第 8 章 事务
一些作者声称通用的两阶段提交开销太大、不值得支持,因为它会带来性能或可用性问题。我们认为:与其总是写代码去绕过"没有事务"这一限制,不如在出现瓶颈时让应用程序员去处理过度使用事务带来的性能问题。
—— James Corbett 等,《Spanner:Google 的全球分布式数据库》(2012)
在数据系统的残酷现实里,可能出错的事一大堆:
- 数据库软件或硬件随时都可能出毛病(包括写入到一半时)。
- 应用随时都可能崩溃(包括一连串操作执行到一半时)。
- 网络中断可能毫无预警地把应用与数据库切开,或把一个数据库节点与另一个切开。
- 多个客户端可能同时写入数据库,互相覆盖对方的修改。
- 客户端可能读到只完成了一部分更新、毫无意义的数据。
- 客户端之间的竞态条件可能引出意想不到的 bug。
要做到可靠,系统就得应对上述种种故障,避免它们演变成灾难性失败。然而实现容错机制是件吃力的活:必须仔细考虑各种可能出错的状况,并通过严格测试确认实现确实有效。
数十年来,事务一直是简化这些问题的首选机制。事务让应用把若干读写组合成一个逻辑单元。从概念上看,事务里的所有读写都作为一次操作执行:要么整个事务成功,结果是提交;要么失败,结果是中止或回滚。失败时应用可以安全地重试。有了事务,应用的错误处理就简单许多——不必再担心部分失败(出于种种原因,一些操作成功、另一些失败)。
如果你早已习惯事务,它也许显得理所当然,但我们不应把它当成天经地义。事务并非自然法则;它被发明出来,就是为了简化访问数据库的应用的编程模型。使用事务能让应用忽略某些潜在的错误场景与并发问题,因为这些都由数据库替你处理掉(这种保护我们称为安全保证)。
并非每个应用都需要事务,有时削弱事务保证甚至彻底放弃事务是有好处的(例如为追求更好的性能或更高的可用性)。某些安全属性没有事务也能达到。但反过来看,事务也能省去不少麻烦。例如英国邮局 Horizon 丑闻的技术原因之一(见第 48 页"可靠性有多重要?"),很可能就是底层会计系统缺少 ACID 事务 [1]。
怎么判断你需不需要事务?要回答这个问题,得先准确了解事务能提供哪些安全保证、又要付出什么代价。事务乍看简单,但里面有许多微妙却重要的细节。
并发控制对单节点数据库和分布式数据库都很关键。本章会深入这一话题,讨论各种可能发生的竞态条件,以及数据库如何实现读已提交、快照隔离、可串行化等隔离级别。我们还会考察两阶段提交协议,以及在分布式事务里实现原子性的种种挑战。
事务到底是什么?
如今几乎所有的关系型数据库以及部分非关系型数据库都支持事务。它们大多沿用 1975 年 IBM System R(第一个 SQL 数据库)引入的那一套 [2, 3, 4]。尽管一些实现细节已经演变,五十年来核心思想几乎没变:MySQL、PostgreSQL、Oracle、SQL Server 等系统的事务支持,跟 System R 出奇地相似。
2000 年代后期非关系型(NoSQL)数据库开始走红。它们想改进关系型数据库的现状:提供新的数据模型(见第 3 章),并默认带上复制和分片(见第 6、7 章)。事务是这场运动的主要牺牲品:那一代数据库不少完全抛弃了事务,或把这个词重新定义成远比传统所知更弱的一组保证。
围绕 NoSQL 分布式数据库的炒作让一种说法广为流传:事务从根本上无法扩展,任何大规模系统都必须放弃事务才能维持良好的性能与可用性。这一观点近些年已被证伪:CockroachDB [5]、TiDB [6]、Spanner [7]、FoundationDB [8]、YugabyteDB 等所谓"NewSQL"数据库表明,事务系统完全可以扩展到大数据量与高吞吐。它们把分片与共识协议(见第 10 章)结合在一起,在大规模下仍能提供强 ACID 保证。
不过这并不代表每个系统都必须支持事务。与其他技术选择一样,事务有优势也有局限。要理清这些取舍,本章会细致讨论事务在正常运行以及各种极端(却现实)情形下能给出哪些保证。
ACID 的含义
事务提供的安全保证常用一个广为人知的缩写 ACID 来描述,它是原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)的首字母组合。这一术语由 Theo Härder 与 Andreas Reuter 在 1983 年提出 [9],目的是为数据库的容错机制建立精确说法。
但实际上,不同数据库对 ACID 的实现各不相同。例如下面会看到,隔离性的含义就相当模糊 [10]。高层思想合情合理,但魔鬼藏在细节里。如今一个系统宣称自己 "ACID 兼容",你到底能指望哪些保证已经说不清了——"ACID" 不幸已沦为营销术语。
不符合 ACID 标准的系统有时被称作 BASE——基本可用(basically available)、软状态(soft state)和最终一致性(eventual consistency)[11]。这比 ACID 还要含糊。BASE 唯一靠谱的定义大概就是"不是 ACID"(也就是几乎能指代任何东西)。
下面就逐一展开原子性、一致性、隔离性、持久性,以厘清"事务"这个概念。
原子性
一般而言,原子指不可再分。这个词在计算的不同分支里意义相似但略有不同。例如在多线程编程里,如果某线程执行了一个原子操作,意味着其他线程根本不可能看到该操作的"半成品"——系统状态要么是操作之前、要么是操作之后,没有中间态。
但在 ACID 语境下,原子性与并发无关。它并不刻画多个进程同时访问同一数据时会发生什么——那是隔离性的范畴(见第 281 页"隔离性")。
ACID 的原子性描述的是:客户端想做一系列写入,但中途发生了故障——例如进程崩溃、网络断开、磁盘满、违反完整性约束——这时会怎样。如果这些写入被组成原子事务、又因故障无法完成(提交),事务就会被中止,数据库必须丢弃或撤销该事务已经写入的所有更改。
没有原子性,一连串更改做到一半出错时,就很难判断哪些生效了、哪些没生效。应用当然可以重试,但有些更改可能被执行两次,造成数据重复或错误。原子性把这件事简化了:事务一旦中止,应用就能确信"什么都没改",于是可以安心重试。
"一旦出错就中止事务并丢弃所有写入"这一能力,正是 ACID 原子性的定义性特征。或许用 abortability(可中止性)比 atomicity(原子性)更贴切,但既然 atomicity 已是惯用词,我们也沿用。
一致性
"一致性"这个词被严重过载使用:
- 第 6 章讨论过副本一致性及异步复制系统中出现的最终一致性问题(见第 209 页"复制延迟带来的问题")。
- 数据库的一致快照指数据库在某一时刻状态的快照,例如做备份时所用。更准确地说,一致快照与 happens-before 关系一致(见第 238 页"happens-before 关系与并发"):若快照中包含某一时刻写入的某个值,那它必须同时反映先于该值发生的所有写入。
- 一致性哈希是某些系统用于再均衡的分片方法(见第 263 页"一致性哈希")。
- 在 CAP 定理(见第 10 章)里,"一致性"指的是线性一致性(linearizability)(见第 402 页"线性一致性")。
- 在 ACID 语境下,一致性指数据库处于应用所定义的"良好状态"。
可惜同一个词至少要表达上面这五种含义。
ACID 一致性的思想是:你对数据有某些必须始终成立的命题(不变量)——例如会计系统里所有账户的贷方与借方加起来必须永远平衡。如果事务开始时数据库就满足这些不变量,并且事务期间所有写入都保持这些不变量成立,那么不变量就会一直被满足。(事务执行过程中不变量可以暂时被打破,但事务结束时必须重新满足。)
要让数据库去强制执行不变量,就得把它们以约束(constraints)的形式写进模式。外键约束、唯一性约束、检查约束(限制某列允许的取值)等就常被用来建模特定类型的不变量。更复杂的一致性需求有时可以用触发器或物化视图来表达 [12]。
不过,复杂的不变量未必能用数据库通常提供的约束建模出来。这时,写出能保持一致性的事务就是应用自己的责任。如果你写了违反不变量的"坏写入"却没把这些不变量声明出来,数据库帮不了你。也就是说,ACID 里的 C 往往取决于应用如何使用数据库,而不只是数据库本身的属性。
隔离性
大多数数据库都会被多个客户端同时访问。如果它们读写的是数据库的不同部分,倒还好;但若它们访问的是同一条记录,就会遇到并发问题(竞态条件)。
图 8-1 给出了一个简单的例子。假设两个客户端同时把数据库中保存的计数器加 1。每个客户端要先读当前值、加 1、再把新值写回(假设数据库没有内置的 increment 操作)。图 8-1 里两次 increment 都发生了,计数器本应从 42 涨到 44,但因为竞态条件,实际只涨到了 43。
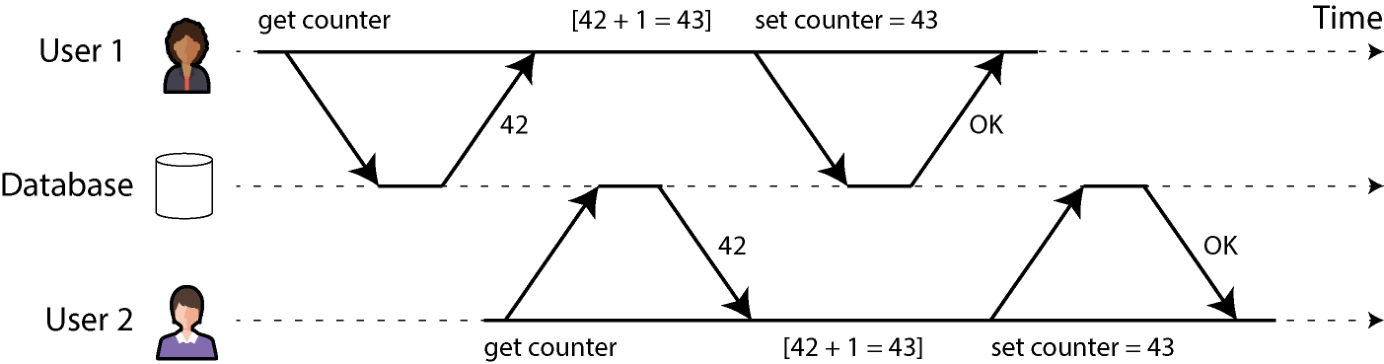
图 8-1. 两个客户端同时增加计数器引发的竞态条件。 ACID 意义上的隔离性是指:并发执行的事务彼此隔离,互不踩脚。经典数据库教材把隔离性形式化为可串行化(serializability)——每个事务都可以假装自己是数据库上唯一在跑的事务。数据库要保证:事务提交后的结果,与它们一个接一个串行执行的结果完全一致,哪怕实际上是并发执行的 [13]。
但可串行化是有性能代价的。实际中许多数据库使用比可串行化更弱的隔离形式——也就是允许并发事务以有限方式互相干扰。一些常见数据库(如 Oracle)甚至根本不实现可串行化(Oracle 有一个叫 "serializable" 的隔离级别,实际上是快照隔离——比可串行化弱)[10, 14]。这意味着某些竞态条件仍可能发生。我们将在第 288 页"弱隔离级别"讨论快照隔离与其他隔离形式。
持久性
数据库系统存在的目的,就是给你一个能安全存放数据、不必担心丢失的地方。持久性承诺:事务一旦成功提交,它写入的任何数据都不会被遗忘——即便发生硬件故障或数据库崩溃也是如此。
在单节点数据库中,持久性通常意味着数据已写入非易失性存储(如硬盘或 SSD)。常规文件写入通常先在内存里缓冲,过一段时间才落盘,因此突然断电时可能丢失;许多数据库为此使用 fsync 系统调用,确保数据真的落到了磁盘。数据库通常还备有预写日志或类似特性(见第 127 页"让 B 树可靠"),以便在写入中途崩溃时仍能恢复。许多数据库(如 MySQL、MongoDB、PostgreSQL)会连同校验和一起存储数据,从而能识别出损坏或不完整的日志条目,帮助崩溃后把数据库恢复到一致快照。
在复制式数据库中,持久性可能意味着数据已成功复制到若干节点。要兑现持久性保证,数据库必须等这些写入或复制完成,才能向客户端报告事务提交成功。然而正如第 43 页"可靠性与容错"所述,完美的持久性并不存在;要是所有硬盘和所有备份同时被毁,数据库显然救不了你。
复制与持久性
历史上,"持久性"意味着写到归档磁带;后来变成写到磁盘或 SSD;最近又被改造成复制。到底哪种实现更好?
