第 11 章 批处理
一个系统若过于受某一个人影响,就不可能成功。等到初始设计完成、足够稳健之后,真正的考验才刚刚开始——人们带着各自不同的视角进行各自的实验。
—— Donald Knuth,《The Errors of TeX》(1989)
到目前为止本书谈的多数都是请求与查询及其对应的响应或结果。许多现代数据系统都默认采用这种数据处理风格:你提出请求或下达指令,系统尽快给你答案。
请求页面的浏览器、调用远程 API 的服务、数据库、缓存、搜索索引等等都属于这一范畴。我们把它们称为在线系统。响应时间通常是它们最重要的性能指标,且它们往往要求容错以保证高可用。
然而有时你需要进行规模更大的计算,或处理远超交互式请求所能承载的数据量。也许你要训练一个 AI 模型、把大量数据从一种形式转换为另一种,或对极大数据集做分析。这些任务被称为批处理作业,处理它们的系统有时也被称为离线系统。
批处理作业读取只读输入,产出输出——每次运行都从零生成。它通常不像读写事务那样修改数据;其输出是从输入派生出来的(如第 10 页"真实数据源与派生数据"所述)。如果你不喜欢这一次的输出,可以删掉它、调整作业逻辑,再跑一次。
把输入视为不可变、并避免副作用(如写入外部数据库),不仅能让批作业获得良好性能,还带来其他好处:
- 如果代码里引入 bug 导致输出错误或损坏,只需回滚到先前版本、重新运行作业,输出便会重新变得正确。或者更简单:把旧输出留在另一个目录中,切回去用即可。多数对象存储与开放表格式(见第 135 页"云数据仓库")都支持这一特性,叫做时间旅行(time travel)。具备读写事务的数据库多数没有这一性质:如果你部署了一段把坏数据写进数据库的代码,回滚代码并不能修复那些数据。这种"能从有 bug 的代码中恢复"的思想被称为人为错误容错[1]。
- 由于回滚成本如此之低,特性开发也能在一种"出错也不会造成不可逆损害"的环境里推进得更快。这一最小化不可逆性原则对敏捷软件开发大有裨益 [2]。
- 同一组文件可作为多种作业的输入,包括用于计算指标、评估某作业输出是否符合预期(如与上一次运行的输出对比、衡量差异)的监控作业。
- 批处理框架对计算资源的利用很高效。虽然你可以借助 OLTP 数据库或应用服务器等在线数据系统去做批处理,但那样在资源开销上会昂贵得多。
批处理已在广泛的用例中证明其价值,我们会在第 476 页"批处理用例"中再回顾。但它也带来挑战:在多数框架下,输出要等作业结束才能被其他作业处理;批处理也可能效率不高——对输入数据哪怕只改一个字节,批作业都得重新处理整个数据集。
批作业可能运行很久:分钟、小时、乃至数天。作业可被配置为周期性运行(如每天一次)。性能的主要衡量指标通常是吞吐量:作业每单位时间能处理多少数据。有些系统应对故障的方式很简单——把整个作业中止再重启;另一些则具备容错能力,使作业能在部分节点崩溃的情况下仍成功完成。
在线与批处理系统之间的边界并非总是清晰:一次长时间运行的数据库查询看上去就颇像批处理。但批处理还有些特别的特性,使其成为构建可靠、可扩展、可维护应用的有用基石。例如它常在数据集成中扮演角色——把多个数据系统组合起来,达成任一系统单独所做不到的事。第 7 页"数据仓库"中讨论的 ETL 就是一例。
批处理的另一种替代方案是流处理:作业并不在处理完输入后结束运行,而是持续监控输入,并在输入有变更后随即处理。我们会在第 12 章转入流处理。
现代批处理深受 MapReduce 影响——这是一种由 Google 在 2004 年发表 [3]、随后在多种开源数据系统(包括 Hadoop、CouchDB、MongoDB)中得到实现的批处理算法。与数据仓库中的并行查询执行引擎相比 [4, 5],MapReduce 是相当朴素的编程模型。它问世之时,在"用商品硬件可达到的处理规模"上是一次重要进步;而如今它已在很大程度上被淘汰,Google 内部也不再使用 [6, 7]。
如今的批处理更常借助 Spark、Flink 等框架或数据仓库查询引擎完成。它们与 MapReduce 一样依赖分片(见第 7 章)与并行执行,但拥有远更精巧的缓存与执行策略。随着这些系统逐渐成熟,运维方面的难题已大体被解决,重心也转向了易用性。新的处理模型——数据流 API、查询语言、DataFrame API——如今得到广泛支持。作业与工作流编排也在成熟之中:以 Hadoop 为中心的工作流调度器(如 Oozie、Azkaban)已被 Airflow、Dagster、Prefect 等支持更广泛批处理框架与云数据仓库的通用方案取代。
云计算同样愈发普及。批处理的存储层正从 HDFS(Hadoop 分布式文件系统)、GlusterFS、CephFS 等分布式文件系统(DFS)迁向 S3 这样的对象存储;BigQuery、Snowflake 等可扩展云数据仓库则在模糊数据仓库与批处理之间的边界。
为了对批处理形成直观认识,本章先以一个使用单机标准 Unix 工具的例子开场;继而研究如何把数据处理扩展到分布式系统的多台机器上——我们会发现,分布式批处理框架很像一种操作系统:既有调度器又有文件系统。然后会探讨编写批作业时所用的各种处理模型;最后讨论常见的批处理用例。
用 Unix 工具做批处理
假设你有一台 Web 服务器,每次响应请求就在日志文件中追加一行。例如使用 NGINX 默认访问日志格式时,一行日志大致如下:
216.58.210.78 - - [27/Jun/2025:17:55:11 +0000] "GET /css/typography.css HTTP/1.1"
200 3377 "https://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36"(其实它就是一行;这里为了便于阅读拆成了多行。)这一行里信息很多。要解读它,需要参照日志格式定义:
$remote_addr - $remote_user [$time_local] "$request"
$status $body_bytes_sent "$http_referer" "$http_user_agent"也就是说,这一行说明:在 2025 年 6 月 27 日 17:55:11 UTC,服务器收到来自客户端 IP 216.58.210.78 的请求,要求访问文件 /css/typography.css。用户未认证,因此 $remote_user 为连字符(-)。响应状态为 200(请求成功),大小为 3,377 字节。浏览器是 Chrome 137;之所以加载了这个文件,是因为它被 https://martin.kleppmann.com/ 这一页引用。
解析日志看似无关紧要,实际上却是许多现代科技公司运维中的关键一环——从广告管线到支付处理无所不在。事实上,日志解析正是 MapReduce 与"大数据"运动迅速兴起背后的推动力之一。
简单的日志分析
各种工具都能拿这些日志文件生成漂亮的网站流量报告,但作为练习,我们就用基本 Unix 工具自己做一个。例如,要找出网站上访问量最高的 5 个页面,可以在 Unix shell 里这样做:
cat /var/log/nginx/access.log | ❶
awk '{print $7}' | ❷
sort | ❸
uniq -c | ❹
sort -r -n | ❺
head -n 5 ❻❶ 读取日志文件。(严格说 cat 在这里不是必须的,输入文件本可以直接作为参数传给 awk。但写成这样把线性管线表达得更清楚。)
❷ 按空白把每行切成字段,仅输出第七个字段——它正是被请求的 URL。在我们的示例行中,这个 URL 是 /css/typography.css。
❸ 对所请求 URL 列表按字母序 sort。排序的目的是:如果某个 URL 被请求过 n 次,排序后的文件中这个 URL 就会连续出现 n 次。
❹ uniq 命令通过比较相邻两行是否相同来过滤重复行;加上 -c 选项让它同时输出计数:对每个不同的 URL,报告它在输入中出现了多少次。
❺ 第二次 sort 按行首的数字(-n)排序,也就是该 URL 被请求的次数;并以逆序(-r)输出——次数最多的排在最前。
❻ 最后 head 只输出前 5 行(-n 5),其余丢弃。
整套命令的输出大致是这样:
4189 /favicon.ico
