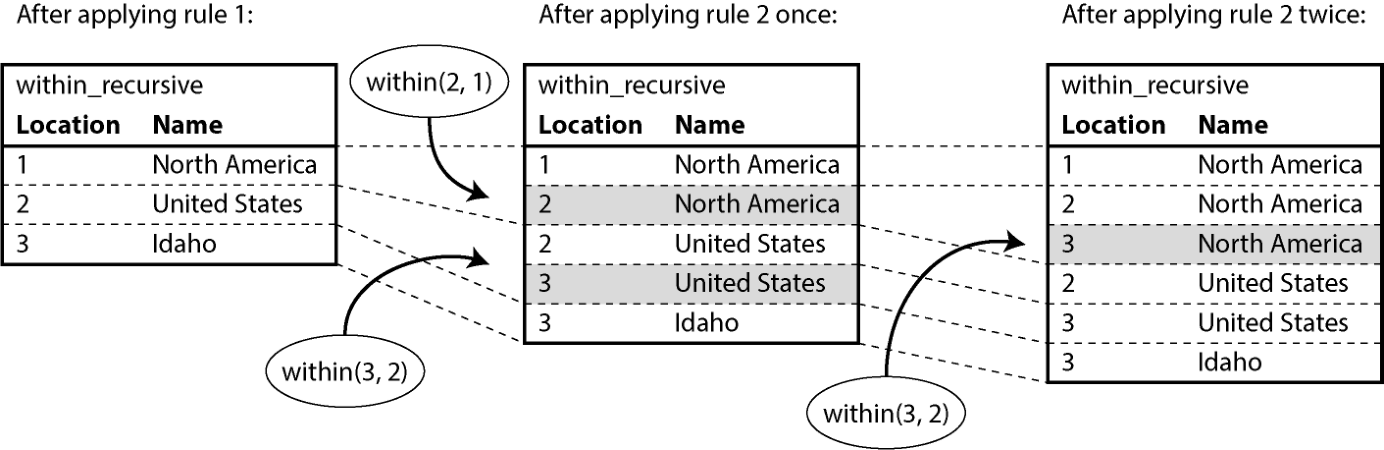
图 3-7. 通过示例 3-12 的 Datalog 规则确定 Idaho 在北美洲
图示文字描述: 图示三列网格"应用规则 1 后/规则 2 应用一次后/规则 2 应用两次后",第一列 within_recursive 含 (1, North America);第二列加入 (2, North America);第三列再加入 (3, North America)。
现在规则 3 可以找出出生在某地 BornIn、且现住在某地 LivingIn 的人。规则 4 以 BornIn = 'United States' 与 LivingIn = 'Europe' 调用规则 3,仅返回符合该搜索条件的人名。通过查询虚拟表 us_to_europe 的内容,Datalog 系统最终得到与之前 Cypher 与 SPARQL 查询一样的答案。
Datalog 的做法所要求的思考方式与本章其他查询语言不同。它允许复杂查询逐条规则地搭建,一条规则可引用其他规则,就像你把代码拆成可互相调用的函数那样。函数可以递归,Datalog 规则也可以——比如示例 3-12 的规则 2 自我调用,从而在 Datalog 查询中实现图遍历。
GraphQL
GraphQL 是一种查询语言,在设计上就比本章见到的其他语言更受限。它面向 OLTP 查询;其目的是让运行在用户设备上的客户端软件(如移动 App 或 JavaScript Web 应用前端)请求一个具有特定结构的 JSON 文档,包含渲染其 UI 所需的字段。
GraphQL 接口让开发者可以在不更改服务端 API 的情况下,快速修改客户端代码中的查询。然而这种灵活性是有代价的。采用 GraphQL 的组织通常需要工具把查询转换成对内部服务的请求,这些内部服务常用 REST 或 gRPC(参见第 5 章)。授权、限流与性能挑战是额外的关注点 [64]。
该语言也有意做了限制,因为 GraphQL 查询来自不可信任的来源。它不允许执行任何可能代价昂贵的操作——否则其他用户可能(或许是无意地)通过运行大量昂贵查询造成拒绝服务。具体而言,GraphQL 不允许递归查询(不像 Cypher、SPARQL、SQL 或 Datalog),也不允许任意搜索条件(如"找出生在美国并现居欧洲的人"),除非服务所有者明确选择提供这种搜索功能。
尽管如此,GraphQL 仍然有用。示例 3-13 展示了如何用 GraphQL 实现像 Discord 或 Slack 那样的群聊应用。该查询请求该用户有访问权限的所有频道,包括频道名与每个频道最近的 50 条消息。对每条消息,查询请求时间戳、消息内容以及发送者的名字与头像 URL。如果该消息是对另一条消息的回复,查询还会请求被回复消息发送者的姓名以及那条消息的内容(这部分可以以较小字号渲染在回复上方,以提供上下文)。
示例 3-13. 群聊应用的一段 GraphQL 查询
query ChatApp {
channels {
name
recentMessages(latest: 50) {
timestamp
content
sender {
fullName
imageUrl
}
replyTo {
content
sender {
fullName
}
}
}
}
}示例 3-14 展示了该查询响应可能的样子。响应是一个 JSON 文档,结构与查询一致:包含查询所请求的属性,不多不少。这样做的好处是:服务器无需知道客户端需要哪些属性来渲染 UI;客户端只需请求自己需要的内容即可。例如这条查询并未请求 replyTo 消息发送者的头像 URL,但若 UI 改动需要包含此头像,客户端只需在查询中加上所需的 imageUrl 属性,服务端无需更改。
示例 3-14. 对示例 3-13 查询可能的响应
{
"data": {
"channels": [
{
"name": "#general",
"recentMessages": [
{
"timestamp": 1693143014,
"content": "Hey! How are y'all doing?",
"sender": {"fullName": "Aaliyah", "imageUrl": "https://..."},
"replyTo": null
},
{
"timestamp": 1693143024,
"content": "Great! And you?",
"sender": {"fullName": "Caleb", "imageUrl": "https://..."},
"replyTo": {
"content": "Hey! How are y'all doing?",
"sender": {"fullName": "Aaliyah"}
}
},
...