真相是没有哪一种完美无缺:
- 只写到一台机器的磁盘上,机器一旦挂掉,数据虽然还在,却要等到机器修好或把盘搬到另一台机器上才能访问。复制系统则能保持可用。
- 关联故障——例如断电,或一个 bug 让所有副本同时崩在同一个输入上(见第 43 页"可靠性与容错")——会让仅留在内存里的数据丢失。所以即便做了复制,把数据落盘仍然重要。
- 异步复制系统里,主节点失效时近期写入可能丢失(见第 204 页"处理节点宕机")。
- 已经有人发现,SSD 在突然断电时有时会违背它声称的保证;甚至 fsync 也不一定能正确工作 [15]。磁盘固件可能有 bug,和其他软件一样 [16, 17]——例如让磁盘正好在运行 32,768 小时后失败 [18]。fsync 自己也很难用对;连 PostgreSQL 都误用了它 20 多年 [19, 20, 21]。
- 存储引擎与文件系统之间细微的相互作用可能引发难以追踪的 bug,让崩溃后磁盘上的文件损坏 [22, 23]。某个副本上的文件系统错误有时还会扩散到其他副本 [24]。
- 磁盘上的数据可能被悄无声息地损坏 [25, 26]。如果损坏已经持续一段时间,副本和近期备份也会跟着损坏,这时只能尝试从更早的备份中恢复。
- 一项研究发现,30% 到 80% 的 SSD 在使用的前四年里至少会出现一处坏块,而其中只有一部分能被固件修正 [27]。机械硬盘坏扇区率较低,但整体失效率比 SSD 更高。
- 严重磨损的 SSD(经历过大量写/擦循环)一旦断电,可能在几周到几个月内开始丢数据,具体取决于温度 [28]。磨损较少的盘问题要小一些 [29]。
实际上,没有任何单一技术能给出绝对保证。我们能做的只是采用各种降低风险的方法——写盘、复制到远端机器、做备份——这些方法应当并且可以同时使用。一如既往,对理论上的"保证"保留一点怀疑是明智的。
单对象与多对象操作
回顾一下,ACID 中的原子性与隔离性描述的是:客户端在同一事务里做多次写入时,数据库该如何处理:
原子性
如果一连串写入做到一半出错,事务就该被中止,到此为止已做的写入应被丢弃。换句话说,数据库用"全成功或全不做"的保证把你从担心部分失败中解放出来。
隔离性
并发执行的事务不应彼此干扰。例如某个事务做了多次写入,那么另一个事务要么全部看到这些写入,要么一个也看不到,而不能只看到其中的一部分。
这些定义假定你要一次修改多个对象(行、文档、记录)。这种多对象事务经常出现在多块数据需要保持同步的场景。图 8-2 给出了邮件应用的例子。要给某个用户显示未读邮件数,你可以这样查询:
SELECT COUNT(*) FROM emails WHERE recipient_id = 2 AND unread_flag = true但邮件一多,这个查询就可能慢得让你受不了,于是你决定把未读数存到一个独立字段(一种反规范化,见第 72 页"规范化、反规范化与 join")。这样每来一封新邮件就要把未读计数器加 1,每把某封邮件标为已读就要减 1。
图 8-2 中,用户 2 看到了一种异常:邮箱列表里显示有未读邮件,计数器却显示零,因为计数器还没来得及增加。(如果"邮件计数错了"听起来不算严重,那就把计数器换成账户余额、把邮件换成支付事务。)隔离性可以防止这一问题:它保证用户 2 要么同时看到插入的邮件和更新后的计数器,要么都看不到,而不会看到不一致的中间态。
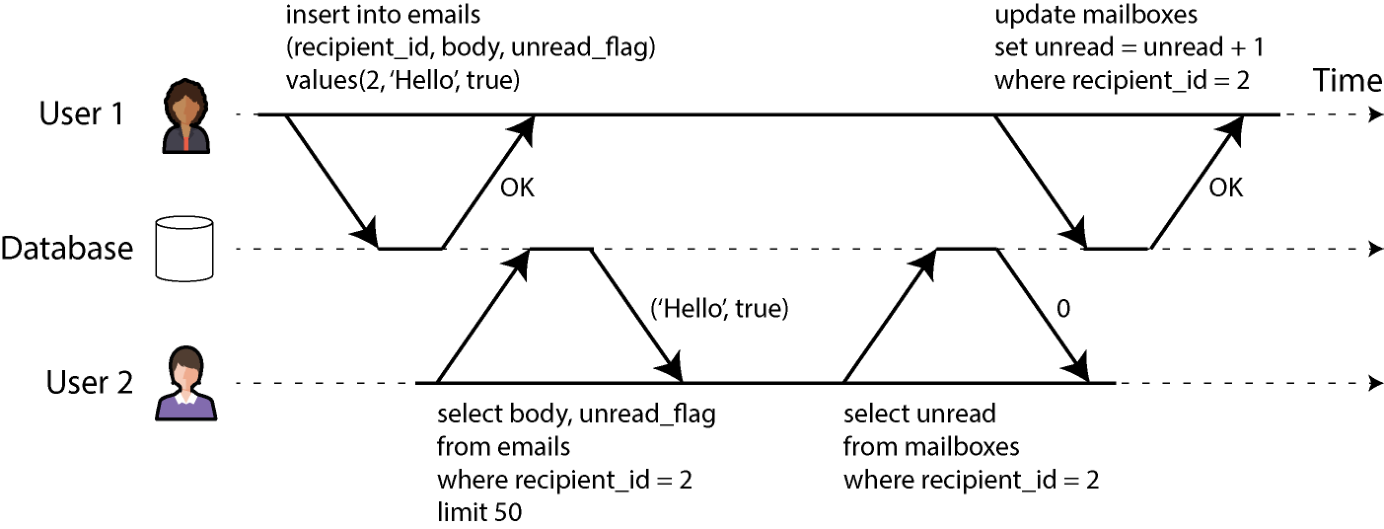
图 8-2. 违反隔离性:一个事务读到了另一个事务尚未提交的写入(脏读)。 图 8-3 演示了对原子性的需求:如果事务执行中途出错,邮箱内容与未读计数器可能失去同步。原子事务下若计数器更新失败,事务就会中止,邮件插入也会回滚。
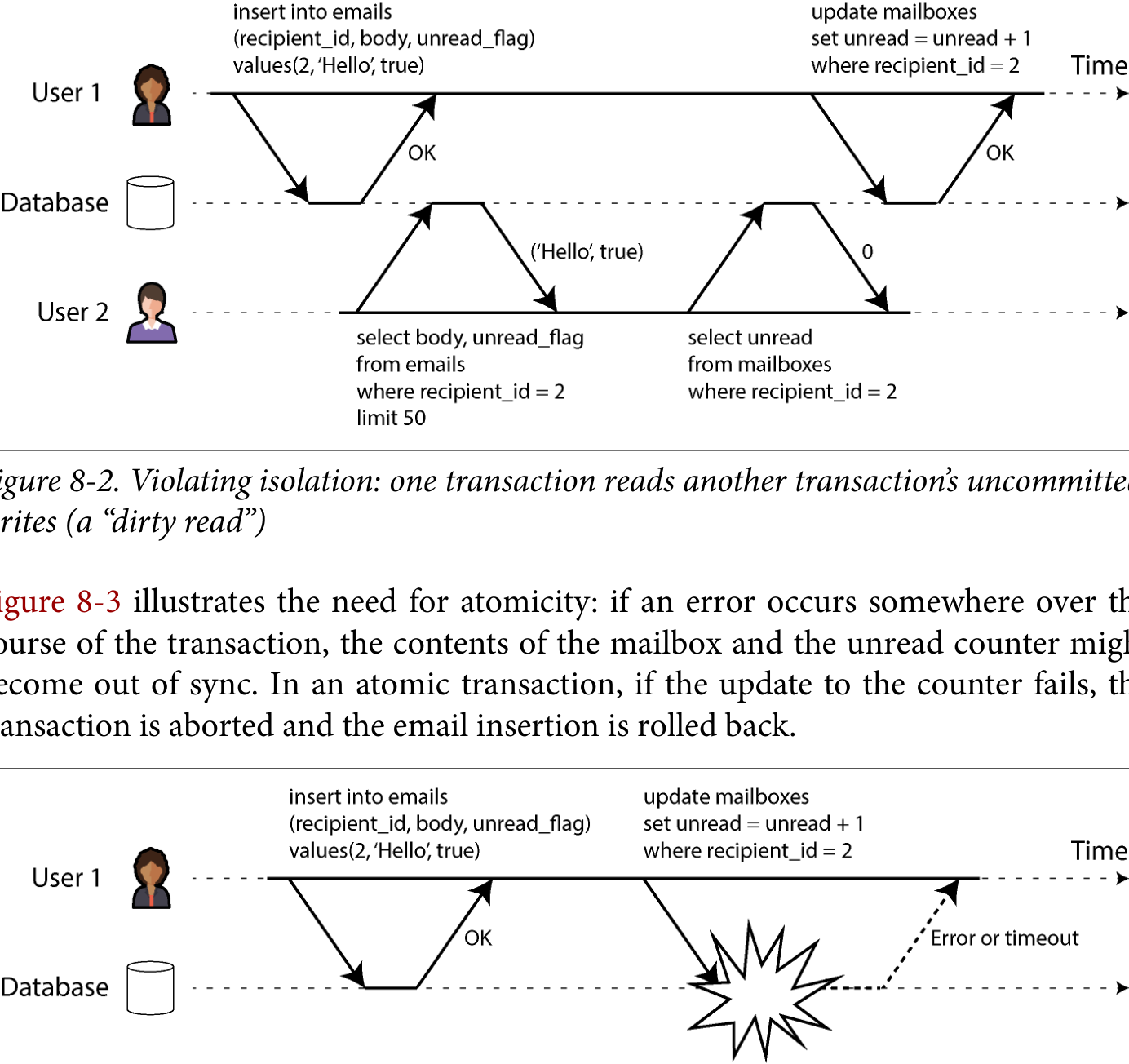
图 8-3. 原子性确保出错时撤销该事务的之前写入,避免不一致。 多对象事务需要某种方式来确定哪些读写属于同一个事务。在关系型数据库里,这通常基于客户端到数据库服务器的 TCP 连接:同一连接上 BEGIN TRANSACTION 与 COMMIT 之间的一切都被视为同一事务。一旦 TCP 连接中断,事务必须中止。
另一方面,许多非关系型数据库根本没有这种把操作组合起来的方式。即便有多对象 API(例如键值存储可能有 multi-put,可一次更新多个键),也未必具备事务语义:命令可能对一些键成功、对另一些失败,让数据库处于部分更新状态。
单对象写入
原子性与隔离性也适用于修改单个对象的情形。例如,你正向数据库写入一个 20 KB 的 JSON 文档:
- 如果在前 10 KB 已经发出之后网络中断,数据库会留下那 10 KB 不可解析的 JSON 片段吗?