3631 /2016/02/08/how-to-do-distributed-locking.html
2124 /2020/11/18/distributed-systems-and-elliptic-curves.html
1369 /
915 /css/typography.css如果你不熟悉 Unix 工具,上面这串命令也许看起来有些古怪,但它非常强大——可在数秒内处理数 GB 的日志文件,且能轻松调整以满足不同需求。例如要从报表中排除 CSS 文件,把 awk 参数改成 $7 !~ /\.css$/ {print $7} 即可;要统计访问量最高的客户端 IP 而非 URL,则改成 {print $1};其他需求也大体类似。
本书篇幅有限,无法深入介绍 Unix 工具,但它们非常值得学习:许多数据分析任务用 awk、sed、grep、sort、uniq、xargs 的组合,几分钟便能搞定,效果出乎意料地好 [8]。
命令链 vs 自定义程序
除了用 Unix 命令链,你也可以写个简单程序做同样的事。例如用 Python 大致是这样:
from collections import defaultdict
counts = defaultdict(int) # ❶
with open('/var/log/nginx/access.log', 'r') as file:
for line in file:
url = line.split()[6] # ❷
counts[url] += 1 # ❸
top5 = sorted(((count, url) for url, count in counts.items()),
reverse=True)[:5] # ❹
for count, url in top5: # ❺
print(f"{count} {url}")❶ 把 counts 初始化为一个哈希表,用来记录每个 URL 出现过的次数;每个计数初值为 0。
❷ 取出日志当前行中第七个空白分隔字段,即所请求的 URL(数组下标为 6,因为 Python 数组从 0 开始)。
❸ 给当前行中那个 URL 的计数器加 1。
❹ 按计数值从大到小排序,取前五条。
❺ 打印这前五条。
这段程序不像 Unix 命令链那么简洁,但读起来也清晰;选哪种风格部分是品味问题。然而二者除了表面句法的差异之外,执行流程也大不相同——一旦你在大文件上跑这一分析,差异就会显现。
排序 vs 内存聚合
Python 脚本在内存中维护一张以 URL 为键、以出现次数为值的哈希表;Unix 管线方案没有这张哈希表,而是靠排序让同一 URL 的多次出现连续排在一起。
哪种做法更好?取决于你有多少个不同的 URL。对多数中小型网站,所有不同的 URL 加上每个 URL 的计数器大概都能装进——比方说——1 GB 内存。本例中作业的工作集(即作业需要随机访问的内存量)只取决于不同 URL 的数量:某个 URL 即便有一百万条日志条目,在哈希表里也只占一个 URL 加一个计数器的空间。只要工作集足够小,内存哈希表就够用——哪怕在笔记本上也跑得动。
反之,若作业的工作集大于可用内存,排序方案的优势就显现出来:它能高效利用磁盘。这与第 118 页"日志结构存储"中讨论的原理相同:先在内存里把数据块排序、写成磁盘上的段文件,再把多个有序段以归并方式合并成更大的有序文件。归并排序具备良好的顺序访问模式,对磁盘特别友好(见第 130 页"SSD 的顺序写 vs 随机写")。
GNU Coreutils(Linux)中的 sort 工具会自动处理超过内存的数据集——把数据溢写到磁盘——并自动跨多个 CPU 核并行排序 [9]。这意味着前面那串简单的 Unix 命令可以轻松扩展到大数据集而不会撑爆内存;瓶颈很可能只在于"输入文件从磁盘读出来"的速率。
Unix 工具的局限在于只能运行在单台机器上。对于无法装入内存或本地磁盘的数据集,就要请出分布式批处理框架了。
分布式系统中的批处理
运行那个 Unix 工具示例的机器上,有几个组件协同处理日志数据:
- 通过操作系统文件系统接口访问的存储设备
- 一个调度器,决定何时运行进程、如何为它们分配 CPU 资源
- 一组 Unix 程序,其标准输入与标准输出(
stdin与stdout)通过管道相连
分布式数据处理框架中也有同样这些组件。事实上,你完全可以把这些框架视为分布式操作系统:它们也有文件系统、有作业调度器、有彼此通过文件系统或其他通信通道传递数据的程序。
分布式文件系统
操作系统提供的文件系统由若干层构成:
- 最底层是块设备驱动,直接和磁盘打交道,让上层能读写原始块。
- 块层之上有一个页缓存,把最近访问过的块保存在内存里以便更快访问。
- 块 API 又被一层文件系统包裹,把大文件切成块、并跟踪 inode、目录、文件等元数据。Linux 上常见的实现有 ext4 和 XFS。
- 最后,操作系统通过一种叫虚拟文件系统(VFS)的统一 API 把不同的文件系统暴露给应用——VFS 让应用可以用同一种方式读写,而无须关心底层是哪种文件系统。
分布式文件系统大体以同样方式工作:文件被切成块(block)、分布在多台机器上。DFS 块通常远大于本地文件系统的块——HDFS 默认 128 MB,JuiceFS 与许多对象存储用 4 MB 块——都比 ext4 的 4096 字节大得多。块越大,要跟踪的元数据越少,这在 PB 级数据集上影响巨大;块越大,相对每次读所摊销的寻道开销也越低。
多数物理存储设备无法写入"半个块",因此操作系统要求写操作占用整块——即便数据填不满它。分布式文件系统由于块大得多、且通常构建在操作系统文件系统之上,并没有这一限制。例如一个 900 MB 的文件按 128 MB 分块,会占用七个 128 MB 块加一个 4 MB 块。
读取 DFS 块时,要向集群中持有该块的机器发起网络请求。每台机器上都运行着一个守护进程,对外提供 API,让远程进程能把这些块当作本地文件系统上的文件来读写。HDFS 把这些守护进程叫 DataNode,GlusterFS 叫 glusterfsd 进程。本书统称它们为数据节点。
分布式文件系统也实现了页缓存的分布式版本。由于 DFS 块以文件形式存放在数据节点上,每个数据节点的操作系统都会经过其内存页缓存——常被读取的数据块自然会缓存在数据节点内存中。一些分布式文件系统还实现了更多缓存层级,比如 JuiceFS 中的客户端缓存与本地磁盘缓存。
ext4、XFS 等文件系统会跟踪存储元数据:可用空间、文件块位置、目录结构、权限等等。分布式文件系统也需要一种方式来跟踪散落在多台机器上的文件块位置、权限等信息。Hadoop 用一个叫 NameNode 的服务维护集群元数据;DeepSeek 的 3FS 则用一个把数据持久化到 FoundationDB 这类键值存储里的元数据服务。
文件系统之上是 VFS。批处理中与之最相近的对应物是分布式文件系统的协议。分布式文件系统必须暴露一种协议或接口,让批处理系统能借此读写文件。这种协议扮演可插拔接口的角色——只要某个 DFS 实现了它,批处理系统便可以使用。例如 Amazon S3 的 API 已被 MinIO、Cloudflare 的 R2、Tigris、Backblaze 的 B2 等多种存储系统广泛采用,支持 S3 的批处理系统都能挂上述任一存储。
还有一些 DFS 实现了 POSIX 兼容的文件系统——对操作系统的 VFS 而言,它们看起来与其他文件系统无异。要把它们接入 VFS 通常用 FUSE(用户空间文件系统)或 NFS(网络文件系统)协议。NFS 大概是最知名的分布式文件系统协议,最初设计目的是让多个客户端读写单台服务器上的文件。近来,Amazon EFS、Archil 等文件系统也提供了具备远更好可扩展性的 NFS 兼容分布式文件系统实现:NFS 客户端仍连接到一个端点,其底层则与分布式元数据服务和数据节点通信,完成数据的读写。
分布式文件系统与网络存储
分布式文件系统采用的是无共享原则(见第 51 页"共享内存、共享磁盘与无共享架构"),与网络附加存储(NAS)和存储区域网络(SAN)那种共享磁盘的做法形成对照。共享磁盘存储依赖一台中心化存储设备实现——常常使用定制硬件与如 Fibre Channel 之类的特殊网络基础设施;而无共享方式不需要任何特殊硬件,只要计算机通过常规数据中心网络相连即可。