]
}
]
}
}在这个例子里,消息发送者的姓名与头像 URL 直接嵌入在消息对象中。如果同一用户发送了多条消息,这些信息会在每条消息里重复出现。原则上可以减少这种重复,但 GraphQL 的设计选择是接受较大的响应体积,以让基于所请求数据来渲染 UI 这件事更简单。
replyTo 字段也类似:在示例 3-14 中,第二条消息回复了第一条,内容("Hey…")与发送者姓名(Aaliyah)被复制到 replyTo 下。也可以只返回所回复消息的 ID,但若该 ID 不在最近返回的 50 条消息之内,客户端就得再向服务器发一次请求。把内容复制过来,让数据用起来简单得多。
服务器的数据库可以以更规范化的形式存放数据,并在处理查询时执行所需的连接。例如服务器可能把一条消息与发送者的用户 ID 和被回复消息的 ID 一起存放;当它收到示例 3-13 这样的查询时,会解析这些 ID 找到它们指向的记录。然而客户端只能请求 GraphQL 模式中显式声明的连接。
虽然 GraphQL 查询的响应看起来类似文档数据库的响应,且其名字带有 "graph",但 GraphQL 可以在任何类型的数据库之上实现——关系、文档或图。
事件溯源与 CQRS
到目前为止讨论的所有数据模型,数据都以与写入时相同的形式被查询——无论是 JSON 文档、表中的行,还是图中的顶点和边。然而在复杂应用中,要找到一种能满足数据所有查询与呈现方式的单一数据表示,有时很难。这种情况下,把数据以一种形式写入,再从中派生出针对不同读取类型而优化的多种表示,会很有帮助。
我们之前在"真实数据源与派生数据"(第 10 页)中见过这一思想,ETL(参见"数据仓库",第 7 页)就是这种派生过程的一个例子。现在我们把它进一步推进。如果反正要从一种数据表示派生出另一种,那我们就可以选择分别针对写入与读取做优化的不同表示。如果数据建模只为写入优化、查询效率毫不重要,你会怎么建?