- 如果数据库正在覆盖磁盘上的前一个值时断电,最终会以新旧值拼接的形式留下吗?
- 如果另一个客户端在写入还在进行时读这条文档,它会看到部分更新的值吗?
这些结果都会让人极其困惑。所以存储引擎几乎普遍都会在单个对象(如键值存储中的键值对)级别提供原子性和隔离性。原子性可以用崩溃恢复日志实现(见第 127 页"让 B 树可靠"),隔离性可以靠对每个对象加锁实现(同一时刻只允许一个线程访问该对象)。
有些数据库还提供更复杂的原子操作,例如自增——免去了图 8-1 那样的"读-改-写"循环。同样常见的还有条件写:仅当值未被并发修改时才写入(见第 302 页"条件写(compare-and-set)"),类似于共享内存并发里的 compare-and-set 或 compare-and-swap(CAS)。
严格来说,"原子自增"中的"原子"是多线程编程意义上的原子。在 ACID 语境里,更恰当的说法是隔离的或可串行化自增,但通常并不这么叫。
这些单对象操作很有用,因为它们能在多个客户端并发写同一对象时防止丢失更新(见第 299 页"防止丢失更新")。但它们并不是通常意义上的"事务"。例如 Aerospike 的 "strong consistency" 模式,以及 Cassandra 与 ScyllaDB 的"轻量事务"特性,都在单对象上提供线性一致(见第 402 页"线性一致性")读和条件写,但跨多个对象就什么保证也没有了。
对多对象事务的需要
我们到底需不需要多对象事务?仅靠键值数据模型加单对象操作,能不能实现任何应用?
某些用例下,单对象插入、更新、删除已经够用。但许多其他场景都得协调对多个对象的写入:
- 在关系数据模型里,一张表的某行常对另一张表的某行有外键引用。图状数据模型中也一样,一个顶点会有指向其他顶点的边。多对象事务让你能确保这些引用始终有效;当多个互相引用的记录被插入时,外键必须正确且最新,否则数据就毫无意义。
- 在文档数据模型里,需要一同更新的字段往往就在同一文档里,文档被当成单个对象;更新单个文档不需要多对象事务。然而,缺乏 join 能力的文档数据库会鼓励反规范化(见第 80 页"何时使用哪种模型")。当反规范化的信息需要更新时——如图 8-2 那样——你就要在一次操作里更新多份文档。事务在这种场景下非常有用,可以防止反规范化的数据失去同步。
- 在带二级索引的数据库里(除了纯键值存储外,几乎所有数据库),二级索引也得在每次值变化时更新。从事务角度看,这些索引是不同的数据库对象——例如没有事务隔离时,一条记录可能在某个索引里出现,却在另一索引里没出现,因为对第二个索引的更新还没发生(见第 268 页"分片与二级索引")。
这类应用没有事务也能实现。但缺少原子性会让错误处理复杂得多,缺少隔离性会引发并发问题。我们会在第 288 页"弱隔离级别"讨论这些问题,并在第 13 章探讨另一种思路。
处理错误与中止
事务的一个关键特性是:出错时可以中止并安全重试。ACID 数据库正是基于这一思路——一旦有违反原子性、隔离性或持久性的风险,宁可彻底放弃事务,也不让它留下半成品。
不过并非所有系统都遵循这一思路。尤其是采用无主复制(见第 229 页"无主复制")的存储,更多采取"尽力而为"的方式——一句话概括就是"数据库会尽力去做,一旦遇到错误,也不会撤销已经做过的事"——因此从错误中恢复就成了应用的责任。
错误终究会发生,但许多软件开发者倾向于只盯着顺利路径,而不去想错误处理那些麻烦细节。例如流行的对象关系映射(ORM)框架,如 Rails 的 ActiveRecord 与 Django,并不会重试中止的事务——错误通常以异常向上抛出,吞掉用户输入再给用户一条错误消息。这很可惜,因为回滚事务的全部意义就在于支持安全重试。
"重试中止事务"作为错误处理机制虽然简单有效,但并不完美:
- 如果事务其实成功了,只是服务器在通知客户端"提交成功"时网络断了(让客户端误以为是超时),重试会让事务执行两次——除非你有应用层的去重机制。
- 如果错误源于过载或并发事务竞争,重试只会让情况更糟。要避免这种反馈循环,可以限制重试次数、使用指数退避,并把过载相关的错误与其他错误区分对待(见第 38 页"过载系统不会自我恢复")。
- 只有瞬时错误(如死锁、违反隔离性、临时网络中断、故障转移)才值得重试。对永久错误(如违反约束)重试就是白费力气。
- 如果事务在数据库之外还有副作用,那么哪怕事务被中止,那些副作用也可能已经发生。例如发邮件——你不希望每次重试都把邮件再发一遍。要让多个系统一起提交或中止,两阶段提交可以帮上忙(详见第 324 页"两阶段提交")。
- 如果客户端进程在重试途中崩掉,它打算写入的数据就丢了。
弱隔离级别
如果两个事务不访问同一数据,或者两者都是只读的,那它们就可以安全地并行运行,因为彼此独立。并发问题(竞态条件)只在一个事务读到正在被另一个事务修改的数据、或两个事务试图修改同一数据时才会出现。
并发 bug 很难通过测试发现,因为它们只在时序不巧时被触发,发生频率低、难以复现。对并发的推理本身也不容易,尤其在大型应用里,你未必清楚还有哪些代码在访问数据库。哪怕只有一个用户,应用开发已经够难;多个并发用户更难,因为任何一块数据随时都可能意外发生变化。
正因如此,数据库长期以来都试图用事务隔离为应用开发者掩盖并发问题。理论上,隔离性应当让你可以假装并发不存在,从而轻松一些;可串行化隔离意味着数据库保证事务的效果与"串行执行"完全相同(即一次只跑一个,没有任何并发)。
实际上隔离并没有这么简单。可串行化隔离是有性能代价的,许多数据库不愿付这个代价 [10]。因此系统通常采用更弱的隔离级别——它能防住部分并发问题,但拦不住全部。这些级别更难理解、更容易招致微妙的 bug,但实践中仍被广泛使用 [30]。
弱事务隔离与竞态条件造成的并发 bug 不止是理论问题。它们已经造成过大量财产损失,包括弄垮一家比特币交易所 [31, 32, 33, 34]、引发金融审计调查 [35],也曾让客户数据遭到损坏 [36]。每当此类问题被曝光,都会冒出一种流行评论:"处理金融数据要用 ACID 数据库!"——但这没说到点上。哪怕是那些通常被视为"ACID"的流行关系型数据库,用的也是弱隔离,所以未必能挡住上述 bug。
顺便一提,银行系统的大部分功能依赖通过安全 FTP 交换的文本文件 [37]。在这种环境里,审计追踪和人工反欺诈措施其实比 ACID 属性更重要。
这些例子还凸显出一点:即便并发问题在正常运行下并不常见,你也要考虑——攻击者可能故意发出大量高度并发的请求来利用并发 bug [32]。因此要构建可靠且安全的应用,必须系统地防止此类 bug。
本节会看几种实际使用的弱(非可串行化)隔离级别,并详细讨论它们能与不能防住哪些竞态条件,帮你为应用挑选合适的级别。然后再详细讨论可串行化(见第 308 页"可串行化")。我们对隔离级别的讨论以例子为主,并不那么正式。要严格定义与性质分析,可以查阅学术文献 [38, 39, 40, 41]。
读已提交
最基础的事务隔离级别是读已提交(read committed),它给出两条保证:
- 从数据库读时,你只会看到已提交的数据(无脏读)。
- 向数据库写时,你只会覆盖已提交的数据(无脏写)。
下面分别细说这两条保证。
没有脏读
设想某事务已经写了一些数据,但还没提交或中止。另一个事务能看到这些未提交数据吗?能的话就叫脏读(dirty read)[3]。