许多分布式文件系统都建立在商品硬件之上——比企业级硬件便宜,但故障率也更高。为容忍机器与磁盘故障,文件块会在多台机器上做副本。这也让调度器能更均衡地分配工作负载,因为它可以把任务调度到任一持有该任务输入数据副本的节点。
副本既可以简单地在多台机器上保留若干份相同数据(如第 6 章所述),也可以采用 Reed–Solomon 码这类纠删码方案——以比完整副本更低的存储开销恢复丢失数据 [10, 11, 12]。这与 RAID 的思路类似(RAID 用同机多盘提供冗余),区别在于:分布式文件系统中文件访问与副本是通过常规数据中心网络完成的,无需特殊硬件。
对象存储
Amazon S3、Google Cloud Storage、Azure Blob Storage、OpenStack Swift 等对象存储服务,已成为批处理作业中分布式文件系统的流行替代。事实上两者的界线相当模糊:如上一节及第 202 页"由对象存储支撑的数据库"所见,FUSE 驱动允许把 S3 这类对象存储当成文件系统使用;一些 DFS 实现(如 JuiceFS、Ceph)同时提供对象存储与文件系统两种 API。然而它们的 API、性能与一致性保证差异极大。采用这类系统时务必小心,确认其实际行为符合预期——即便表面上看起来实现了相同 API。
对象存储中的每个对象都有一个 URL,例如 s3://my-photo-bucket/2025/04/01/birthday.png。URL 中的主机部分(my-photo-bucket)描述对象所在的 bucket,其后部分是对象的 key(示例中为 /2025/04/01/birthday.png)。bucket 拥有全局唯一的名字;同一 bucket 内每个对象的 key 也必须唯一。
对象通过 get 调用读取、put 调用写入。与文件系统中的文件不同,对象一旦写入便不可变:要更新对象,必须用一次 put 把它整个重写——这与键值存储类似。Azure Blob Storage 与 S3 Express One Zone 支持追加,其他大多数都不支持。对象存储也没有 fopen、fseek 这类基于文件句柄的 API。
对象表面上看似被组织在目录里,这点容易让人困惑——因为对象存储中并没有"目录"概念。它的路径结构只是一种约定,斜杠是 key 的一部分。借助这一约定,你可以做类似目录列表的事——按某前缀列出对象。但前缀列举与文件系统的目录列表有两点不同:
- 前缀
list操作的行为更像 Unix 上的ls -R:它会返回所有以该前缀开头的对象,包括位于更深子路径中的对象。 - 没有"空目录"这一概念。如果你把 s3://my-photo-bucket/2025/04/01/ 下所有对象都删掉,那么对 s3://my-photo-bucket/2025/04/ 调用
list时01就不再出现。常见做法是创建一个零字节对象作为"空目录占位符"(例如建一个名为 s3://my-photo-bucket/2025/04/01 的文件,让该路径在子对象都被删掉后仍可见)。
DFS 实现通常支持硬链接、软链接、文件锁、原子重命名等常见文件系统操作;对象存储则普遍缺这些特性——一般不支持链接与锁,重命名也不是原子的,得靠把对象复制到新 key 再删掉旧对象来完成。要"重命名"一个目录就得逐个对象重命名,因为目录名本就是 key 的一部分。
第 4 章中讨论的键值存储是为小值(通常几千字节)以及频繁低延迟读写而优化的;相较之下,分布式文件系统与对象存储一般针对大对象(兆字节到吉字节)以及频度较低的较大读做了优化。不过近来对象存储也开始支持频繁的小读小写——例如 S3 Express One Zone 现已提供单毫秒延迟,定价模型也更接近键值存储。
分布式文件系统与对象存储的另一处差别在于:HDFS 这类 DFS 允许把计算任务跑在持有相应文件副本的那台机器上,读取该文件时无需经网络传输——这通常能省下相当多带宽,因为任务的可执行代码往往比要读的文件小得多。对象存储则普遍把存储与计算分离。这种做法或许耗费更多带宽,但现代数据中心网络非常快,往往可以接受;这样的架构还允许 CPU、内存等机器资源与存储独立扩展,因为两者已经解耦。
分布式作业编排
我们的"操作系统类比"同样适用于作业编排。执行一个 Unix 批处理时,必须有什么东西去真正启动 awk、sort、uniq、head 这些进程。数据要从一个进程的输出传到另一个的输入;每个进程都要分配内存;它们的指令要被公平调度并在 CPU 上执行;内存与 I/O 边界要被强制执行——等等。单机上这些工作由操作系统内核完成;在分布式环境下,则是作业编排器(job orchestrator)的职责。
批处理框架向编排器的调度器发起请求来跑作业。请求中携带的元数据包括:
- 要执行的任务数量
- 每个任务需要的内存、CPU 与磁盘
- 作业标识符
- 访问凭证
- 作业参数,如输入与输出数据
- 所需硬件细节,如 GPU 或磁盘类型
- 作业可执行代码的位置
像 Kubernetes 与 Hadoop YARN(Yet Another Resource Negotiator)[13] 这样的编排器把上述信息与集群元数据结合起来,借助以下组件来执行作业:
任务执行器
像 YARN 的 NodeManager 或 Kubernetes 的 kubelet 这样的执行器守护进程运行在集群的每个节点上。执行器负责执行作业的任务、发心跳以表明自身存活,并跟踪节点上任务的状态与资源分配。一旦收到启动任务的请求,它就拉取作业的可执行代码、用命令把任务启动起来;之后持续监控该进程直到它结束或失败,并相应更新任务状态元数据。
许多执行器还与操作系统协作以提供安全与性能隔离。例如 YARN 与 Kubernetes 都使用 Linux cgroups——既防止任务在无权限时访问数据,也防止某个任务因占用过多资源而拖累节点上的其他任务。
资源管理器
编排器的资源管理器存放每个节点的元数据:可用硬件(CPU、GPU、内存、磁盘等)、任务状态、网络位置、节点状态以及其他相关信息——由此提供集群当前状态的全局视图。资源管理器的中心化特性可能成为可扩展性与可用性的瓶颈。YARN 用 ZooKeeper 存集群状态,Kubernetes 用 etcd(见第 437 页"协调服务")。
调度器
编排器通常带有一个中心化的调度器子系统,接收启动、停止、查询作业状态的请求。例如调度器可能收到这样的请求:"用某个 Docker 镜像在带有特定 GPU 的节点上启动 10 个任务的作业。"调度器据此并结合资源管理器中的状态,决定哪些任务跑在哪些节点上;随后任务执行器会被告知自己分到的工作并开始执行。
不同编排器术语各异,但这些组件你几乎能在所有编排系统中找到。
调度决策有时需要考虑应用特定的需求——例如某查询达到一定阈值时为其自动扩容只读副本。中心化调度器与应用专属调度器协同合作,决定如何最优地执行任务。YARN 把它的子调度器称为 ApplicationMaster,Kubernetes 中则叫 operator。
资源分配
调度器在作业编排中扮演的角色特别有挑战:要在多个相互竞争的需求之间,决定如何最优地分配集群有限的资源。从根本上讲,这些决策必须在公平与效率之间取得平衡。
设想一个由 5 个节点、共 160 个 CPU 核组成的小集群。调度器收到两个作业请求,每个都想用 100 个核来完成自己的工作。怎样调度最合适?
- 调度器可以为每个作业先跑 80 个任务,等先前任务完成时再启动各自剩余的 20 个。
- 调度器也可以先把一个作业的全部任务跑完,再开始第二个作业的任务——仅当 100 个核都可用时才启动。这种策略叫整组调度(gang scheduling)。
- 如果第二个作业请求晚得多才到,调度器掌握的信息便不完整:它必须决定是把全部 100 个核都给第一个作业,还是预留一些核以备未来未必到来的作业。
这只是一个非常简单的例子,但已能看出许多艰难的取舍。在整组调度场景中,若调度器非要凑齐 100 核才启动,节点便会闲下来,集群资源利用率会降低;其他作业要是也想预留 CPU 核,还可能酿成死锁。
反过来,如果调度器只是干等 100 核空出来,其他作业可能在期间把这些核抢走;很长一段时间集群中可能始终凑不齐 100 个核,导致饥饿。或者调度器干脆抢占第一个作业的部分任务,杀掉它们为第二个作业腾出空间——但抢占同样降低集群效率,因为被杀掉的任务以后还得重启。