也许写入数据最简单、最快、表达力最强的方式是事件日志(event log):每次想写入一些数据,就把它编码为一个自包含的字符串(也许是 JSON),带上一个时间戳,并*追加(append)到事件序列。该日志中的事件是不可变(immutable)*的;你从不修改或删除它们,只往日志里添加更多事件(这些后续事件可能取代早先事件)。一个事件可以包含任意属性。
图 3-8 展示了一个可能取自会议管理系统的例子。一场会议可以是一个复杂的业务领域:不仅个人参会者可以注册并刷卡支付,公司也可以批量订座、按发票付款,再把座位分给具体个人。可能有一定数量的座位预留给演讲者、赞助商、志愿者助手等。预订也可以被取消,会议组织者也可能通过把活动换到另一房间来改变容量。在这一切之上,仅仅计算可用座位数本身就成了一项颇具挑战的查询。

图 3-8. 把不可变事件的日志当作真相之源,并由其派生出物化视图
图示文字描述: 图示左侧"事件日志"列表(依时间顺序):conference_created(10-28)→ registrations_opened(10-30 07:03:19)→ seats_reserved(10-30 07:06:01,customer_id 331,3 座,booking_id 4001)→ booking_payment_confirmed(07:10:42,paid_amount 1497.00 USD)→ booking_canceled(10-31 21:52:35,customer_id 345,booking_id 4003)...;右侧两个 Materialized view:上方"客户预订确认"的 JSON 文档(booking_id 4001、conference_name、paid_amount、paid_currency、unassigned_seats、assigned_seats: [{badge_id 501 Aaliyah}, {badge_id 502 Caleb}]);下方"会议组织者仪表板"折线图(座位预订量随时间增长,以 Venue capacity 上限横线作参考,从 Registrations open 到 Conference begins)。中间箭头标"由同一份事件日志派生多个物化视图"。
在图 3-8 中,会议状态的每一次变化(如组织者打开注册、参会者注册或取消注册)都先被存为一个事件。每当有事件被追加到日志,若干物化视图(也叫投影或读模型)也会被更新,以反映该事件的影响。在会议这个例子中,可能有一个物化视图汇总每项预订的全部相关信息(用于会议组织者仪表板);另一个物化视图为仪表板计算图表;第三个为打印参会者徽章的打印机生成文件。
把事件作为真相之源、把每一次状态变化表达为事件——这种思想被称为事件溯源(event sourcing) [65, 66]。为读取另外维护一份针对读优化的表示,并由"为写入优化的表示"派生而来——这种原则被称为命令查询职责分离(CQRS) [67]。这些术语起源于 DDD 社区,但类似思想其实早已存在——例如状态机复制(参见"用共享日志",第 433 页)。
用户进来的请求称为命令(command),需先对其做校验。一旦命令被执行并被认定为有效(例如所请求的座位预留数量足够),它就成为一项事实,对应的事件被加进日志。因此事件日志中应当只包含有效事件,而构建物化视图的事件日志消费者也不允许拒绝事件。
在以事件溯源风格建模时,建议给事件起过去时的名字(如 "the seats were booked"),因为事件是某事已经发生的记录。即便用户后来决定改动或取消预订,事实仍然为真:他们曾经做过一次预订;改动或取消则是稍后追加的独立事件。
事件溯源与"用于分析的星型与雪花型模式"(第 77 页)所讨论的事实表的相似之处在于:两者都是过去发生事件的集合。然而事实表中所有行都有同样一组列,而事件溯源里事件类型可能很多、各自属性不同。此外,事实表是无序集合,而事件溯源中事件的顺序很重要:若先发生预订再发生取消,把它们按错误顺序处理就毫无意义。
事件溯源与 CQRS 有几个主要优势:
- 对开发系统的人而言,事件能更好地传达"事情为什么会发生"的意图。例如,事件"预订被取消"比"
bookings表 4001 行的active列被设为 false、seat_assignments表中与该预订关联的三行被删除、payments表新增了一行表示退款"更易理解。这些行修改可能仍然会发生(当某个物化视图处理取消事件时),但当它们由某个事件驱动时,"为何更新"变得清楚得多。 - 事件溯源的关键原则是:物化视图以可重现的方式从事件日志派生出来。你应当总能删掉物化视图、用同一份代码按同一顺序处理同一份事件、把它们重新计算出来。如果视图维护代码里有 bug,你可以删掉视图,用新代码再重算一次。这也更易找出 bug,因为你可以反复运行视图维护代码并观察其行为。
- 你可以拥有多个物化视图,针对应用所需的具体查询分别做优化。这些视图可以与事件存放在同一个数据库,也可以放到不同数据库,视需要而定。它们可以使用任何数据模型,并可以被反规范化以加快读取。你甚至可以把视图只放在内存中、不持久化它,只要服务重启时能从事件日志重新计算出来就没问题。