运行在读已提交隔离级别下的事务必须防止脏读。这意味着事务的写入只有在它提交后才对外可见(届时所有写入一起变可见)。如图 8-4 所示:用户 1 设置了 x = 3,但还没提交,所以用户 2 的 get x 仍然返回旧值 2。
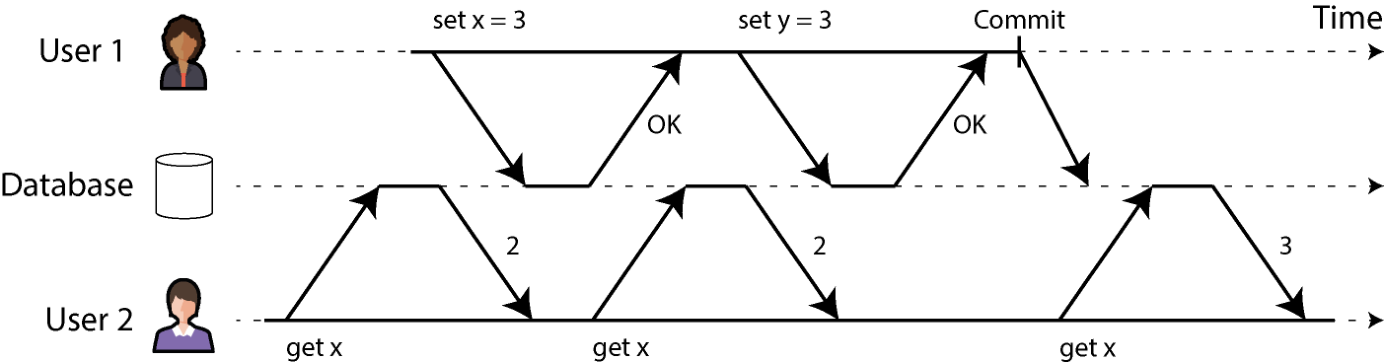
图 8-4. 没有脏读:只有在用户 1 的事务提交后,用户 2 才看到 x 的新值。 防止脏读有几个好处:
- 如果某事务要更新多行,脏读会让另一个事务只看到一部分更新、看不到其他。例如图 8-2 中用户看到了新邮件却没看到更新后的计数——那就是邮件的脏读。看到部分更新状态会让用户困惑,也可能让其他事务做出错误决策。
- 事务中止时要回滚已做的修改(如图 8-3)。允许脏读的数据库里,某事务可能看见后来又被回滚的数据——也就是从未真正提交过的数据。读到这些未提交数据的事务也只得跟着中止,引发级联中止。
没有脏写
两个事务并发地想更新数据库中同一行时会怎样?我们不知道写入的先后顺序,但通常假定后写覆盖先写。
但如果先写属于一个尚未提交的事务,而后写又覆盖了这个未提交的值呢?这叫脏写(dirty write)[38]。读已提交级别的事务必须防止脏写,通常的做法是把第二次写推迟到第一次写所在事务提交或中止之后。
通过防止脏写,这一隔离级别避免了一些并发问题:
- 如果事务要更新多行,脏写可能造成糟糕结果。例如图 8-5 是一个二手车交易网站,Aaliyah 与 Bryce 同时想买同一辆车。买车需要两次写入:更新网站列表以标识买家、把发票开给买家。图 8-5 中销售给了 Bryce(因为 listings 表的最终更新是他的),发票却开给了 Aaliyah(因为 invoices 表的最终更新是她的)。读已提交隔离能防止这类错乱。
- 但读已提交挡不住图 8-1 中两次计数器自增之间的竞态。那里第二次写发生在第一次事务提交之后,所以不算脏写。它仍是错误,只是原因不同;第 299 页"防止丢失更新"会讨论如何让此类自增安全。
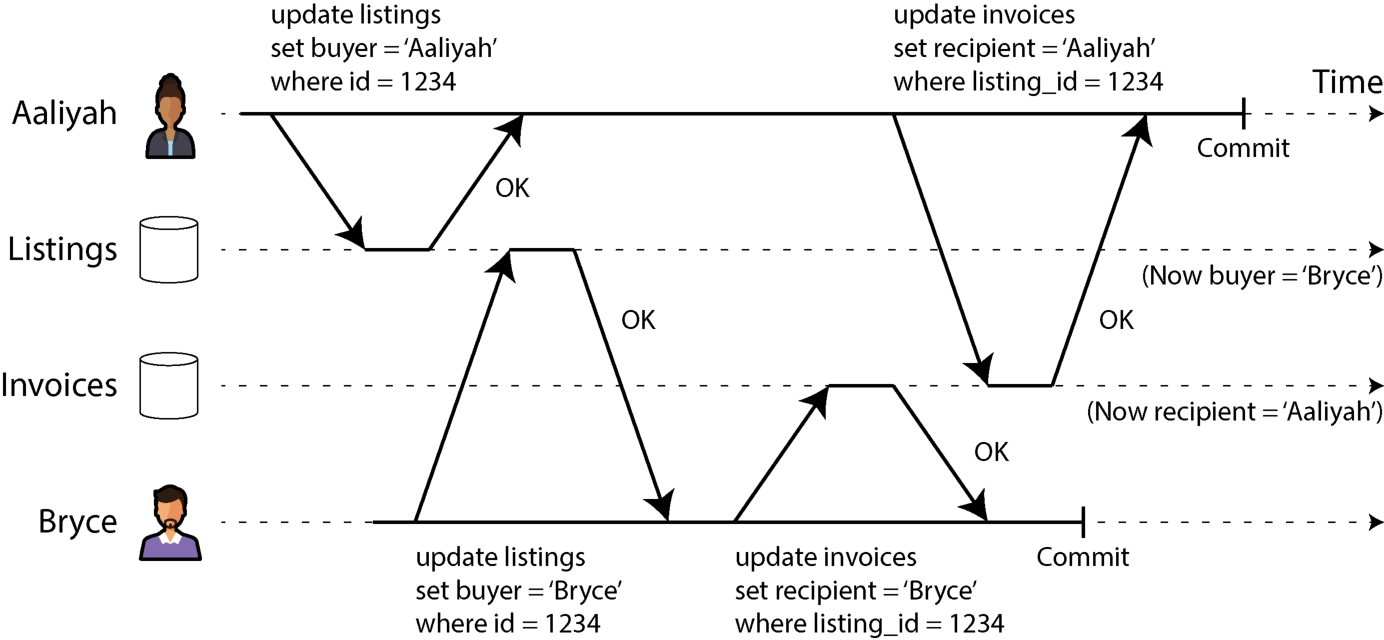
图 8-5. 脏写下,不同事务的冲突写可能被混在一起。
实现读已提交
读已提交是非常常见的隔离级别。它是 Oracle Database、PostgreSQL、SQL Server 等许多数据库的默认设置 [10]。
最常见的做法是用行级锁来防止脏写。要修改某行(或文档、对象)时,事务必须先拿到该行的锁,并一直持有到事务提交或中止。任一时刻只有一个事务能持有某行的锁;如果另一个事务也要写这一行,它就得等到第一个事务提交或中止才能继续。在读已提交(或更强隔离级别)下,数据库会自动加这种锁。
那怎么防止脏读?一种办法是用同样的锁,要求想读某行的事务也短暂取锁、读完立即释放。这样就不会出现"读到带着脏的、未提交值的行"——因为那段时间锁正在做写入的事务手里。
不过实际中"读时也要锁"的效果并不好:一个长时间的写事务会迫使许多其他只读事务等它结束。这会拖累只读事务的响应时间,对可运维性也不利:应用某一部分变慢可能因为等锁而连带影响完全不同的部分。
虽然有些数据库(如 IBM Db2 以及设置 read_committed_snapshot=off 的 Microsoft SQL Server)确实用锁来防止脏读 [30],但更常见的做法如图 8-4 所示:每一行同时记住"旧的已提交值"和持有写锁的事务所设的"新值"。事务进行中时,读取该行的其他事务直接看到旧值;新值提交后,它们才切换到读新值(详见第 295 页"多版本并发控制")。
某些数据库还支持更弱的隔离级别读未提交(read uncommitted):它防脏写但不防脏读。也就是说,它会立刻返回最新写入的值,哪怕那个事务还没提交。这样性能更好,因为数据库不必同时存两个版本;也能降低(但不消除)丢失更新的概率,第 299 页"防止丢失更新"会再讨论。
快照隔离与可重复读
只看读已提交隔离,你也许以为它已经搞定了事务该做的所有事:能中止(这是原子性所需的)、能避免读到事务的中间结果,还能阻止并发写交错。这些确实有用,远胜于不支持事务的系统。
但即使用了这一级别,仍有许多并发 bug。例如图 8-6 演示了读已提交下可能出现的问题。
设 Aaliyah 在银行有 1000 美元储蓄,分别存在两个账户各 500 美元。一笔事务把 100 美元从一个账户转到另一个账户。如果她不巧在事务进行途中查看账户余额,可能会看到一个账户上转账到达之前的余额(仍是 500 美元),另一账户上转账离开之后的余额(新余额 400 美元)。在 Aaliyah 眼里,她似乎只剩 900 美元——100 美元凭空蒸发了。
这种异常叫读偏斜(read skew),属于不可重复读:Aaliyah 在事务结束后再读账户 1 的余额,会看到与之前不同的值(600 美元)。读已提交级别下,读偏斜被认为可以接受:Aaliyah 那一刻看到的余额都是已提交的。
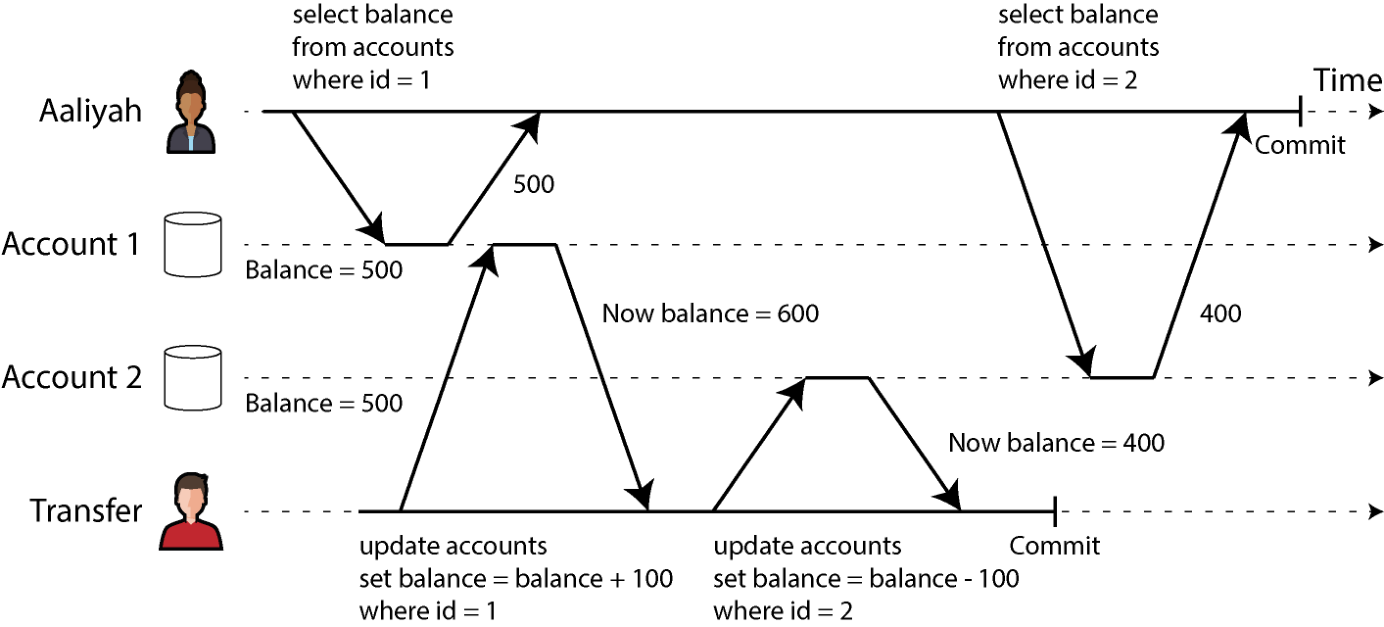
图 8-6. 读偏斜:Aaliyah 观察到数据库处于不一致状态。
图示文字描述: "skew" 一词不幸被过度使用。前面我们用它表示"负载分布不均、有热点"(见第 263 页"倾斜负载与缓解热点"),这里则指时序异常。 对 Aaliyah 来说这不算长久的问题,因为再过几秒刷新网银,她就会看到一致的余额。但下面这些场景对临时的不一致就难以接受了:
备份
备份要把整个数据库复制一份,大数据库可能耗时数小时。备份期间数据库仍会有写入,结果可能是备份的某些部分是旧版本、其他部分是新版本。若需要从这种备份中恢复,类似"消失的钱"这种不一致就变成永久的了。
分析查询和完整性检查
有时你想跑一个扫描数据库大段内容的查询。这类查询常出现在分析里(见第 3 页"业务系统与分析系统"),或是周期完整性检查(监测数据是否损坏)的一部分。一旦它们在数据库不同部分看到不同时间点的状态,结果就可能毫无意义。
快照隔离(snapshot isolation)[38] 是针对这一问题最常用的方案。它的思想是:每个事务都从数据库的一致快照读取——也就是看到事务开始时已提交的所有数据。即便数据随后被另一事务修改,每个事务也只看到那一时刻的旧数据。
快照隔离对长时间运行的只读查询(如备份与分析)非常有用。如果数据在查询执行期间还在变,查询结果就难以解读。让事务看到一份"冻结在某个时刻"的一致快照,事情就好办多了。
快照隔离很流行:PostgreSQL、使用 InnoDB 引擎的 MySQL、Oracle、SQL Server 等都支持它的某种变体,细节因系统而异 [30, 42, 43]。一些数据库(如 Oracle、TiDB、Aurora DSQL)甚至把快照隔离当作最高隔离级别。BigQuery 等云数据仓库也常用快照隔离,为分析查询提供"某一时点"的视图。
多版本并发控制
和读已提交一样,快照隔离的实现通常也用写锁来防止脏写(见第 292 页"实现读已提交")——也就是说,做写入的事务会阻塞另一事务对同一行的写入。但读不需要任何锁。从性能角度讲,快照隔离的核心原则是读永远不阻塞写、写永远不阻塞读。这让数据库在处理写入的同时,还能在一致快照上跑长时间只读查询,彼此互不争锁。