再设想调度器要为成百上千、乃至数百万个这样的作业请求做分配决策——找最优解便是不堪重负的难题。事实上这是 NP 难问题,意味着除最小规模的例子外,计算最优解都太慢 [14, 15]。
实践中调度器因此采用启发式方法,做出虽非最优但合理的决策。常用算法包括 FIFO(先进先出)、主导资源公平(DRF)、优先级队列、容量/配额调度,以及各种装箱算法。这些算法的细节超出本书范围,但属于一个引人入胜的研究领域。
调度工作流
第 454 页"简单的日志分析"中的 Unix 工具示例由若干命令通过 Unix 管道连成。分布式批处理中也常见同样的模式:一个作业的输出经常要作为另一个或多个作业的输入,每个作业也可能有多个来自其他作业的输入。这就叫工作流,或作业的有向无环图(DAG)。
第 187 页"持久执行与工作流"中我们见过为一系列有序步骤(通常是发 RPC)提供持久执行的工作流引擎。在批处理语境下,"工作流"含义不同:它是一系列批处理过程,每个吞入输入数据、产出输出数据,但通常不向外部服务发 RPC。持久执行引擎每次请求处理的数据量通常远少于其批处理对应物,不过两者界线相当模糊。
工作流之所以由多个作业组成,原因有以下几种:
- 如果某个作业的输出要被多个其他作业(且由不同团队维护)当作输入,最好让第一个作业把输出写到一个所有后续作业都能读到的位置;这些消费作业便可在数据更新或按各自计划运行时被调度。
- 你可能希望把数据从一种处理工具传到另一种。例如某个 Spark 作业把数据输出到 HDFS,再由一个 Python 脚本触发 Trino SQL 查询(见第 135 页"云数据仓库")对这些 HDFS 文件做进一步处理,结果输出到 S3。
- 有些数据流水线本身就需要多个处理阶段。例如某一阶段按某个键分片、下一阶段按另一个键分片——上一阶段就把数据按下一阶段所需的方式分片输出。
Unix 工具示例里,把一个命令输出连到下一个命令输入的管道只用一个内存中的小缓冲区,并不落盘。缓冲区满时,生产者进程必须等消费者从缓冲区读走一些数据才能继续输出——这是一种背压。Spark、Flink 等批处理执行引擎也支持类似模型:一个任务的输出直接交给下一个任务(任务跨机时则经网络传输)。
不过更典型的做法是:工作流里一个作业把输出写到分布式文件系统或对象存储中,下一个作业再从那里读取。这样作业彼此解耦,可以在不同时间运行。如果一个作业有多个输入,工作流调度器通常会等所有产生输入的作业都成功完成后,再跑那个消费这些输入的作业。
YARN 的 ResourceManager、Spark 自带调度器这类编排框架内的调度器并不管理整条工作流——它们只在单个作业的粒度上调度。为了管理这些跨作业依赖,业界发展出多种工作流调度器,如 Airflow、Dagster、Prefect。它们具备的管理能力在维护大量批作业时很有用:50 到 100 个作业组成的工作流在许多数据流水线中十分常见,大型组织里许多团队甚至还会跨多个系统跑互相读取对方输出的作业或工作流。在这种复杂数据流的管理上,工具支持至关重要。
处理故障
批作业往往跑得很久。一个带有大量并行任务的长跑作业,沿途至少出现一次任务失败几乎是必然的。如第 44 页"硬件与软件故障"以及第 347 页"不可靠的网络"所讨论,故障可能源自硬件问题(在商品硬件上尤甚)或网络中断。
任务无法跑完的另一个原因是:调度器有意抢占(杀掉)它。抢占在存在多种优先级时尤其有用——便宜的低优先级任务与昂贵的高优先级任务并存。低优先级任务可在有空闲算力时随时启动,但一旦高优先级任务到来,它们随时可能被抢占。这类便宜的低优先级虚拟机分别被称为:Amazon EC2 上的 spot 实例、Azure 上的 spot 虚拟机、Google Cloud 上的抢占式实例[16]。
由于批处理常用于不那么时间敏感的作业,它非常适合用低优先级任务与 spot 实例降低运行成本——本质上这类作业利用了原本空闲的算力,提升了集群利用率。代价是它们被调度器杀掉的概率远高于硬件故障 [17]。
由于批作业每次运行都从零生成输出,任务失败比在线系统里更容易处理:系统可以删掉失败任务产生的部分输出,再把任务调度到另一台机器上重跑。当然,仅因单个任务失败就把整个作业重跑就太浪费了。MapReduce 及其继承者因此让并行任务的执行彼此独立,使工作能在单任务粒度上重试 [3]。
当工作流里某任务的输出又要作为另一任务的输入时,容错就更棘手。MapReduce 的解法是:始终把这种中间数据写回分布式文件系统,并等写入任务成功后才允许其他任务读取。这种做法即便在常见抢占的环境中也能工作,但代价是 DFS 上写得很多、效率欠佳。
Spark 把中间数据保留在内存(装不下时"溢出"到本地磁盘),只把最终结果写回 DFS;它还会追踪中间数据是如何算出来的,丢失时可以重新算回来 [18]。Flink 采用另一种思路:周期性地对任务做快照检查点 [19]。第 468 页"数据流引擎"会回到这一话题。
批处理模型
我们已经看过批作业在分布式环境下是如何调度的。下面把目光转向批处理框架如何处理数据。最常见的两种模型是 MapReduce 与数据流引擎。尽管数据流引擎在实践中已大体取代 MapReduce,理解 MapReduce 仍有意义——它的思想影响了许多现代批处理框架的工作方式。
MapReduce 与数据流引擎都演化出对多种编程模型的支持,包括底层编程式 API、关系查询语言以及 DataFrame API。这一系列选择让应用工程师、分析工程师、业务分析师乃至非技术人员都能为各种用例处理公司数据——这些用例我们将在第 476 页"批处理用例"中讨论。
MapReduce
MapReduce 的数据处理模式与第 454 页"简单的日志分析"中的 Web 服务器日志分析示例非常相似:
- 读入一组输入文件并切成记录。在 Web 服务器日志示例中,每条记录是日志中的一行(即
\n是记录分隔符)。在 Hadoop 的 MapReduce 中,输入文件存放于 HDFS 这样的分布式文件系统或 S3 这样的对象存储中,使用诸如 Apache Parquet(列式格式,见第 136 页"列式存储")或 Apache Avro(行式格式,见第 172 页"Avro")等多种文件格式。 - 调用 mapper 函数从每条输入记录中提取 key 与 value。Unix 工具示例中 mapper 函数就是
awk '{print $7}'——把 URL($7)作为 key 提取出来,value 留空。 - 把所有键值对按 key 排序。日志示例中,这一步由第一次
sort命令完成。 - 调用 reducer 函数遍历这些已排好序的键值对。如果同一个 key 出现多次,排序使它们在列表中相邻,因此 reducer 可以把这些值合并起来而无须在内存中保留太多状态。Unix 工具示例中 reducer 由命令
uniq -c实现——它统计相邻具有相同 key 的记录数。
这四步可由一个 MapReduce 作业完成。第 2 步(map)与第 4 步(reduce)是你写自定义数据处理代码的地方;第 1 步(把文件切成记录)由输入格式解析器负责;第 3 步(sort)在 MapReduce 里是隐式的——你不必写它,因为 mapper 的输出在交给 reducer 之前总会被排好序。这一排序步骤是一种基础性的批处理算法,第 469 页"打乱数据"会进一步讨论。
要写一个 MapReduce 作业,需要实现两个回调函数 mapper 与 reducer,行为如下:
Mapper
mapper 对每条输入记录都被调用一次,职责是从记录中提取 key 与 value。每个输入它可以产生任意数量(也可以零个)的键值对。它不会跨记录保留状态,因此每条记录被独立处理。一份输入可以被多个 mapper 并行处理,每个 mapper 处理输入的一部分。
Reducer
MapReduce 框架收下各个 mapper 产生的键值对、把同一 key 的所有 value 收集到一起,再用一个能遍历这组 value 的迭代器调用 reducer。reducer 可产生输出记录(例如某 URL 出现的次数)。不同 key 的 reducer 也可以并行运行。