- 如果你决定以新方式呈现现有信息,从已有事件日志构建一个新的物化视图也很容易。你也可以通过添加新的事件类型,或在现有事件类型上加新属性,来让系统支持新功能(旧事件保持不变)。也可以从新事件触发新行为(例如当会议参会者取消时,其座位可以让给等候列表上的下一个人)。
- 如果某事件是误写,可以再写一个"删除事件"来撤销它。下游视图会自动并入这一删除,从而修正数据。相反,在直接更新与删除数据的数据库中,已提交事务往往难以撤销。事件溯源因此可以减少系统中不可逆动作的数量,让变更更容易(参见"可演化性:让变更易于进行",第 55 页)。
- 事件日志还可作为系统中所发生事情的审计日志,对监管行业里需要这种可审计性的场景很有价值。
- 得益于顺序访问模式,事件日志通常比数据库能承载更高的写入吞吐量。如果出现事件的临时突增,日志能将其吸收,下游维护物化视图的系统按自己的步调追上即可,不会被压垮。
但事件溯源与 CQRS 也有缺点:
- 涉及外部信息时要小心。例如某事件含有以一种货币表示的价格,对其中一个视图需要把它换算到另一种货币。由于汇率会波动,处理事件时去外部源取汇率是有问题的——因为日后重新计算物化视图时会得到不同结果。要让事件处理逻辑保持确定性(deterministic),你必须把汇率包含进事件本身,或者有一种方法:按事件指出的时间戳查询历史汇率,并保证该查询在同一时间戳上始终返回同一结果。
- 事件不可变这一要求,在事件含用户个人数据时会带来问题——因为用户可以行使删除其数据的权利(例如根据 GDPR)。如果事件日志按用户分开存放,可以删除该用户的整份日志;但当事件日志含有与多个用户相关的事件时,这就行不通了。你可以尝试把个人数据存在实际事件之外,或用一把日后可选择删除的密钥来加密它(一种被称为 crypto-shredding 的技巧 [68]);不过这也会让在需要时重新计算派生状态变得更困难。
- 重新处理事件时若有外部可见的副作用,要谨慎处理——例如你大概不希望每次重建物化视图就重发一次确认邮件。
你可以在任何数据库之上实现事件溯源,但有些系统专门为支持这种模式而设计,如 EventStoreDB、MartenDB(基于 PostgreSQL)与 Axon Framework。你也可以用 Apache Kafka 等消息代理来存放事件日志,让流处理器把物化视图保持为最新;我们将在第 12 章重新讨论这些主题。
唯一重要的要求是:事件存储系统必须保证所有物化视图都按事件在日志中出现的完全相同的顺序来处理这些事件。正如我们在第 10 章将看到的,在分布式系统中要做到这一点并不总是容易的。
DataFrame、矩阵与数组
本章到目前为止见到的数据模型一般都被同时用于事务处理与分析(参见"运营系统与分析系统",第 3 页)。还有一些数据模型,你在分析或科学场景下可能会遇到,但它们很少出现在 OLTP 系统中,包括 DataFrame 与多维数字数组(如矩阵)。
R 语言、Python 的 Pandas 库、Apache Spark、ArcticDB、Dask 等系统都支持 DataFrame 数据模型。DataFrame 是数据科学家为训练 ML 模型准备数据时的常用工具,但也广泛用于数据探索、统计分析、数据可视化等类似场景。
乍一看,DataFrame 类似于关系数据库中的表或电子表格。DataFrame 支持类似关系的算子,可以对内容做批量操作;例如对所有行应用一个函数、按条件过滤行、按某些列分组并对其他列做聚合,以及基于一个键把一份 DataFrame 的行与另一份 DataFrame 的行连接起来(关系数据库里叫 join 的操作,在 DataFrame 里通常叫 merge)。
DataFrame 一般不使用 SQL 这样的声明式查询语言,而是通过一系列修改其结构与内容的命令来操控。这与数据科学家典型的工作流相符:以增量方式"折腾(wrangle)"数据,把它整理成能回答当前问题的形态。这些操作通常发生在数据科学家自己手头的数据集副本上,常常就在他们本地机器上运行;最终结果可能再分享给其他用户。
DataFrame API 提供的操作远比关系数据库丰富,其数据模型也常常以与典型关系数据建模迥异的方式被使用 [69]。例如 DataFrame 的一种常见用途是把数据从类关系表示转换为矩阵或多维数组表示——许多 ML 算法都期望这种形态的输入。
图 3-9 给出了一个简单的转换例子。左侧是一张关系表,记录用户对各部电影的评分(1 到 5);右侧数据已被转换为矩阵,每列是一部电影,每行是一名用户(类似电子表格中的透视表)。该矩阵是稀疏的——意思是说许多"用户-电影"组合没有数据,但这没关系。这个矩阵可能有数千列,因此不太适合装进关系数据库;不过 DataFrame 与提供稀疏数组的库(如 Python 的 NumPy)能轻松处理这类数据。
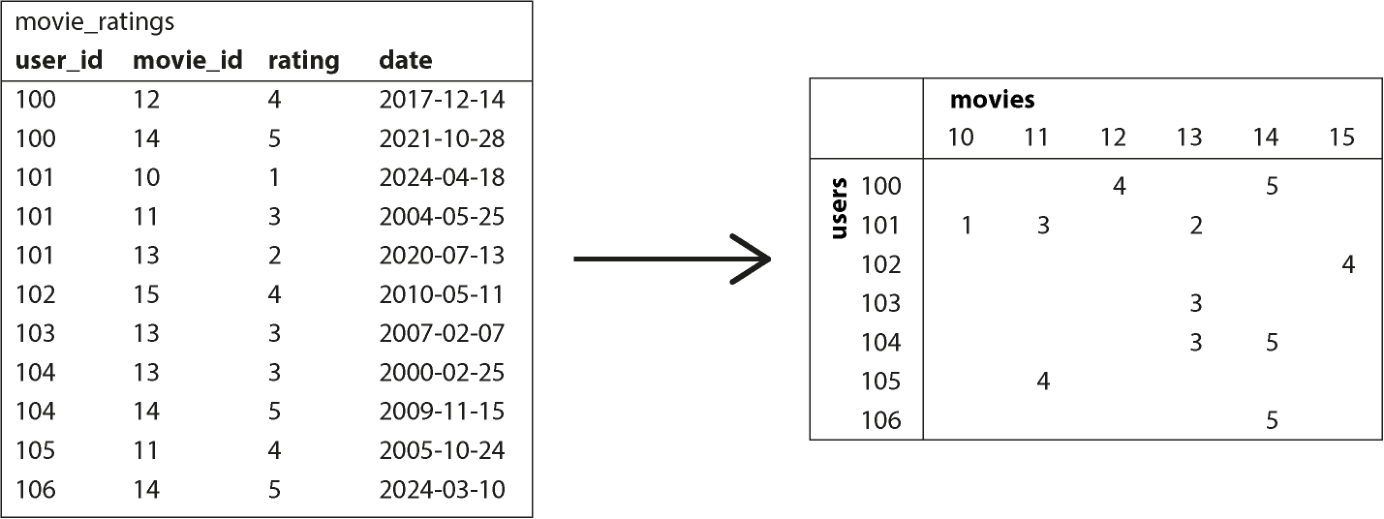
图 3-9. 把一份记录电影评分的关系数据库转换为矩阵