实现快照隔离时,数据库会用到我们在防止脏读时见过那种机制的推广。除了一行的两个版本(已提交的版本和被覆盖但尚未提交的版本),数据库还可能要保留同一行的多个已提交版本,因为不同进行中的事务可能要看到不同时点的数据库状态。由于这种技术把同一行的多个版本并排保存,因此被称为多版本并发控制(multiversion concurrency control,MVCC)。
图 8-7 展示了 PostgreSQL [42, 44, 45] 中基于 MVCC 的快照隔离实现(其他实现也类似)。事务开始时会被赋予一个唯一、单调递增的事务 ID(txid)。事务每次向数据库写入,写入的数据都会带上写入者的事务 ID 标签。(精确地说,PostgreSQL 的事务 ID 是 32 位整数,因此约 40 亿个事务后会溢出。其 vacuum 进程负责清理,确保溢出不影响数据。)
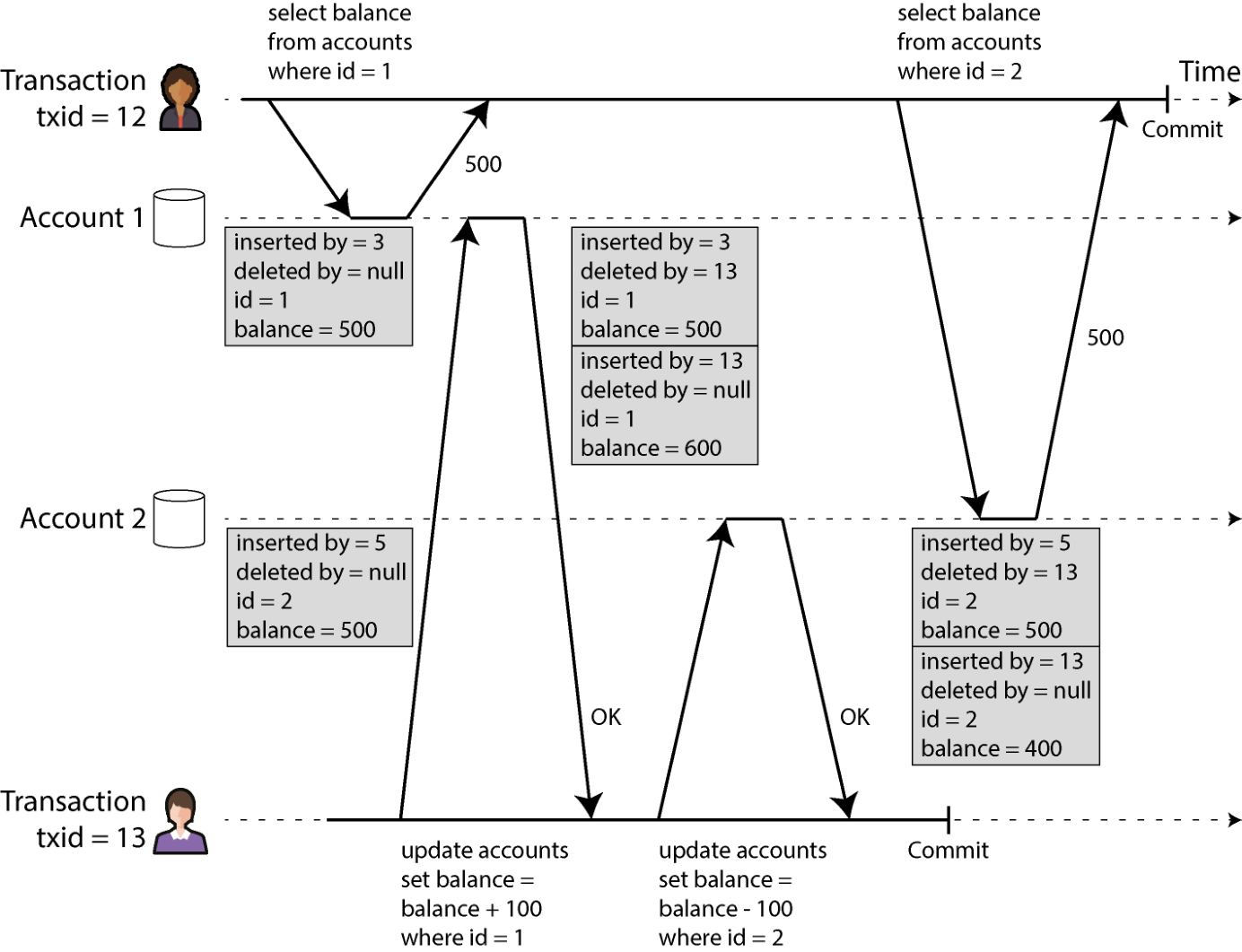
图 8-7. 用多版本并发控制实现快照隔离。 表的每一行都有一个 inserted_by 字段,存放插入该行的事务 ID;每行还有一个 deleted_by 字段,初始为空。某事务删了一行时,并不会真把它从数据库里移除,而是把 deleted_by 设为发出删除请求的事务 ID。等确定没有事务还能访问这条被删或被覆盖的数据时,数据库的垃圾回收(GC)进程会把这些标记为删除的行清掉、释放空间。
更新在内部被翻译为一次删除加一次插入 [46]。例如图 8-7 中事务 13 从账户 2 里扣了 100 美元,余额从 500 变成 400。accounts 表里此时有两行关于账户 2 的记录:一行余额 500、被事务 13 标记为删除;一行余额 400、由事务 13 插入。
同一行的所有版本都放在同一数据库堆里(见第 133 页"在索引中存值"),无论写入它们的事务是否已提交。同一行的多个版本组成一个链表,既可以从最新版本遍历到最旧版本,也可以反向遍历,使查询能在内部迭代该行的所有版本 [47, 48]。
观察一致快照的可见性规则
事务从数据库读取时,事务 ID 决定哪些行版本可见、哪些不可见。通过精心设计可见性规则,数据库就能给应用呈现一致快照。大致流程如下 [45]:
- 每个事务开始时,数据库会列出当时所有进行中(既未提交也未中止)的其他事务。这些事务后续做的任何写入都被忽略,即便后来提交。这样可以保证应用看到的快照不受其他事务提交的影响。
- 任何事务 ID 比当前事务大(即比当前事务晚开始,因此不在"进行中事务列表"里)的事务所做的写入都被忽略,无论它们是否已提交。
- 已中止事务的所有写入都被忽略,无论何时中止。这样做的好处是:事务中止时不必立刻把它写下的行从存储里清掉,可见性规则会自动过滤;GC 进程稍后再移除即可。
- 其他写入对应用的查询都是可见的。
这些规则同样适用于行的插入与删除。图 8-7 中事务 12 读取账户 2 时看到余额 500 美元,因为把 500 余额"删除"的是事务 13(按规则 2,事务 12 看不到事务 13 的删除),插入的 400 美元余额也尚不可见(同样按规则 2)。
换言之,一行同时满足以下两个条件时才可见:
- 读事务开始时,插入此行的事务已经提交。
- 此行未被标记为待删除;若已被标记,那个请求删除的事务在读事务开始时尚未提交。
长事务可以长时间使用同一份快照,继续读取那些(在其他事务看来)早已被覆盖或删除的值。通过永远不原地更新、而是每次值变化都插入新版本,数据库以很低的开销就提供了一致快照。
索引与快照隔离
多版本数据库里索引怎么工作?最常见做法是:每个索引项指向某行的某个版本(最旧或最新),每个行版本可包含指向下一更旧/下一更新版本的引用。使用索引的查询必须遍历这些行,找出对查询可见且值匹配的那个。GC 把不再对任何事务可见的旧行版本移除时,对应索引项也可一并移除。
许多实现细节都会影响多版本并发控制的性能 [47, 48]。例如 PostgreSQL 在同一行的不同版本能放进同一页时会避免索引更新 [42]。还有一些数据库不存修改后行的完整副本,只存版本之间的差异,以省空间。
CouchDB、Datomic 与 LMDB 走的是另一条路。它们也用 B 树(见第 125 页"B 树"),但用一种不可变(写时复制)的变体——更新树时不就地覆盖页,而是为每个被修改的页创建新副本。沿路上溯到根的所有父页都被复制并更新为指向新版本子页。不受写入影响的页则无需复制,可与新树共享 [49]。
不可变 B 树的写事务(或一批事务)每次都会生成一个新的 B 树根。某个根就是它创建时刻数据库的一致快照。这里无需基于事务 ID 过滤行,因为后续写入不能修改已有 B 树,只能创建新树根。这种方法仍需要后台进程做合并与 GC。
快照隔离、可重复读与命名混乱
MVCC 是数据库常用的实现技术,多被用来实现快照隔离。但不同数据库有时用不同术语描述同一件事——例如快照隔离在 PostgreSQL 里叫可重复读,在 Oracle 里叫可串行化 [30]。也有相反的情形:不同系统用同一个词表示完全不同的含义——例如 PostgreSQL 的"可重复读"指快照隔离,MySQL 的"可重复读"则是一种比快照隔离更弱的 MVCC 实现 [43],IBM Db2 的"可重复读"又指可串行化 [10]。
之所以名称混乱,是因为 SQL 标准里没有"快照隔离"这一概念——标准基于 System R 1975 年的隔离级别定义 [3],那时还没有快照隔离。标准里定义了"可重复读",表面上看起来与快照隔离相似。PostgreSQL 把自己的快照隔离称作可重复读,正因为它满足该标准的要求、可以宣称合规。
可惜 SQL 标准对隔离级别的定义本身就有缺陷——含糊、不精确,作为一个标准也没做到与实现无关 [38]。哪怕许多数据库都实现了"可重复读",在它们各自所称的同一隔离级别下,实际保证仍差别巨大 [30]。研究文献已经对该隔离级别做过形式化定义 [39, 40],但大多数实现并不满足那种形式定义。最终结果就是:没人真正知道"可重复读"到底意味着什么。
防止丢失更新
我们对读已提交与快照隔离的讨论,主要聚焦在并发写入存在时只读事务能看到什么样的保证。我们大体上回避了两个事务并发写入的问题——只讨论了脏写(见第 291 页"没有脏写"),它只是写写冲突的一个特例。
并发写入事务之间还有几种有趣的冲突。其中最有名的是丢失更新问题,图 8-1 中两个并发计数器自增就是个例子。
应用从数据库读出一个值、修改它、再写回(前面提到的"读-改-写"循环)时,就可能丢失更新。如果两个事务并发这样做,其中一个的修改就可能丢失,因为第二次写没有包含第一次的修改(我们有时说后写砸碎了先写)。这种模式见于多种场景:
- 自增计数器或更新账户余额(要读当前值、算出新值、再把更新值写回)。
- 对一个复杂值做局部修改——例如往 JSON 文档里某个列表加元素(要解析文档、修改后再写回)。
- 两个用户同时编辑 wiki 页面,每个人都通过把整页内容发给服务器来保存自己的修改,从而覆盖当前数据库里的内容。
这种问题相当常见,业界已经发展出多种解决方案 [50]。下面就看几种最常见的做法。
原子写操作
许多数据库提供原子更新操作,省得你在应用代码里实现读-改-写循环。如果你的代码能用这些操作表达,它们通常就是最佳方案。例如下面这条语句在大多数关系型数据库里都是并发安全的:
UPDATE counters SET value = value + 1 WHERE key = 'foo';类似地,文档数据库(如 MongoDB)提供对 JSON 文档某部分做局部修改的原子操作,Redis 提供对优先级队列等数据结构的原子操作。并非所有写入都能轻松用原子操作表达——例如 wiki 页面的更新涉及任意文本编辑,可以用第 227 页"无冲突复制数据类型与操作变换"中讨论的算法处理——但凡是能用原子操作的地方,它们通常都是最佳选择。
原子操作通常通过读对象时给它加独占锁来实现,让其他事务在更新生效前都读不到它。另一种做法干脆是把所有原子操作都强制串行到一个线程上执行。
可惜的是,ORM 框架很容易让人不知不觉写出不安全的读-改-写循环,却不去用数据库提供的原子操作 [51, 52, 53]。这种微妙的 bug 很难通过测试发现。
显式加锁
如果数据库内置的原子操作不能满足需要,防止丢失更新的另一种办法是:让应用显式为要更新的对象加锁。然后应用做读-改-写循环,其他任何试图并发更新或锁定同一对象的事务都被迫等待,直到第一个读-改-写循环结束。
例如有一款多人游戏,多名玩家可能并发移动同一个棋子。这种场景下,仅靠原子操作可能不够,因为应用还要保证玩家的移动符合游戏规则——这套逻辑无法用数据库查询合理表达。这时可以用锁来防止两个玩家并发移动同一棋子,如示例 8-1。
-- 示例 8-1:用显式锁防止丢失更新
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE; -- ❶
-- 检查移动是否合法,再更新上一条 SELECT 返回的棋子位置。
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;❶ FOR UPDATE 子句指示数据库为该查询返回的所有行加锁。
这是可行的,但要写对就得仔细推敲应用逻辑,很容易在某处漏加必要的锁、引入竞态。
而且对多个对象加锁会有死锁风险——两个或多个事务互相等对方释放锁。许多数据库会自动检测死锁,并中止其中一个事务让系统继续推进,被中止的事务由应用去重试。
自动检测丢失更新
原子操作和锁都靠强制把读-改-写循环串行化来防止丢失更新。另一种思路是:允许它们并行执行,但若事务管理器检测到了丢失更新,就中止违规事务并强制它重试读-改-写循环。
这种方式的好处是:数据库可以在快照隔离基础上高效完成这种检测。事实上,PostgreSQL 的可重复读、Oracle 的可串行化、SQL Server 的快照隔离都会自动检测丢失更新并中止违规事务。MySQL/InnoDB 的可重复读则不检测丢失更新 [30, 43]。一些作者 [38, 40] 主张:数据库必须防止丢失更新才算提供快照隔离,按这一定义,MySQL 并未提供快照隔离。
丢失更新检测最大的好处是:应用代码不需要使用任何特殊的数据库特性。你可能因为忘了加锁或忘了用原子操作而引入 bug,但丢失更新检测会自动发生,因此更不容易出错。不过你仍要在应用层重试中止的事务。
条件写(compare-and-set)
不提供事务的数据库里有时也能找到条件写:仅当上次读取以来值未改变时,才允许更新(前面第 286 页"单对象写入"提过)。如果当前值与你之前读到的不一致,更新就不会生效,读-改-写必须重试。这相当于许多 CPU 所支持的原子 CAS 指令在数据库中的对应物。
例如要防止两个用户并发更新同一个 wiki 页面,可以这样写——只有用户开始编辑后页面内容未变时才更新:
-- 是否安全取决于数据库的具体实现
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content';如果内容已经变化、不再匹配 'old content',这条更新就不会生效。你要检查更新是否生效,必要时重试。除了对比完整内容外,也可以用一个版本号列:每次更新都把它递增,仅当当前版本号未变时才允许更新。这种做法有时叫乐观锁 [54]。
注意:如果另一事务已经并发修改了 content,按 MVCC 可见性规则(见第 297 页"观察一致快照的可见性规则")新内容未必可见。许多 MVCC 实现为这种场景特意开了口子:其他事务写入的值在 UPDATE/DELETE 的 WHERE 子句求值时是可见的,即便它们在快照其他地方并不可见。
冲突解决与复制
复制式数据库(见第 6 章)防止丢失更新又多了一层挑战。这些数据库在多个节点上有数据副本,数据可能在不同节点上并发被修改,需要额外的机制来应对。
锁和条件写都假设只有一份最新数据副本。然而采用多主或无主复制的数据库通常允许多个写入并发发生、并异步复制,因此无法保证只有一份最新副本。所以基于锁或条件写的技术在这种场景下并不适用(第 402 页"线性一致性"会再回到这一问题)。
如第 222 页"处理写入冲突"所述,复制式数据库的常见做法是:允许并发写产生该值的多个冲突版本(也叫兄弟),再由应用代码或特殊数据结构事后解决并合并。
如果更新是可交换的(即可以在不同副本上以不同顺序应用、仍得到相同结果),合并冲突值就能防止丢失更新。例如自增计数器、向集合中添加元素就是可交换操作。这正是 CRDT 背后的思想(见第 227 页"无冲突复制数据类型与操作变换")。但像条件写这类操作就不可交换。
此外,许多复制式数据库默认采用的 LWW 冲突解决方法很容易丢失更新,详见第 224 页"后写胜出(丢弃并发写入)"。
写偏斜与幻影
前面我们看了脏写和丢失更新——并发事务都试图写同一对象时可能出现的两类竞态。要避免数据损坏,这些竞态必须被预防——要么由数据库自动处理,要么用锁、原子写之类的人工保护。
但并发写之间的潜在竞态远不止于此。下面我们再看几种更微妙的冲突。
先想象你在为医院的医生值班排班写应用。医院通常希望任何时刻都有数名医生在岗,但绝对至少要有一名。医生在感觉不适时可以申请下班,前提是该班次还至少有一名同事在岗 [55, 56]。
假设 Aaliyah 与 Bryce 是某班次仅有的两名值班医生,两人都不舒服,于是都决定请假。不巧他们差不多在同一时刻点击了"下班"按钮。结果如图 8-8 所示。
在每个事务里,应用先检查当前是否有两名或更多医生在岗;若是,则认为该名医生下班是安全的。由于数据库使用快照隔离,两次检查都返回 2,于是两个事务都进入下一步。Aaliyah 更新自己的记录把自己下班,Bryce 也更新自己的记录把自己下班。两笔事务都提交后,便没有医生在岗了。本应满足的"至少一名医生在岗"要求被打破。
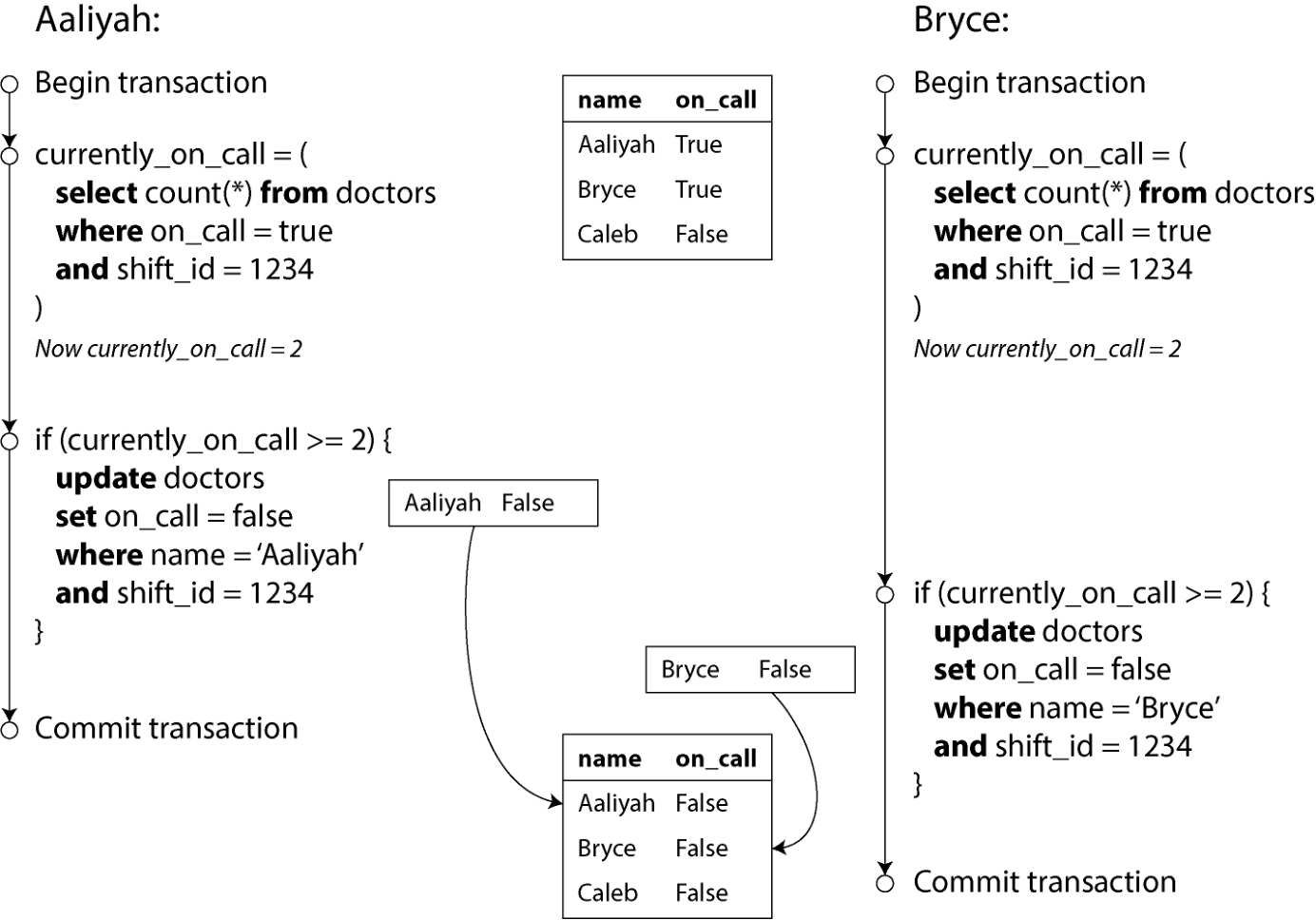
图 8-8. 写偏斜引发的应用 bug。
写偏斜的特征
这种异常叫写偏斜(write skew)[38]。它既不是脏写也不是丢失更新,因为两个事务更新的是两个不同对象(分别是 Aaliyah 与 Bryce 的值班记录)。这里发生的冲突不那么显眼,但确实是一种竞态:如果两个事务一前一后串行执行,第二名医生就会被阻止下班。这种异常行为之所以可能,正是因为事务并发执行。
写偏斜可视为丢失更新问题的推广。当两个事务读同一组对象、然后更新其中一些(不同事务可能更新不同对象)时,就可能出现写偏斜。如果不同事务更新的是同一对象,那这种特例要么是脏写、要么是丢失更新(取决于时序)。
防止丢失更新我们看过多种方法。对写偏斜,可选项更受限:
- 单对象原子操作没用,因为这里涉及多个对象。
- 某些快照隔离实现里的丢失更新自动检测,对写偏斜也无济于事——PostgreSQL 的可重复读、MySQL/InnoDB 的可重复读、Oracle 的可串行化、SQL Server 的快照隔离都不会自动检测写偏斜 [30]。要自动防止写偏斜,需要真正的可串行化(见第 308 页"可串行化")。