在 Web 服务器日志示例中,第 5 步还有一次 sort——它按请求次数对 URL 排序。在 MapReduce 里要再做一次排序,可以另写一个 MapReduce 作业,把上一个作业的输出当作输入。从这个角度看,mapper 的角色是把数据准备好、整理成适合排序的形式;reducer 的角色则是处理排好序后的数据。
MapReduce 与函数式编程
虽然 MapReduce 用于批处理,其编程模型却来自函数式编程。Lisp 把
map与reduce(或fold)作为列表的高阶函数引入,这两者后来也进入了 Python、Rust、Java 等主流语言。包括 SQL 提供的许多常见数据处理操作都可以在 MapReduce 之上实现。函数式编程中"避免可变状态"的原则有助于实现并行执行:每次对 mapper 与 reducer 的调用都只依赖框架显式传入的数据,因此框架可以自由地把彼此独立的调用并行跑在不同节点上。任务失败时,框架也可以在另一个节点上用同样的输入再次调用 mapper 与 reducer。
用原始的 MapReduce API 实现一个复杂处理作业其实相当费力——例如作业里要用的任何 join 算法都得从零写起 [20]。MapReduce 与更现代的批处理器相比也相当慢;原因之一是它基于文件的 I/O 阻碍了作业的流水化(即在上游作业尚未完成时就开始处理其输出)。
数据流引擎
为解决 MapReduce 的若干问题,业界开发出新一代分布式批计算执行引擎——其中最著名的是 Spark [18, 21] 与 Flink [19]。它们设计各异,但有一个共同点:把整条工作流视为一个作业来处理,而不是拆成彼此独立的子作业。
由于这类系统显式地把数据在多个处理阶段间的流动建模出来,它们被称为数据流引擎。与 MapReduce 类似,它们也支持底层 API——反复调用一个用户定义函数逐条处理记录;同时还提供 join、group by 等更高层算子。它们通过对输入分片来并行化工作,并把一个任务的输出经网络发给另一个任务作为输入。与 MapReduce 不同的是,算子不必严格交替地扮演 map 与 reduce 的角色,而能以更灵活的方式组合。
数据流 API 通常用关系式的基本构件来表达计算:按字段值连接数据集;按 key 分组元组;按条件过滤;以计数、求和或其他函数聚合元组。在内部,这些操作借助我们下一节要讨论的 shuffle 算法实现。
这类处理引擎源自 Dryad [22]、Nephele [23] 等研究系统,相比 MapReduce 模型有若干优势:
- 像排序这种昂贵的操作只在确实需要的地方执行,而不是默认在每对 map 与 reduce 之间都做一次。
- 当若干算子接连工作且都不改变数据集分片(如 map 或 filter)时,可以合并成一个任务,减少数据复制开销。
- 由于工作流中所有的 join 与数据依赖都被显式声明,调度器对"哪里需要哪些数据"有全局视图,从而能做局部性优化。例如它可以尝试把消费某些数据的任务放到产生该数据的同一台机器上,让数据通过共享内存缓冲区交换,而无需经网络复制。
- 算子之间的中间状态通常保留在内存里、或写到本地磁盘上即可;相比写到分布式文件系统或对象存储(要复制到多机、每副本都落盘),I/O 开销小得多。MapReduce 已经对 mapper 输出采用了这一优化,数据流引擎则把这一思想推广到了所有中间状态。
- 算子只要输入就绪就能开始执行,不必等前一阶段整个完成才启动下一阶段。
- 已有进程可以被复用来跑新算子,相比 MapReduce(每个任务都要拉起一个新 JVM)大大减少了启动开销。
你可以用数据流引擎实现与 MapReduce 工作流一样的计算,由于上述种种优化,通常执行得显著更快。
打乱数据
如我们所见,本章开头的 Unix 工具示例与 MapReduce 都基于排序。批处理器需要能对 PB 级、超出单机容量的数据集排序,因此需要分布式排序算法——其输入与输出都是分片的。这种算法被称为 shuffle。
Shuffle 并不"随机"
术语 shuffle 可能让人误解。打牌时洗牌(shuffle)是让牌变成随机顺序;而我们这里说的 shuffle 产生的是有序结果,没有任何随机性。
shuffle 是批处理器的基础算法,用于 join 和聚合。MapReduce、Spark、Flink、Daft、Dataflow、BigQuery [24] 都实现了可扩展的高性能 shuffle 算法以处理大数据集。下面以 Hadoop MapReduce 中的 shuffle 为例 [25],本节概念同样适用于其他系统。
图 11-1 展示了一个 MapReduce 作业的数据流。假设作业的输入是分片的,分片标记为 m1、m2、m3。例如每个分片可以是 HDFS 上的一个独立文件,或对象存储里的一个独立对象——同一数据集的所有分片归在同一个 HDFS 目录下,或在对象存储 bucket 里共用同一 key 前缀。
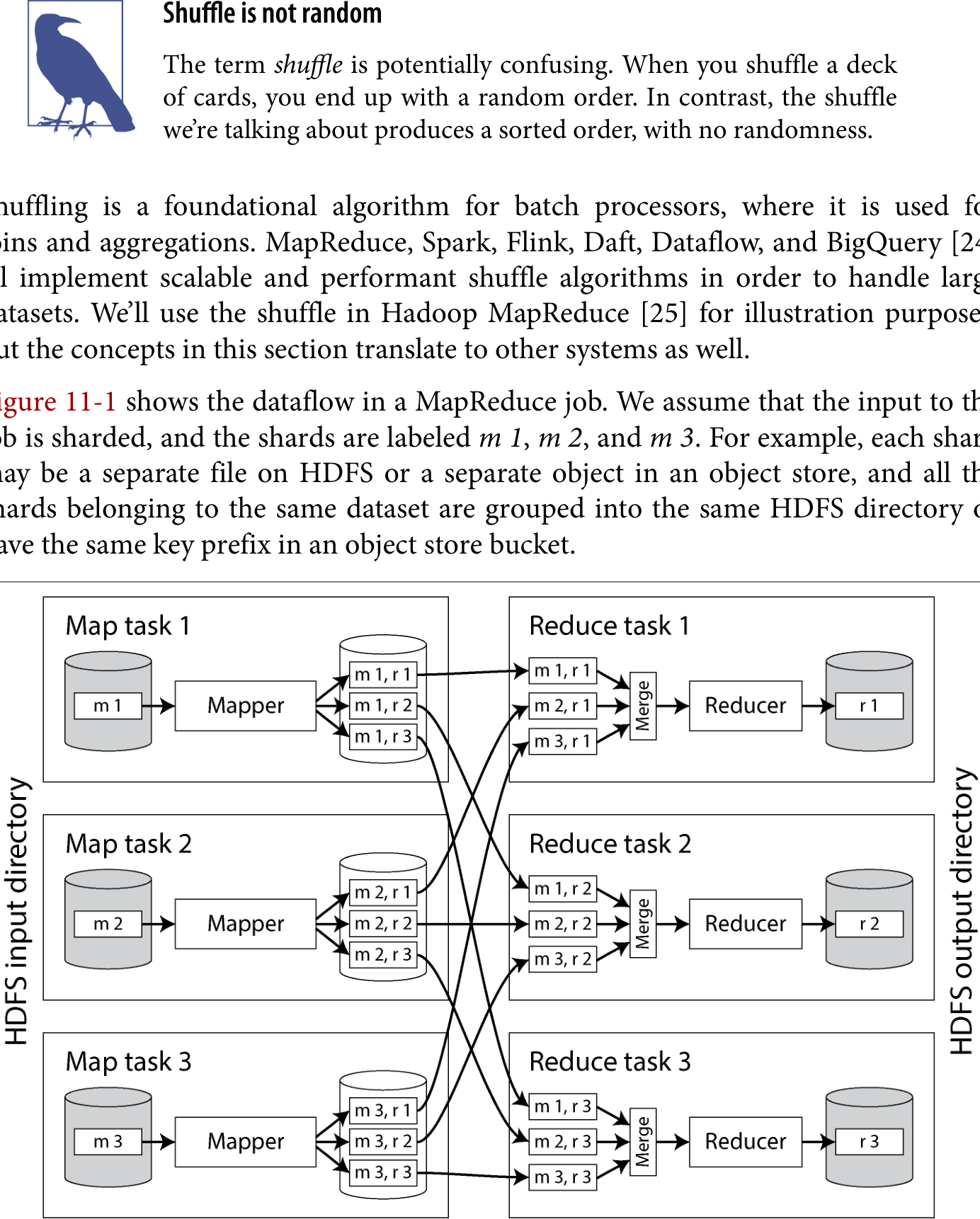
图 11-1. 含三个 mapper 与三个 reducer 的 MapReduce 作业 框架为每个输入分片启动一个独立的 map 任务。任务读取所分配的文件,把记录逐条传给 mapper 回调。reduce 一侧的计算同样是分片的——map 任务数由输入分片数决定,reduce 任务数则由作业作者配置(可与 map 任务数不同)。
mapper 的输出是键值对。框架必须确保:若两个 mapper 输出了相同 key,这些键值对最终要被同一个 reduce 任务处理。为此每个 mapper 都会为每个 reducer 在本地磁盘上创建一份独立的输出文件(如图 11-1 中文件 m1, r2 即 mapper 1 为发往 reducer 2 的数据创建的文件)。mapper 输出键值对时,由该 key 的哈希值决定它落入哪个 reducer 文件(与第 258 页"按 key 哈希分片"所述方式类似)。
mapper 写这些文件的同时,还会把每个文件内的键值对排好序。可以借助第 118 页"日志结构存储"中介绍的技术:先在内存中用有序数据结构收集成批的键值对,再把它们写成有序的段文件,最后把较小段文件逐步合并成更大的有序段。
每个 mapper 完成后,reducer 会连过来、把对应的有序键值对文件复制到本地磁盘。一旦 reduce 任务拿到来自全部 mapper 的输出份额,它便以归并排序的方式合并这些文件,保持有序。同 key 的键值对自然连续出现,即便它们来自不同 mapper。reducer 函数随后被对每个 key 调用一次,附带一个能遍历该 key 全部 value 的迭代器。
reducer 函数输出的任何记录都顺序写入文件,每个 reduce 任务一份输出文件(如图 11-1 中的 r1、r2、r3)。这些文件构成该作业输出数据集的分片,写回分布式文件系统或对象存储。
虽然 MapReduce 在 map 与 reduce 步之间执行 shuffle,现代数据流引擎与云数据仓库要更精巧。BigQuery 这类系统优化了 shuffle 算法,让数据尽量留在内存中,必要时也可写到外部排序服务 [24]——这类服务能加速 shuffle,并通过对 shuffle 后的数据做复制提供韧性。
Join 与分组
下面看排好序的数据如何简化分布式 join 与聚合。我们继续以 MapReduce 举例,这些概念同样适用于多数批处理系统。
图 11-2 展示了批作业中 join 的一个典型例子:左侧是一份事件日志,描述登录用户在网站上做的事情(即活动事件或点击流数据);右侧是一个用户数据库。可以把这一例子视为星型模式(见第 77 页"星型与雪花型分析模式")的一部分:事件日志是事实表,用户数据库是其中一个维度。
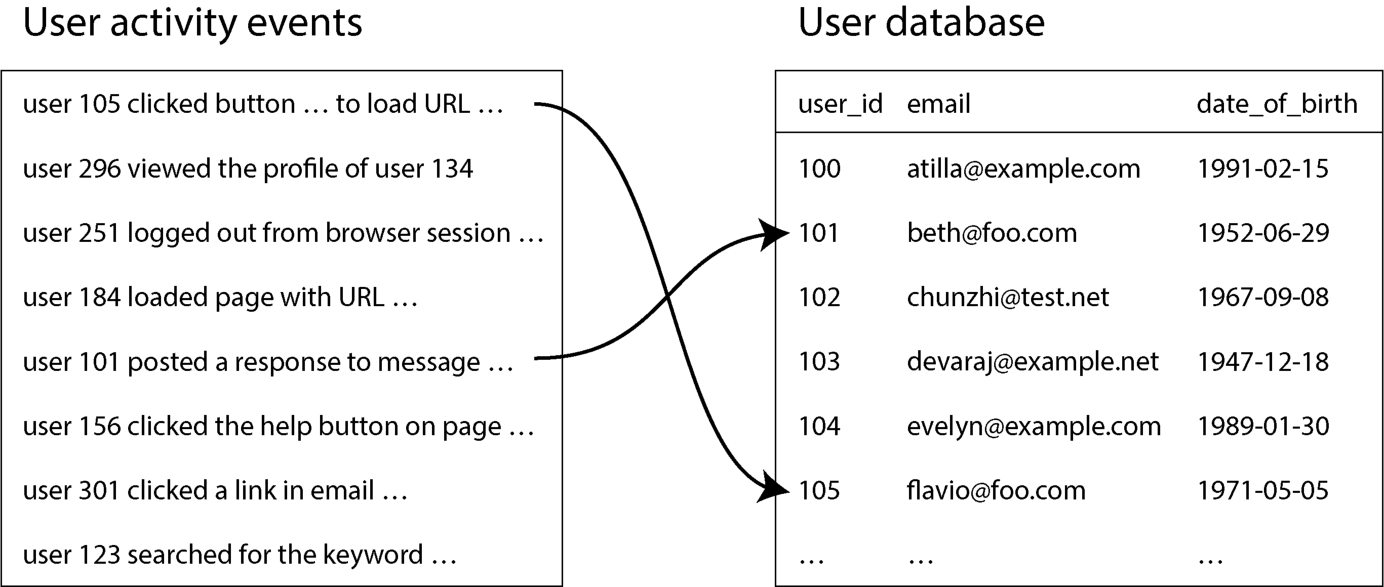
图 11-2. 用户活动事件日志与用户资料数据库之间的 join 要在分析这些活动事件时把用户数据库中的信息也一并考虑进来(例如查看某些页面在年长或年轻用户中是否更受欢迎,需要用到用户资料里的 date_of_birth 字段),就得在两张表之间算一个 join。当两张表都太大、必须分片时,这一 join 怎么算?