图示文字描述: 左侧 movie_ratings 表(user_id、movie_id、rating、date 列):(100,12,4)、(100,14,5)、(101,10,1)、(101,11,3)、(101,13,2)、(102,15,4)、(103,13,3)、(104,13,3)、(104,14,5)、(105,11,4)、(106,14,5) 等行;右侧矩阵以行为 users (100–106)、列为 movies (10–15),单元格填入相应评分(多数空白)。
矩阵只能含数字,因此就需要各种技术把非数字数据转换为矩阵中的数字。例如:
- 日期(在图 3-9 的矩阵中已省略)可以被缩放为合适范围内的浮点数。
- 对取值只能来自一个较小固定集合的列(如电影数据库中电影的类型),常用独热编码(one-hot encoding):为每个可能值(如"喜剧"、"剧情"、"恐怖"等)建一列;对每一行(表示一部电影),在它对应类型的那列填 1,其他列填 0。这种表示也容易推广到属于多种类型的电影。
一旦数据呈矩阵形式,就可以做线性代数运算——许多 ML 算法以此为基础。例如图 3-9 中的数据可以成为"向用户推荐其可能喜欢电影"的系统的一部分。DataFrame 足够灵活,允许数据从关系形态逐步演化为矩阵表示,同时让数据科学家始终掌握"何种表示最适合数据分析或模型训练"这一控制权。
某些数据库——如 TileDB [70]——专门存储大型多维数字数组;它们被称为数组数据库,最常用于地理空间测量(按规则网格采样的栅格数据)、医学影像或天文望远镜观测等科学数据集 [71]。DataFrame 在金融行业也被用来表示时序数据,例如资产价格与交易随时间的变化 [72]。由于 DataFrame 在数据科学家中很流行,Spark 和 Flink 等批处理框架也已加入 DataFrame;我们在第 11 章会重回这一话题。
小结
数据模型是个庞大主题,本章对它做了一次覆盖面广而快速的浏览。我们无暇讨论每种模型的所有细节,但希望本概览足以激起你的兴趣,去寻找最适合你应用需求的那一种。
关系模型——尽管已诞生超过半个世纪——对许多应用而言仍是重要的数据模型,尤其在数据仓库与商业分析领域,关系型星型或雪花模式与 SQL 查询无处不在。然而在其他领域,关系模型已涌现出几种流行的替代方案:
- 文档模型瞄准这样的用例:数据以自包含的 JSON 文档形式存入,且文档之间的关系不多。
- 图数据模型走相反方向,瞄准这样的用例:任何事物都可能与任何事物相关,查询可能需要遍历多跳才能找到所需数据(这一需求可用 Cypher、SPARQL 或 Datalog 中的递归查询来满足)。
- DataFrame 把关系数据扩展到大量列,提供了数据库与多维数组之间的桥梁——后者是许多机器学习、统计分析、科学计算的基础。
在某种程度上,一种模型常常可以用另一种模型的术语来模拟——例如图数据可以在关系数据库中表示——但结果会很别扭,正如我们在 SQL 对递归查询的支持中所见。
因此人们开发出各种专用数据库,为各自的数据模型提供查询语言与存储引擎,并为之做特定优化。但也有一种趋势:数据库通过增加对其他数据模型的支持,向相邻领域延伸——例如关系数据库已加入了 JSON 列形式的文档数据支持;文档数据库已加入了类关系连接;SQL 对图数据的支持也在逐步改进。
我们讨论的另一种模型是事件溯源:把数据表示为不可变事件的仅追加日志,对复杂业务领域的建模可能很有优势。仅追加日志有利于写入数据(如第 4 章所见);为支持高效查询,事件日志通过 CQRS 被翻译成针对读取优化的物化视图。
非关系数据模型有一个共同点:它们通常不会为存储的数据强制施加模式,这能让应用更容易适应不断变化的需求。然而你的应用很可能仍然假设数据具有某种结构;问题只在于这一模式是显式的(写时强制)还是隐式的(读时假定)。
虽然我们覆盖了不少内容,仍有一些数据模型未涉及。下面简短举几例:
- 处理基因组数据的研究人员常需要做序列相似性搜索:给定一个非常长的字符串(代表一段 DNA 分子),把它与一个大型数据库做比对,该数据库包含许多相似但不完全相同的字符串。本章描述的数据库都难以处理这种用法,所以研究者写出了像 GenBank 这样的专用基因组数据库 [73]。
- 许多金融系统使用带复式记账的*账本(ledgers)*作为其数据模型。这类数据可以在关系数据库中表示,但也有专门的数据库(如 TigerBeetle)为它而生。加密货币与区块链通常基于分布式账本,且账本数据模型内置了价值转移。
- 全文搜索可以说也是一种数据模型,常与数据库一同使用。信息检索是一个庞大的专门主题,本书不做深入讨论,但我们将在"全文搜索"(第 146 页)触及搜索索引与向量搜索。
到此先告一段落。下一章我们将讨论实现本章所述数据模型时会出现的若干取舍。
参考文献
[1] Jamie Brandon. "Unexplanations: Query Optimization Works Because SQL Is Declarative." scattered-thoughts.net, February 2024. 归档于 perma.cc/P6W2-WMFZ