- 一些数据库允许配置约束并由数据库强制(例如唯一性、外键约束或对特定值的限制)。但要表达"至少一名医生必须在岗",则需要一个跨多个对象的约束。多数数据库没有内置支持,但你也许可以用触发器或物化视图(见第 280 页"一致性")来实现 [12]。
- 如果不能用可串行化隔离级别,次优办法是显式锁住事务依赖的行。在医生例子里可以这样写:
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234 FOR UPDATE; -- ❶
UPDATE doctors
SET on_call = false
WHERE name = 'Aaliyah'
AND shift_id = 1234;
COMMIT;❶ 与之前一样,FOR UPDATE 告诉数据库锁住该查询返回的所有行。
更多写偏斜的例子
写偏斜乍看像个小众问题,但一旦意识到它,你会发现许多场景都可能撞上:
会议室预订系统
设想你要禁止同一会议室在同一时间被重复预订 [57]。要预订时先检查是否有冲突预订(即同一房间存在时间重叠的其他预订),若没有就创建新预订(见示例 8-2)。
-- 示例 8-2:尝试避免双预订(在快照隔离下并不安全)
BEGIN TRANSACTION;
-- 检查是否有任何与中午到下午一点重叠的现有预订
SELECT COUNT(*) FROM bookings
WHERE room_id = 123 AND
end_time > '2025-01-01 12:00' AND start_time < '2025-01-01 13:00';
-- 若上一查询返回 0:
INSERT INTO bookings
(room_id, start_time, end_time, user_id)
VALUES (123, '2025-01-01 12:00', '2025-01-01 13:00', 666);
COMMIT;可惜快照隔离并不能阻止另一个用户并发插入冲突的预订。要保证不冲突仍然需要可串行化隔离。
多人游戏
示例 8-1 里我们用锁来防止丢失更新(确保两个玩家不能同时移动同一棋子)。但锁挡不住两个玩家把两个不同棋子移到棋盘同一格上,也挡不住某个移动违反游戏规则。视所要强制的规则而定,有时可以用唯一性约束,否则就容易撞上写偏斜。
抢注用户名
在要求每个用户名都唯一的网站上,两个用户可能同时尝试创建同名账号。可以用事务先查名字是否已被占用,若没有就创建。但与前面一样,快照隔离并不安全。所幸这里唯一性约束就是个简便方案(第二个尝试注册的事务会因违反约束而被中止)。
防止超额支出
允许用户花钱或花积分的服务,必须保证用户花的不超过他们持有的。可以这样实现:先把一笔暂记支出条目插入该用户账户、列出账户里的所有条目、再检查总和是否为正。但写偏斜下,两笔支出可能并发插入,二者之和让余额变成负数,而任何一笔事务都不知道另一笔的存在。
引发写偏斜的幻影
前面所有例子都遵循类似的模式:
- 一条 SELECT 通过查找匹配某条件的行,检查某项要求是否被满足(例如至少两名医生在岗、那间会议室在那个时段没有现存预订、棋盘那位置上没有其他棋子、用户名未被占用、账户里还有钱)。
- 应用代码根据这次查询的结果决定如何继续(也许继续操作,或向用户报错并中止)。
- 如果应用决定继续,就向数据库写入(INSERT、UPDATE 或 DELETE)并提交事务。
这次写入的效果改变了步骤 2 决策的前提。换句话说,提交后再执行一次步骤 1 的 SELECT,结果会不同——因为写入改变了匹配该条件的行的集合(在岗医生少了一人、那个时段的那个房间被预订了、棋盘那个位置被新移动占据了、用户名被占了、账户里钱少了)。
步骤的顺序也可以反过来:先写、再 SELECT,最后根据查询结果决定提交或中止。
医生例子里,步骤 3 修改的行恰好就是步骤 1 返回的行,因此可以用 SELECT FOR UPDATE 锁住步骤 1 返回的行,从而保证事务安全、避免写偏斜。但其他四个例子不一样:它们检查的是不存在满足某条件的行,而写入会新增一行满足同一条件。如果第一步查询没返回任何行,SELECT FOR UPDATE 就无可锁 [58]。
这种"一个事务的写入改变另一个事务搜索查询结果"的现象叫幻影(phantom)[4]。快照隔离避免了只读查询的幻影,但在像我们例子里那样的读写事务中,幻影会引发尤其棘手的写偏斜。ORM 生成的 SQL 也很容易出现写偏斜 [52, 53]。
物化冲突
既然幻影问题在于"没有对象可加锁",那能不能人为地把锁对象引入数据库?
例如在会议室预订的例子里,可以建一张时段-房间表,每一行对应某个房间在某个时间段(比如 15 分钟)。事先把所有可能的房间-时段组合都建好(例如未来六个月)。
要创建预订的事务现在就可以用 SELECT FOR UPDATE 锁住对应房间和时间段的行。拿到锁后,事务再像之前那样检查重叠预订并插入新预订。注意这张额外的表并不用来存预订信息——它纯粹是一组锁,专门用来阻止同一房间同一时段的预订并发出现。
这种做法叫物化冲突(materializing conflicts),把幻影变成数据库里具体行上的锁冲突 [14]。可惜要怎么物化冲突常常既难琢磨又容易出错,让并发控制机制渗透进应用数据模型也很难看。出于这些原因,物化冲突应被视为最后的手段,能用其他方法就别用它。大多数情况下,可串行化隔离才是更好的选择。
可串行化
本章我们看了许多容易陷入竞态的事务例子。读已提交和快照隔离能挡住部分竞态,但拦不住全部。我们还碰到了一些尤其棘手的情形(写偏斜与幻影)。局面叫人沮丧:
- 隔离级别难以理解,各数据库的实现还不一致(例如"可重复读"的含义因系统而异)。
- 仅看应用代码,很难判断在某个隔离级别下跑是否安全——尤其大型应用里,你未必清楚还有哪些事同时在并发进行。
- 帮你检测竞态的好工具也基本没有。原则上静态分析有用 [35],但研究中的技术还没走进实践。测试并发问题同样困难,因为问题通常是非确定性的——只有时序不巧时才出现。
这并不是新问题。自 1970 年代弱隔离级别被引入以来 [3],情况就一直如此。多年来研究者的回答都很简单:用可串行化!
可串行化是最强的隔离级别。它保证即使事务并行执行,最终结果也与它们一次一个串行执行(毫无并发)的结果相同。换言之,数据库保证:单独运行时正确的事务,并发运行时仍然正确——也就是数据库挡住所有可能的竞态。
可既然可串行化比这堆混乱的弱隔离级别好得多,为什么大家不都用它呢?要回答这个问题,得看看实现可串行化有哪些选择、性能又如何。如今提供可串行化的数据库大多采用以下三种技术之一,下面分节讨论:
- 字面意义上以串行顺序执行事务(见下一节);
- 两阶段锁(见第 313 页"两阶段锁"),数十年里它都是唯一可行的方案;
- 乐观并发控制技术,如可串行化快照隔离(见第 317 页"可串行化快照隔离")。
实际串行执行
避免并发问题最简单的办法就是干脆消除并发:在单线程上一次只执行一个事务、按串行顺序执行。这样就彻底回避了"检测并防止事务间冲突"的问题;得到的隔离按定义就是可串行化。
听起来很显而易见,但数据库设计者直到 2000 年代才认定单线程循环执行事务是可行的 [59]。既然过去 30 年都把多线程并发视为高性能的关键,那是什么变化让单线程执行成为可能?