可以利用 MapReduce 的一个事实:shuffle 会把同一 key 的所有键值对汇聚到同一个 reducer,无论它们最初在哪个分片上。这里我们用 user ID 作 key。于是可以写一个 mapper 遍历用户活动事件、按 user ID 输出页面浏览 URL(如图 11-3);再写一个 mapper 逐行遍历用户数据库,把 user ID 当作 key、用户的 date_of_birth 当作 value。
shuffle 之后,reducer 函数便能同时拿到某用户的 date_of_birth 与该用户全部页面浏览事件。MapReduce 作业还可以把记录预先排好序,让 reducer 总是先看到来自用户数据库的那条记录,再按时间戳顺序看到活动事件——这一技巧叫做二次排序[25]。
接下来 reducer 就能轻松完成 join 逻辑:第一个 value 应是 date_of_birth,reducer 把它存进局部变量;之后遍历活动事件,把每个被访问的 URL 与浏览者的出生日期一并输出。由于 reducer 一次性处理某 user ID 的所有记录,它任意时刻只需在内存中保留一条用户记录,也无需走网络发请求。这种算法叫排序-归并连接(sort-merge join)——mapper 输出已按 key 排好序,reducer 再把 join 两侧的有序记录列表归并到一起。
工作流中下一个 MapReduce 作业便可算出每个 URL 上浏览者年龄的分布。它先以 URL 为 key 把数据 shuffle;reducer 排序后遍历某 URL 上所有页面浏览(带上浏览者的出生日期),为每个年龄段维护一个计数器、按每次浏览给相应计数器加 1。这样就实现了"按 key 分组并聚合"的操作。
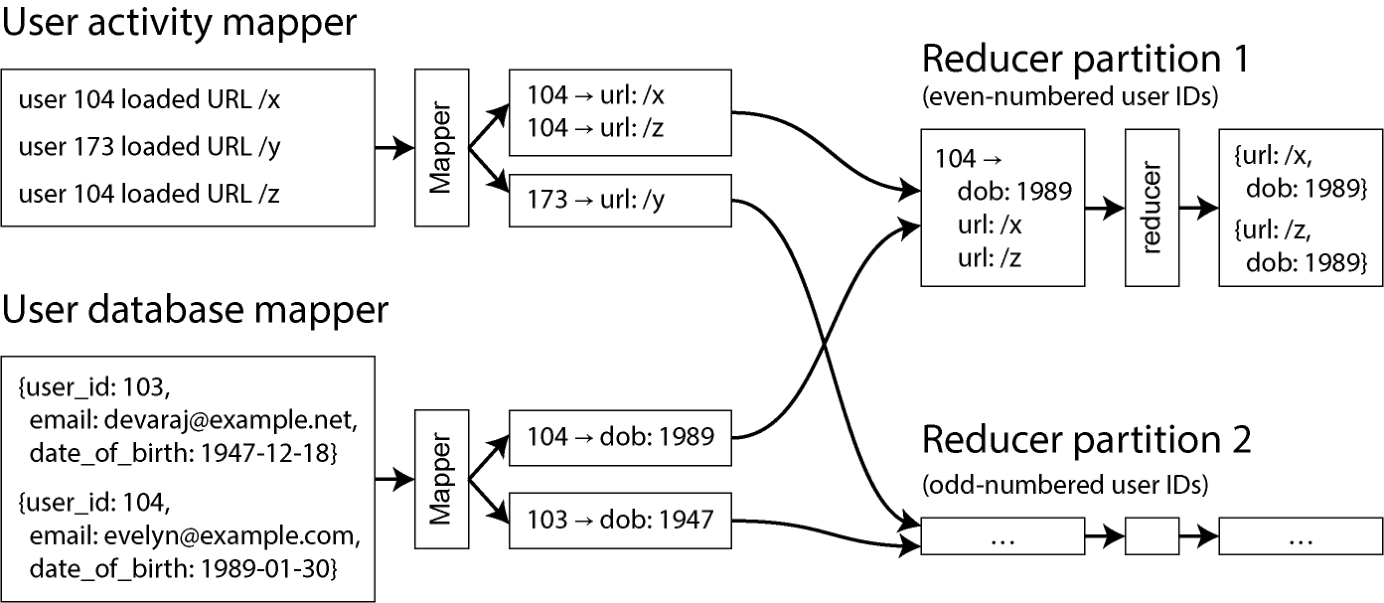
图 11-3. 基于 user ID 的 sort-merge join;如果输入数据集分成多个文件,每个文件可由多个 mapper 并行处理
查询语言
多年来,分布式批处理执行引擎已逐步成熟。基础设施已稳健到能在一万多台机器组成的集群上存储与处理 PB 级数据。批处理的物理执行问题大体被解决之后,注意力随之转向编程模型的改进。
MapReduce、数据流引擎、云数据仓库都把 SQL 视为批处理的通用语言。这是自然之选:传统数据仓库使用 SQL,数据分析与 ETL 工具早已支持 SQL,所有开发者与分析师也都熟悉它。
除了代码量远少于手写 MapReduce 作业,这些查询语言接口还支持交互式使用——你在终端或图形界面里写分析查询并立刻跑起来。对于在批处理环境中探查数据的业务分析师、产品经理、销售与财务团队来说,这种交互式查询是一种高效而自然的方式。SQL 支持也让分布式批处理系统适合做探索性查询。
高层查询语言不仅让人更高效,也在机器层面提升执行效率。如第 135 页"云数据仓库"所见,查询引擎负责把 SQL 查询翻译成在集群上执行的批作业;这一从查询到语法树再到物理算子的翻译让引擎得以对查询进行优化。Hive、Trino、Spark、Flink 等查询引擎都具备基于代价的查询优化器,能分析 join 输入的特性、自动选择最合适的算法;优化器甚至可能调换 join 顺序,以最小化中间状态量 [19, 26, 27, 28]。
虽然 SQL 是最流行的通用批处理查询语言,其他语言仍服务于细分需求。例如 Apache Pig 是一种基于关系算子的语言,允许把数据流水线一步步定义出来,而非写成一条庞大的 SQL 查询。DataFrames(下一节讨论)也具备类似特性;Morel 是一种受 Pig 启发的更现代语言。还有些用户采用了 jq、JMESPath、JSONPath 等 JSON 查询语言。
第 84 页"图状数据模型"中我们讨论过用图建模数据、用图查询语言遍历图的边与节点。许多图处理框架也通过 Apache TinkerPop 的 Gremlin 等查询语言支持批量图计算。第 476 页"批处理用例"会更详细讨论图处理场景。
批处理与云数据仓库的融合
历史上数据仓库运行在专用硬件设备之上,支持对关系数据的 SQL 分析查询。MapReduce 这类批处理框架则致力于以更强的可扩展性与灵活性见长——支持用通用编程语言写处理逻辑、读写任意数据格式。
时至今日两者已愈发相似。现代批处理框架把 SQL 当作写批作业的语言,并通过 Parquet 这类列式存储格式与经过优化的查询执行引擎(见第 142 页"查询执行:编译与向量化")在关系数据上取得良好性能。与此同时,数据仓库迁移到云上后扩展性大增(见第 135 页"云数据仓库"),还采纳了与分布式批处理框架相同的许多调度、容错与 shuffle 技术——不少甚至直接使用分布式文件系统。
正如批处理系统采纳了 SQL 作为处理模型,数据仓库也开始采纳其他处理模型。例如 BigQuery 提供 DataFrames 库,Snowflake 的 Snowpark 库与 Pandas 集成。Airflow、Prefect、Dagster 等批处理工作流编排器也与云数据仓库集成。
不过并非所有批作业都能轻松用 SQL 表达,包括 PageRank 这类迭代图算法、复杂的 ML 任务以及许多其他工作流。AI 数据处理涉及非关系、多模态数据(如图像、视频、音频),用 SQL 表达同样很困难。
云数据仓库在某些工作负载上也力不从心。列式存储格式做逐行计算效率较低,这种情形下用其他仓库 API 或批处理系统更合适。云数据仓库的成本通常也比其他批处理系统更高。把大型作业放到 Spark 或 Flink 这类批处理系统中跑,往往更划算。
最终,"在批处理系统还是数据仓库里处理数据"这一决定,通常取决于成本、便利性、实现难度与可用性等因素。多数大企业拥有许多数据处理系统,因而在这一决定上有灵活性;小公司常常一个就够了。
DataFrames
数据科学家与统计学家通常习惯使用 R 与 Pandas 中的 DataFrame 数据模型(见第 105 页"DataFrames、矩阵与数组")。DataFrame 类似关系数据库中的表:是行的集合,同一列中所有值具有相同类型。用户不必写一条大 SQL 查询,而是调用对应于关系算子的函数来完成过滤、连接、排序、聚合等操作。
最初 DataFrame 操作通常在本地内存中进行,因此只能处理单机能装下的数据集。数据科学家希望在批处理环境中操作大数据集时仍沿用熟悉的 DataFrame API,因为 SQL 与 MapReduce 对他们的需求都不太契合。于是 Spark、Flink、Daft 等分布式数据处理框架引入了 DataFrame API。不过它们的实现行为略有不同:本地 DataFrame 通常带索引且有序,而分布式 DataFrame 一般不是 [29]。这可能让用户在迁移到批处理框架时遭遇性能上的意外。
DataFrame API 表面看类似数据流 API,实现却差异不小。Pandas 在 DataFrame 方法被调用时立即执行;Spark 则先把所有 DataFrame API 调用翻译成查询计划、跑一遍查询优化,再在它的分布式数据流引擎上执行整个工作流。
Daft 这类框架甚至支持客户端与服务端两侧执行:较小的内存内操作在客户端跑,较大的数据集发到服务器处理。Apache Arrow 这类列式存储格式则为客户端与服务端执行引擎提供了一个共享的统一数据模型。
批处理用例
看完批处理的工作原理之后,我们来看看它如何被应用到不同领域。批作业擅长大批量处理大数据集,但不适合低延迟场景。因此凡是数据量大、对新鲜度要求不那么高的地方,都常能见到批作业。听起来限制颇多,但实际上相当多的数据处理任务恰好符合这一模型。例如:
- 财务与库存对账——企业核对交易与银行账目、库存的一致性——常以批作业完成 [30]。
- 制造业中的需求预测通常作为周期性批作业运行 [31]。
- 电商、媒体与社交媒体公司用批作业训练推荐模型 [32, 33]。
- 许多金融系统都以批处理为主;例如美国银行网络几乎完全靠批作业运转 [34]。
下面几节讨论几乎在每个行业都能见到的几种批处理用例。
抽取-转换-加载(ETL)
第 7 页"数据仓库"介绍过 ETL 与 ELT——由一条数据处理管线从生产数据库抽取数据、做转换,再把结果加载到下游系统(本节我们用"ETL"代指 ETL 与 ELT 两类工作负载)。批作业常被用来跑这类负载,尤其当下游系统是数据仓库时。
批作业天然具备并行性,非常适合数据转换——许多转换属于"令人尴尬地并行"的工作负载。过滤数据、投影字段,以及大量其他常见的数据仓库转换都能并行执行。
批处理环境还附带稳健的工作流调度器,使 ETL 数据流水线作业便于调度、编排与调试。失败时调度器常会重试以缓解瞬时问题;屡试屡败的作业则会被标记为失败——开发者由此能一眼看出数据流水线在哪一步卡住。Airflow 这类调度器甚至内置了对 MySQL、PostgreSQL、Snowflake、Spark、Flink 等数十种流行系统的输入、输出与查询算子。调度器与数据处理系统的紧密集成大大简化了数据集成。
我们也看到批作业在出错时易于排查与修复。这一特性在调试数据流水线时十分宝贵:失败的文件可以方便地被检视以定位问题,修好流水线后重跑 ETL 作业即可。例如,当转换批作业要用的某字段在输入文件中不存在时,数据工程师能轻松发现该字段缺失,并相应地更新转换逻辑以及生成该输入的作业。
数据流水线过去通常由单一数据工程团队管理——让其他做产品特性的团队来写并维护复杂批处理流水线被认为不公平。近来批处理模型与元数据管理的改进大大降低了门槛,让组织内的工程师都能参与并管理自己的数据流水线。数据网格(data mesh)[35, 36]、数据契约(data contract)[37]、数据编织(data fabric)[38] 等实践提供了标准与工具,帮助团队安全地把数据发布给组织内任何使用者。
数据流水线与分析查询不仅开始共用处理模型,连执行引擎也开始共用。如今许多 ETL 作业跑在与读取其输出的分析查询同样的系统上;数据流水线转换与分析查询同时以 SparkSQL、Trino、DuckDB 查询的形式运行也并不少见。这类架构进一步模糊了应用工程、数据工程与业务分析之间的界线。