[2] Neel Krishnaswami. "What Declarative Languages Are." semantic-domain.blogspot.com, July 2013. 归档于 perma.cc/R4LP-T2RV
[3] Joseph M. Hellerstein. "The Declarative Imperative: Experiences and Conjectures in Distributed Logic." Tech report UCB/EECS-2010-90, EECS, UC Berkeley, June 2010. 归档于 perma.cc/K56R-VVQQ
[4] Edgar F. Codd. "A Relational Model of Data for Large Shared Data Banks." Communications of the ACM, volume 13, issue 6, pages 377–387, June 1970.
[5] Michael Stonebraker, Joseph M. Hellerstein. "What Goes Around Comes Around." In Readings in Database Systems, 4th edition, MIT Press, 2005, pages 2–41. ISBN: 9780262693141
[6] Markus Winand. "Modern SQL: Beyond Relational." modern-sql.com, 2015. 归档于 perma.cc/D63V-WAPN
[7] Martin Fowler. "Orm Hate." martinfowler.com, May 2012. 归档于 perma.cc/VCM8-PKNG
[8] Vlad Mihalcea. "N+1 Query Problem with JPA and Hibernate." vladmihalcea.com, January 2023. 归档于 perma.cc/79EV-TZKB
[9] Jens Schauder. "This Is the Beginning of the End of the N+1 Problem: Introducing Single Query Loading." spring.io, August 2023. 归档于 perma.cc/6V96-R333
[10] Jamie Brandon. "SQL Needed Structure." scattered-thoughts.net, September 2025. 归档于 perma.cc/9EVK-HLVR
[11] William Zola. "6 Rules of Thumb for MongoDB Schema Design." mongodb.com, June 2014. 归档于 perma.cc/T2BZ-PPJB
[12] Sidney Andrews, Christopher McClister. "Data Modeling in Azure Cosmos DB." learn.microsoft.com, February 2023. 归档于 archive.org
[13] Raffi Krikorian. "Timelines at Scale." At QCon San Francisco, November 2012. 归档于 perma.cc/V9G5-KLYK
[14] Ralph Kimball, Margy Ross. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, 3rd edition. John Wiley & Sons, 2013. ISBN: 9781118530801
[15] Michael Kaminsky. "Data Warehouse Modeling: Star Schema vs. OBT." fivetran.com, August 2022. 归档于 perma.cc/2PZK-BFFP
[16] Joe Nelson. "User-defined Order in SQL." begriffs.com, March 2018. 归档于 perma.cc/GS3W-F7AD
[17] Evan Wallace. "Realtime Editing of Ordered Sequences." figma.com, March 2017. 归档于 perma.cc/K6ER-CQZW
[18] David Greenspan. "Implementing Fractional Indexing." observablehq.com, October 2020. 归档于 perma.cc/5N4R-MREN
[19] Martin Fowler. "Schemaless Data Structures." martinfowler.com, January 2013.
[20] Amr Awadallah. "Schema-on-Read vs. Schema-on-Write." At Berkeley EECS RAD Lab Retreat, May 2009. 归档于 perma.cc/DTB2-JCFR
[21] Martin Odersky. "The Trouble with Types." At Strange Loop, September 2013. 归档于 perma.cc/85QE-PVEP
[22] Conrad Irwin. "MongoDB—Confessions of a PostgreSQL Lover." At HTML5DevConf, October 2013. 归档于 perma.cc/C2J6-3AL5
[23] "Percona Toolkit Documentation: pt-online-schema-change." docs.percona.com, 2023. 归档于 perma.cc/9K8R-E5UH
[24] Shlomi Noach. "gh-ost: GitHub's Online Schema Migration Tool for MySQL." github.blog, August 2016. 归档于 perma.cc/7XAG-XB72
[25] Shayon Mukherjee. "pg-osc: Zero Downtime Schema Changes in PostgreSQL." shayon.dev, February 2022. 归档于 perma.cc/35WN-7WMY
[26] Carlos Pérez-Aradros Herce. "Introducing pgroll: Zero-Downtime, Reversible, Schema Migrations for Postgres." xata.io, October 2023. 归档于 archive.org
[27] James C. Corbett 等。"Spanner: Google's Globally-Distributed Database." At 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012.
[28] Donald K. Burleson. "Reduce I/O with Oracle Cluster Tables." dba-oracle.com. 归档于 perma.cc/7LBJ-9X2C
[29] Fay Chang 等。"Bigtable: A Distributed Storage System for Structured Data." At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006.
[30] Priscilla Walmsley. XQuery, 2nd edition. O'Reilly Media, 2015. ISBN: 9781491915080
[31] Paul C. Bryan, Kris Zyp, Mark Nottingham. "JavaScript Object Notation (JSON) Pointer." RFC 6901, IETF, April 2013.
[32] Stefan Gössner, Glyn Normington, Carsten Bormann. "JSONPath: Query Expressions for JSON." RFC 9535, IETF, February 2024.
[33] Michael Stonebraker, Andrew Pavlo. "What Goes Around Comes Around… And Around…." ACM SIGMOD Record, volume 53, issue 2, pages 21–37, July 2024.
[34] Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd. "The PageRank Citation Ranking: Bringing Order to the Web." Technical Report 1999-66, Stanford University InfoLab, November 1999. 归档于 perma.cc/UML9-UZHW
[35] Nathan Bronson 等。"TAO: Facebook's Distributed Data Store for the Social Graph." At USENIX Annual Technical Conference (ATC), June 2013.
[36] Natasha Noy 等。"Industry-Scale Knowledge Graphs: Lessons and Challenges." Communications of the ACM, volume 62, issue 8, pages 36–43, August 2019.
[37] Xiyang Feng, Guodong Jin, Ziyi Chen, Chang Liu, Semih Salihoğlu. "KÙZU Graph Database Management System." At 13th Annual Conference on Innovative Data Systems Research (CIDR 2023), January 2023. 归档于 perma.cc/PS6J-ZBZU
[38] Maciej Besta 等。"Demystifying Graph Databases: Analysis and Taxonomy of Data Organization, System Designs, and Graph Queries." arXiv:1910.09017, October 2019.
[39] "Apache TinkerPop. TinkerPop 3.6.3 Documentation." tinkerpop.apache.org, May 2023. 归档于 perma.cc/KM7W-7PAT
[40] Nadime Francis 等。"Cypher: An Evolving Query Language for Property Graphs." At International Conference on Management of Data (SIGMOD), May 2018.
[41] Emil Eifrem. Twitter correspondence, January 2014. 归档于 perma.cc/WM4S-BW64
[42] Francesco Tisiot. "Explore the New SEARCH and CYCLE Features in PostgreSQL® 14." aiven.io, December 2021. 归档于 perma.cc/J6BT-83UZ
[43] Gaurav Goel. "Understanding Hierarchies in Oracle." towardsdatascience.com, May 2020. 归档于 perma.cc/5ZLR-Q7EW
[44] Alin Deutsch, Yu Xu, Mingxi Wu. "Seamless Syntactic and Semantic Integration of Query Primitives over Relational and Graph Data in GSQL." tigergraph.com, November 2018. 归档于 perma.cc/JG7J-Y35X
[45] Oskar van Rest 等。"PGQL: A Property Graph Query Language." At 4th International Workshop on Graph Data Management Experiences and Systems (GRADES), June 2016.