分析
如第 3 页"运营系统与分析系统"所见,分析查询(OLAP)常常扫描大量记录、做分组与聚合。分析负载完全可以与其他批处理负载一起跑在批处理系统中。分析师写 SQL 查询,跑在某个查询引擎之上,引擎再读写分布式文件系统或对象存储。表元数据(如表到文件的映射、列名、列类型)由 Apache Iceberg 这类表格式与 Unity 这类 catalog 管理(见第 135 页"云数据仓库")。这一架构被称为数据湖仓(data lakehouse)[39]。
与 ETL 一样,SQL 查询接口的改进也让许多组织开始把 Spark 这类批处理框架用于分析。这类查询模式有两种风格:
预聚合查询
把数据汇聚(roll up)到 OLAP cube 或数据集市以加快查询(见第 143 页"物化视图与数据立方体")。预聚合数据要么在数据仓库内被查询,要么推送到 Apache Druid、Apache Pinot 这类专为实时 OLAP 而生的系统去查。预聚合通常按计划间隔执行;第 464 页"调度工作流"中讨论的工作流调度器就用来管理这类负载。
临时查询
用户跑这类查询回答具体业务问题、调查用户行为、调试运维问题等等。响应时间在这类用例里很重要——分析师一边迭代地跑查询、一边收到响应、加深对所研究数据的理解。具备快速查询执行能力的批处理框架能缩短分析师的等待时间。
SQL 支持也让批处理框架能与电子表格以及 Tableau、Power BI、Looker、Apache Superset 这类数据可视化工具集成。例如 Tableau 提供 SparkSQL 与 Presto 连接器,Apache Superset 支持 Trino、Hive、Spark SQL、Presto 等许多以批作业为底层查询执行的系统。
机器学习
机器学习(ML)频繁使用批处理。数据科学家、ML 工程师、AI 工程师用批处理框架来探查数据模式、转换数据、训练 ML 模型。常见用途包括:
特征工程
把原始数据过滤、转换为可供模型训练的数据。预测模型通常需要数值输入,工程师必须把其他形式的数据(文本、离散值)转换成所需格式。
模型训练
训练数据是批处理的输入,训练好的模型权重是输出。
批量推理
在数据集很大、且不要求实时结果的场景下,可以用训练好的模型做批量预测——也包括在测试集上评估模型预测。
批处理框架显式地为这些用例提供工具。例如 Apache Spark 的 MLlib、Apache Flink 的 FlinkML 都自带种类丰富的特征工程工具、统计函数与分类器。
推荐引擎、排序系统等 ML 应用也大量用到图处理(见第 84 页"图状数据模型")。许多图算法的工作方式是逐条遍历边——把某顶点与相邻顶点 join 一次以传播信息——并不断重复直到满足某条件,比如不再有可走的边、或某指标收敛。
在为图做批处理时,整体同步并行(BSP)计算模型 [40] 已颇为流行;它由 Apache Giraph [20]、Spark 的 GraphX API、Flink 的 Gelly API [41] 等实现。它也被称为 Pregel 模型——Google 的 Pregel 论文让这一图处理思路广为人知 [42]。
批处理也是大语言模型数据准备与训练的重要环节。原始文本输入数据(通常是网站内容)一般存放在 DFS 或对象存储中,必须经过预处理才能用于训练。适合用批处理框架完成的预处理步骤包括:
- 从 HTML 中提取纯文本、修复格式不规范的文本。
- 检测并剔除低质量、不相关、重复的文档。
- 对文本做分词(拆成单词),并将其转为嵌入或每个词的数值表示。
Kubeflow、Flyte、Ray 等批处理框架专为此类负载设计。例如 OpenAI 在 ChatGPT 训练流程中就使用 Ray [43]。这类框架内置对 PyTorch、TensorFlow、XGBoost 等 LLM 与 AI 库的集成,也对特征工程、模型训练、批量推理与微调(针对特定用例调整基础模型)提供原生支持。
最后,数据科学家常在 Jupyter、Hex 这类交互式 notebook 中实验数据。Notebook 由 cell 组成——一段段 Markdown、Python 或 SQL 片段;cell 顺序执行,产生电子表格、图或数据。许多 notebook 通过 DataFrame API 或 SQL 查询系统借力于批处理。
服务派生数据
批作业常被用来构建预先算好或派生的数据集,例如商品推荐、面向用户的报表、ML 模型特征。这些数据集通常由生产数据库、键值存储或搜索引擎来提供服务。无论使用哪种系统,预先算好的数据都得从批处理器的分布式文件系统或对象存储里回到那个对外服务线上流量的数据库中。
你也许会想:直接在批作业里使用心仪数据库的客户端库、把记录一条条写进数据库服务器就行了。这虽行得通(前提是防火墙允许从批处理环境直接访问生产数据库),却是个糟糕的主意,原因有几条:
- 每条记录都发一次网络请求,比批处理任务的常规吞吐慢好几个数量级。即便客户端库支持批量提交,性能多半也好不到哪里去。
- 批处理框架经常并行跑很多任务。如果所有任务都按批处理预期速率并发地往同一个目标数据库里写,数据库很容易被压垮,查询性能也跟着受影响——进而引发系统其他部分的运维问题 [44]。
- 通常批作业会为输出提供干净的"全有或全无"保证:作业成功时,结果是每个任务恰好执行一次所产生的输出(即便途中有任务失败、重试过);作业失败时则不产生任何输出。但向作业之外的系统写入会造成无法隐藏的可见副作用——你就得担心部分完成的作业产生的中间结果对其他系统是否可见;某任务失败重启时,输出还可能与上一次失败执行重复。
更好的做法是让批作业把预先算好的数据集推送到 Kafka 这类流系统中(第 12 章会详细讨论)。Elasticsearch 这类搜索引擎、Apache Pinot 与 Apache Druid 这类实时 OLAP 系统、Venice [45] 这类派生数据存储、ClickHouse 这类云数据仓库都内建了从 Kafka 摄入数据的能力。通过流系统推送数据可解决上面提到的若干问题:
- 流系统针对顺序写做了优化,更适合批作业那种大批量写入。
- 流系统可在批作业与生产数据库之间充当缓冲。下游系统能限速读取流,确保仍能从容服务生产流量。
- 单个批作业的输出可被多个下游系统消费。
- 流系统可充当批处理环境与生产网络之间的安全边界,部署在所谓的隔离区(DMZ)——位于批处理网络与生产网络之间。
流系统本身并不能天然解决"全有或全无"保证。要做到这一点,批作业完成时必须给下游系统发一条通知,告知作业已完成、数据可对外服务。流的消费者要能把从流中收到的数据先对查询隐藏起来——就像读已提交隔离级别下尚未提交的事务(见第 290 页"读已提交")——直到收到"作业完成"的通知。
另一种在引导新数据库时更常见的模式是:在批作业内部直接构建一个全新的数据库,再把这些文件从分布式文件系统、对象存储或本地文件系统批量加载进数据库。许多数据系统都提供批量导入工具,如 TiDB 的 Lightning、Apache Pinot 的 Hadoop 导入作业;RocksDB 也提供把批作业产出的 Sorted String Table(SST)文件批量导入的 API。
用批处理构建数据库、做批量导入速度非常快,还让系统在数据集版本之间的原子切换变得更容易。但相比从零构建新数据库,这种方式较难对批作业产出的数据集做增量更新。当你既需要"引导"又需要"增量加载"时,常见的做法是把两者结合起来。例如 Venice 支持混合存储——既允许按行批量更新,也允许整张数据集替换。
总结
本章我们考察了批处理系统的设计与实现。一开始借助经典的 Unix 工具链(awk、sort、uniq 等)阐释了排序、计数等基础的批处理原语。
接着我们扩展到分布式批处理系统。批处理框架处理不可变、有界的输入数据集,产出输出数据,整个过程允许重跑与调试,且无副作用。这一处理涉及三大组件:决定作业何时何地运行的编排层、持久化数据的存储层,以及实际处理数据的计算层。
我们看了分布式文件系统与对象存储如何通过基于块的复制、缓存与元数据服务来管理大文件,以及现代批处理框架如何通过可插拔 API 与这些系统交互。我们还讨论了作业编排器如何调度任务、分配资源、处理大集群中的故障,并把它们与管理由依赖关系组成的作业图生命周期的工作流编排器作了对比。
我们考察了批处理模型——从 MapReduce 及其经典的 map 与 reduce 函数开始,再转向 Spark、Flink 这类数据流引擎,它们提供更易用的数据流 API 与更好的性能。为理解批作业如何扩展,我们讨论了 shuffle 算法——支撑分组、连接与聚合的基础操作。
我们看到,随着批处理系统的成熟,重心转向了易用性。SQL、DataFrame API 等高层查询语言被引入,使批作业更易上手与优化。批处理框架接收用这些语言写的作业,自动决定如何在机器集群上高效执行。
本章最后我们综览了常见的批处理用例,包括:
- ETL 流水线——通过预定的工作流在系统间抽取、转换、加载数据
- 分析——批作业既支持预聚合查询,也支持临时查询
- 机器学习——批作业用来准备并处理大型训练数据集
- 通过流或批量加载工具把批输出灌进面向生产的系统,向用户提供派生数据
下一章我们将转入流处理——其输入是无界的,即作业的输入是永不停息的数据流。这意味着作业永远不会真正"完成",因为更多数据可能随时进来。我们会看到流处理与批处理在某些方面相似,但"输入是无界流"这一假设对系统的构建方式影响深远。
参考文献
[1] Nathan Marz. "How to Beat the CAP Theorem." nathanmarz.com, October 2011. 归档于 perma.cc/4BS9-R9A4
[2] Molly Bartlett Dishman and Martin Fowler. "Agile Architecture." 见 O'Reilly Software Architecture Conference, March 2015.
[3] Jeffrey Dean and Sanjay Ghemawat. "MapReduce: Simplified Data Processing on Large Clusters." 见 6th USENIX Symposium on Operating System Design and Implementation (OSDI), December 2004.
[4] Shivnath Babu and Herodotos Herodotou. "Massively Parallel Databases and MapReduce Systems." Foundations and Trends in Databases, volume 5, issue 1, pages 1–104, November 2013. doi:10.1561/1900000036
[5] David J. DeWitt and Michael Stonebraker. "MapReduce: A Major Step Backwards." 原载 databasecolumn.vertica.com, January 2008. 归档于 perma.cc/U8PA-K48V
[6] Henry Robinson. "The Elephant Was a Trojan Horse: On the Death of Map-Reduce at Google." the-paper-trail.org, June 2014. 归档于 perma.cc/9FEM-X787
[7] Urs Hölzle. "R.I.P. MapReduce. After having served us well since 2003, today we removed the remaining internal codebase for good." x.com, September 2019. 归档于 perma.cc/B34T-LLY7
[8] Adam Drake. "Command-Line Tools Can Be 235x Faster than Your Hadoop Cluster." aadrake.com, January 2014. 归档于 perma.cc/87SP-ZMCY
[9] "sort: Sort Text Files." GNU Coreutils 9.7 Documentation, Free Software Foundation, Inc., 2025. 归档于 perma.cc/68KN-E8TL
[10] Michael Ovsiannikov 等. "The Quantcast File System." Proceedings of the VLDB Endowment, volume 6, issue 11, pages 1092–1101, August 2013. doi:10.14778/2536222.2536234
[11] Andrew Wang 等. "Introduction to HDFS Erasure Coding in Apache Hadoop." blog.cloudera.com, September 2015. 归档于 archive.org
[12] Andy Warfield. "Building and Operating a Pretty Big Storage System Called S3." allthingsdistributed.com, July 2023. 归档于 perma.cc/7LPK-TP7V
[13] Vinod Kumar Vavilapalli 等. "Apache Hadoop YARN: Yet Another Resource Negotiator." 见 4th Annual Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523633
[14] Richard M. Karp. "Reducibility Among Combinatorial Problems." Complexity of Computer Computations, The IBM Research Symposia Series. Springer, 1972. doi:10.1007/978-1-4684-2001-2_9
[15] J. D. Ullman. "NP-Complete Scheduling Problems." Journal of Computer and System Sciences, volume 10, issue 3, pages 384–393, June 1975. doi:10.1016/S0022-0000(75)80008-0
[16] Gilad David Maayan. "The Complete Guide to Spot Instances on AWS, Azure and GCP." datacenterdynamics.com, March 2021. 归档于 archive.org
[17] Abhishek Verma 等. "Large-Scale Cluster Management at Google with Borg." 见 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741964
[18] Matei Zaharia 等. "Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing." 见 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), April 2012.
[19] Paris Carbone 等. "Apache Flink: Stream and Batch Processing in a Single Engine." Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, volume 38, issue 4, pages 28–38, December 2015. 归档于 perma.cc/G3N3-BKX5
[20] Mark Grover 等. Hadoop Application Architectures. O'Reilly Media, 2015. ISBN: 9781491900048
[21] Jules S. Damji 等. Learning Spark, 2nd edition. O'Reilly Media, 2020. ISBN: 9781492050049
[22] Michael Isard 等. "Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks." 见 2nd European Conference on Computer Systems (EuroSys), March 2007. doi:10.1145/1272996.1273005
[23] Daniel Warneke and Odej Kao. "Nephele: Efficient Parallel Data Processing in the Cloud." 见 2nd Workshop on Many-Task Computing on Grids and Supercomputers (MTAGS), November 2009. doi:10.1145/1646468.1646476
[24] Hossein Ahmadi. "In-Memory Query Execution in Google BigQuery." cloud.google.com, August 2016. 归档于 perma.cc/DGG2-FL9W
[25] Tom White. Hadoop: The Definitive Guide, 4th edition. O'Reilly Media, 2015. ISBN: 9781491901632
[26] Fabian Hüske. "Peeking into Apache Flink's Engine Room." flink.apache.org, March 2015. 归档于 perma.cc/44BW-ALJX
[27] Mostafa Mokhtar. "Hive 0.14 Cost Based Optimizer (CBO) Technical Overview." hortonworks.com, March 2015. 归档于 archive.org
[28] Michael Armbrust 等. "Spark SQL: Relational Data Processing in Spark." 见 ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2742797
[29] Kaya Kupferschmidt. "Spark vs. Pandas, Part 2—Spark." towardsdatascience.com, October 2020. 归档于 perma.cc/5BRK-G4N5
[30] Ammar Chalifah. "Tracking Payments at Scale." bolt.eu, June 2025. 归档于 perma.cc/Q4KX-8K3J
[31] Nafi Ahmet Turgut 等. "Demand Forecasting at Getir Built with Amazon Forecast." aws.amazon.com, May 2023. 归档于 perma.cc/H3H6-GNL7
[32] Jason (Siyu) Zhu. "Enhancing Homepage Feed Relevance by Harnessing the Power of Large Corpus Sparse ID Embeddings." linkedin.com, August 2023. 归档于 archive.org
[33] Avery Ching, Sital Kedia, and Shuojie Wang. "Apache Spark @Scale: A 60 TB+ Production Use Case." engineering.fb.com, August 2016. 归档于 perma.cc/F7R5-YFAV
[34] Edward Kim. "How ACH Works: A Developer Perspective—Part 1." engineering.gusto.com, April 2014. 归档于 perma.cc/F67P-VBLK
[35] Zhamak Dehghani. "How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh." martinfowler.com, May 2019. 归档于 perma.cc/LN2L-L4VC
[36] Chris Riccomini. "What the Heck Is a Data Mesh?!" cnr.sh, June 2021. 归档于 perma.cc/NEJ2-BAX3
[37] Chad Sanderson, Mark Freeman, and B. E. Schmidt. Data Contracts. O'Reilly Media, 2025. ISBN: 9781098157623
[38] Daniel Abadi. "Data Fabric vs. Data Mesh: What's the Difference?" starburst.io, November 2021. 归档于 perma.cc/RSK3-HXDK
[39] Michael Armbrust 等. "Lakehouse: A New Generation of Open Platforms That Unify Data Warehousing and Advanced Analytics." 见 11th Annual Conference on Innovative Data Systems Research (CIDR), January 2021. 归档于 perma.cc/7C6D-T9NR
[40] Leslie G. Valiant. "A Bridging Model for Parallel Computation." Communications of the ACM, volume 33, issue 8, pages 103–111, August 1990. doi:10.1145/79173.79181
[41] Stephan Ewen 等. "Spinning Fast Iterative Data Flows." Proceedings of the VLDB Endowment, volume 5, issue 11, pages 1268–1279, July 2012. doi:10.14778/2350229.2350245
[42] Grzegorz Malewicz 等. "Pregel: A System for Large-Scale Graph Processing." 见 ACM International Conference on Management of Data (SIGMOD), June 2010. doi:10.1145/1807167.1807184
[43] Richard MacManus. "OpenAI Chats About Scaling LLMs at Anyscale's Ray Summit." thenewstack.io, September 2023. 归档于 perma.cc/YJD6-KUXU
[44] Jay Kreps. "Why Local State Is a Fundamental Primitive in Stream Processing." oreilly.com, July 2014. 归档于 perma.cc/P8HU-R5LA
[45] Félix GV. "Open Sourcing Venice—LinkedIn's Derived Data Platform." linkedin.com, September 2022. 归档于 archive.org