[46] Philip Rathle, Brad Bebee. "GQL: The ISO Standard for Graphs Has Arrived." aws.amazon.com, April 2024. 归档于 perma.cc/5TEU-N2Y8
[47] Alin Deutsch 等。"Graph Pattern Matching in GQL and SQL/PGQ." At International Conference on Management of Data (SIGMOD), June 2022.
[48] Alastair Green. "SQL...And Now GQL." opencypher.org, September 2019. 归档于 perma.cc/AFB2-3SY7
[49] Amazon Web Services. "Neptune Graph Data Model." Amazon Neptune User Guide, docs.aws.amazon.com. 归档于 perma.cc/CX3T-EZU9
[50] Cognitect. "Datomic Data Model." Datomic Cloud Documentation, docs.datomic.com. 归档于 perma.cc/LGM9-LEUT
[51] David Beckett, Tim Berners-Lee. "Turtle—Terse RDF Triple Language." W3C Team Submission, March 2011.
[52] Sinclair Target. "Whatever Happened to the Semantic Web?" twobithistory.org, May 2018. 归档于 perma.cc/M8GL-9KHS
[53] Gavin Mendel-Gleason. "The Semantic Web Is Dead—Long Live the Semantic Web!" terminusdb.com, August 2022. 归档于 perma.cc/G2MZ-DSS3
[54] Manu Sporny. "JSON-LD and Why I Hate the Semantic Web." manu.sporny.org, January 2014. 归档于 perma.cc/7PT4-PJKF
[55] University of Michigan Library. "Biomedical Ontologies and Controlled Vocabularies." guides.lib.umich.edu/ontology. 归档于 perma.cc/Q5GA-F2N8
[56] Facebook. "The Open Graph Protocol." ogp.me. 归档于 perma.cc/C49A-GUSY
[57] Matt Haughey. "Everything You Ever Wanted to Know About Unfurling but Were Afraid to Ask /or/ How to Make Your Site Previews Look Amazing in Slack." medium.com, November 2015. 归档于 perma.cc/C7S8-4PZN
[58] W3C RDF Working Group. "Resource Description Framework (RDF)." w3.org, February 2004.
[59] Steve Harris, Andy Seaborne, Eric Prud'hommeaux. "SPARQL 1.1 Query Language." W3C Recommendation, March 2013.
[60] Todd J. Green, Shan Shan Huang, Boon Thau Loo, Wenchao Zhou. "Datalog and Recursive Query Processing." Foundations and Trends in Databases, volume 5, issue 2, pages 105–195, November 2013.
[61] Stefano Ceri, Georg Gottlob, Letizia Tanca. "What You Always Wanted to Know About Datalog (And Never Dared to Ask)." IEEE Transactions on Knowledge and Data Engineering, volume 1, issue 1, pages 146–166, March 1989.
[62] Serge Abiteboul, Richard Hull, Victor Vianu. Foundations of Databases. Addison-Wesley, 1995. ISBN: 9780201537710. 在线可读:webdam.inria.fr/Alice
[63] Scott Meyer, Andrew Carter, Andrew Rodriguez. "LIquid: The Soul of a New Graph Database, Part 2." engineering.linkedin.com, September 2020. 归档于 perma.cc/K9M4-PD6Q
[64] Matt Bessey. "Why, After 6 Years, I'm over GraphQL." bessey.dev, May 2024. 归档于 perma.cc/2PAU-JYRA
[65] Dominic Betts 等。Exploring CQRS and Event Sourcing. Microsoft Patterns & Practices, 2012. ISBN: 9781621140164. 归档于 perma.cc/7A39-3NM8
[66] Greg Young. "CQRS and Event Sourcing." At Code on the Beach, August 2014.
[67] Greg Young. "CQRS Documents." cqrs.wordpress.com, November 2010. 归档于 perma.cc/X5R6-R47F
[68] Brent Robinson. "Crypto Shredding: How It Can Solve Modern Data Retention Challenges." medium.com, January 2019. 归档于 perma.cc/4LFK-S6XE
[69] Devin Petersohn 等。"Towards Scalable Dataframe Systems." Proceedings of the VLDB Endowment, volume 13, issue 11, pages 2033–2046, July 2020.
[70] Stavros Papadopoulos, Kushal Datta, Samuel Madden, Timothy Mattson. "The TileDB Array Data Storage Manager." Proceedings of the VLDB Endowment, volume 10, issue 4, pages 349–360, November 2016.
[71] Florin Rusu. "Multidimensional Array Data Management." Foundations and Trends in Databases, volume 12, issues 2–3, pages 69–220, February 2023.
[72] Ed Targett. "Bloomberg, Man Group Team Up to Develop Open Source 'ArcticDB' Database." thestack.technology, March 2023. 归档于 perma.cc/M5YD-QQYV
[73] Dennis A. Benson 等。"GenBank." Nucleic Acids Research, volume 36, issue suppl_1, pages D25–D30, January 2008.