有两件事的发展推动了这一反思:
- RAM 变便宜了,许多场景下把整个活跃数据集放进内存已经可行(见第 133 页"把一切放进内存")。当事务要访问的所有数据都在内存中,事务执行就可以远快于"等数据从磁盘加载"。
- 数据库设计者认识到,OLTP 事务通常很短,而且只做少量读写(见第 3 页"业务系统与分析系统")。相对地,长时间运行的分析查询通常是只读的,可以在串行执行循环之外、在一致快照上(用快照隔离)跑。
VoltDB/H-Store、Redis、Datomic 等系统都串行执行事务 [60, 61, 62]。专为单线程执行设计的系统,有时性能反而比支持并发的系统更好,因为可以省掉锁的协调开销。然而其吞吐量受限于单 CPU 核的速度。要充分用好单线程,事务的组织方式必须不同于传统形式。
把事务封装到存储过程
在数据库早期,事务的初衷是覆盖整个用户活动流程。例如订机票本就是一个多阶段过程(搜路线、票价、座位;订行程;为每个航段订座;填乘客信息;付款)。早期数据库设计者觉得,若整个过程是一个事务、能一次原子提交,会非常优雅。
可惜人类做决定与响应都太慢。如果数据库事务要等用户输入,数据库就得支持极多的并发事务,且其中大部分都在空闲。多数数据库做不到高效支持这一点,因此几乎所有 OLTP 应用都把事务保持得很短,避免在事务里交互式等待用户。在 Web 场景下,这意味着事务在同一个 HTTP 请求里提交——事务不会跨多个请求,新请求开新事务。
即便人不在关键路径上,事务仍以交互式 client/server 风格、一次一条语句地执行。应用发起一个查询、读取结果,再基于上次的结果发下一个查询,如此往复。查询和结果在应用代码(一台机器)与数据库服务器(另一台机器)之间来回传递。
这种交互式事务里,大量时间都花在应用与数据库之间的网络通信上。一旦禁止并发、一次只处理一个事务,吞吐量就会很糟糕,因为数据库大部分时间都在等应用发下一条查询。这类数据库要并发处理多个事务才能跑出合理性能。
正因如此,单线程串行处理事务的系统并不允许交互式多语句事务。应用要么把事务限制为单条语句,要么把整段事务代码作为存储过程(stored procedure)事先提交给数据库 [63]。
图 8-9 对比了交互事务与存储过程。只要事务所需的全部数据都在内存中,存储过程就能跑得非常快,不必等待网络或磁盘 I/O。
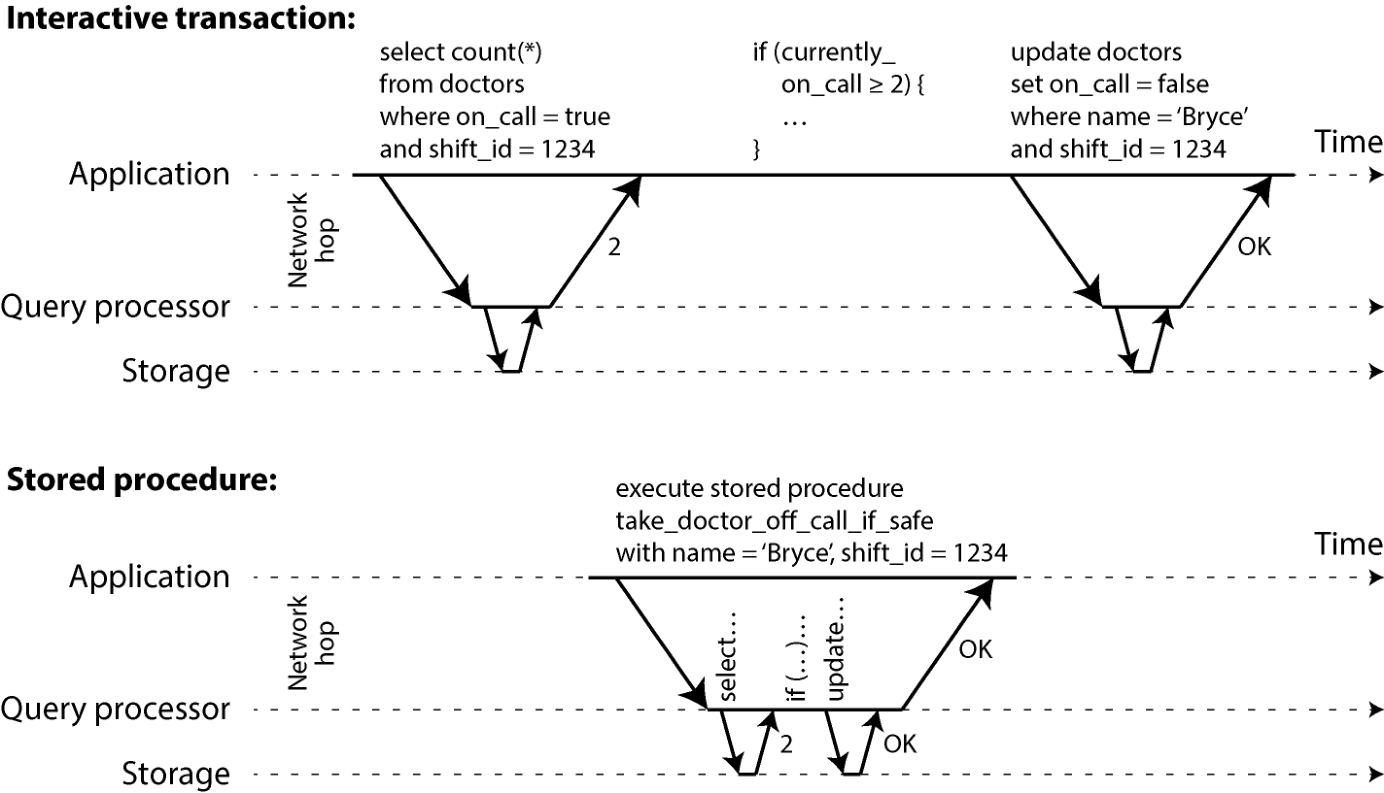
图 8-9. 交互事务与存储过程的差别(用图 8-8 的例子)。
存储过程的优劣
存储过程在关系型数据库里存在已久,自 1999 年起也是 SQL 标准(SQL/PSM)的一部分。但它们的口碑并不好,原因有几个:
- 传统上每家厂商都有自己的存储过程语言(Oracle 是 PL/SQL,SQL Server 是 T-SQL,PostgreSQL 是 PL/pgSQL,等等)。这些语言没跟上通用编程语言的发展,今天看来相当丑陋老旧,也缺少现代语言常见的库生态。
- 在数据库里跑的代码很难管理。相比应用服务器,调试更难、更难放进版本控制并部署、更难测试,也更难接入监控指标系统。
- 数据库通常比应用服务器对性能更敏感,因为一个数据库实例往往被许多应用服务器共享。一段写得糟糕的存储过程(占用大量内存或 CPU、甚至让数据库崩溃)带来的麻烦比同样糟糕的应用代码要大得多。
- 在允许租户自己编写存储过程的多租户系统里,让不可信代码与数据库内核同进程运行存在安全风险 [64]。
不过这些问题都能克服。现代存储过程实现已经抛弃 PL/SQL,改用通用编程语言:VoltDB 用 Java 或 Groovy,Datomic 用 Java 或 Clojure,Redis 用 Lua,MongoDB 用 JavaScript。
应用逻辑不便嵌入别处时,存储过程也很有用。例如基于 GraphQL 的应用可能直接通过 GraphQL 代理暴露数据库;如果代理不支持复杂校验逻辑,就可以用存储过程把这套逻辑直接放进数据库。要是数据库不支持存储过程,就得在代理与数据库之间再加一个校验服务。
把存储过程与内存数据结合起来,在单线程上执行所有事务就变得可行。存储过程不必等 I/O、又避开了其他并发控制机制的开销时,就能在单线程上获得相当可观的吞吐量。
VoltDB 还把存储过程用于复制:它不是把事务的写入从一个节点拷贝到另一个节点,而是在每个副本上执行同一存储过程。VoltDB 因此要求存储过程是确定性的(在不同节点上运行时必须产生相同结果)。如果事务要用当前日期与时间,必须使用特殊的确定性 API(详见第 187 页"持久执行与工作流")。这种方法叫状态机复制(state machine replication),第 10 章还会再提到。
分片
把所有事务串行执行让并发控制简单得多,但事务吞吐量受限于单机单 CPU 核的速度。只读事务可以用快照隔离在别处跑,但对于写吞吐量高的应用,单线程事务处理器就会成为严重瓶颈。
要扩展到多 CPU 核与多节点,可以对数据做分片(见第 7 章),VoltDB 也支持。如果能找到办法分片、让每个事务只读写单个分片内的数据,那么每个分片就能跑自己独立的事务处理线程。这样可以给每个 CPU 核分配一个分片,事务吞吐量便能随核数线性扩展 [61]。
但事务一旦要访问多个分片,数据库就必须跨涉及的所有分片协调事务。存储过程必须在所有分片上同步执行,才能保证全局可串行化。
跨分片事务多了协调开销,比单分片慢得多。VoltDB 报告每秒约 1000 次跨分片写——比单分片吞吐量低几个数量级,且无法靠加机器扩展 [63]。近期研究在探索如何让多分片事务更具可扩展性 [65]。
事务能否基本局限在单分片内,强烈取决于应用的数据结构。简单的键值数据通常容易分片,但带多个二级索引的数据很可能需要大量跨分片协调(见第 268 页"分片与二级索引")。
串行执行小结
事务的串行执行已成为在某些约束下实现可串行化隔离的一种可行做法:
- 每个事务必须又小又快——一笔慢事务就能把整个事务处理卡住。
- 它最适合活跃数据集能放进内存的场景。极少访问的数据可以放磁盘,但只要它需要在单线程事务里被访问,系统就会变得很慢。
- 写吞吐量必须低到一个 CPU 核能处理的范围;否则事务必须分片到不再需要跨分片协调为止。
- 跨分片事务可以做,但其吞吐量很难扩展。
两阶段锁(2PL)
约有 30 年里,数据库实现可串行化只有一种被广泛采用的算法:两阶段锁(2PL),有时也叫强严格两阶段锁(SS2PL)以与其他 2PL 变体区分。
2PL 不是 2PC
2PL 与 2PC 是完全不同的两件事。2PL 提供可串行化隔离,2PC 提供分布式数据库中的原子提交(见第 324 页"两阶段提交")。为避免混淆,最好把两者当成完全独立的概念,无视名字上的雷同。
前面看过锁常被用于防止脏写(见第 291 页"没有脏写")。两个事务并发写同一对象时,锁保证第二个写者必须等到第一个事务结束(中止或提交)才能继续。
2PL 与之类似,但锁的要求要强得多。多个事务可以并发读同一对象——只要没人在写它。但只要任何一方想写(修改或删除)一个对象,就必须独占访问:
- 如果事务 A 已读过某对象、事务 B 想写它,B 必须等 A 提交或中止才能继续(这能保证 B 不会在 A 背后偷偷改对象)。
- 如果事务 A 已写过某对象、事务 B 想读它,B 必须等 A 提交或中止才能继续(在 2PL 下,像图 8-4 那样读到旧版本是不可接受的)。
在 2PL 中,写不仅阻塞其他写,还阻塞读,反之亦然。前面讲过快照隔离的"读永不阻塞写、写永不阻塞读"(见第 295 页"多版本并发控制")——这正是它与 2PL 的关键区别。另一方面,因为 2PL 提供可串行化,它能挡住前面讨论的所有竞态,包括丢失更新和写偏斜。
2PL 的实现
2PL 被用于 MySQL/InnoDB 与 SQL Server 的可串行化隔离级别,以及 Db2 的可重复读隔离级别 [30]。
读写阻塞通过对数据库里的每个对象加锁来实现。锁可以处于共享模式或独占模式(也叫多读单写锁),用法如下:
- 事务想读对象时必须先以共享模式取锁。多个事务可以同时持有共享锁,但若已有事务持有独占锁,这些事务就得等。
- 事务想写对象时必须先以独占模式取锁。其间不能有其他事务持有该对象的任何锁(共享或独占),所以若已有任何锁存在,事务就得等。
- 如果事务先读后写同一对象,它可以把共享锁升级为独占锁。升级与直接取独占锁同理。
- 一旦取得锁,事务必须一直持有到结束(提交或中止)。"两阶段"由此得名:第一阶段(增长阶段,事务执行期间)取锁,第二阶段(收缩阶段,事务结束时)释放锁。两个阶段不能重叠;锁一旦释放,事务里就不能再取新锁。
由于要用大量锁,"事务 A 卡在等事务 B 释放锁、反过来 B 又在等 A"的情况经常出现。这就是死锁。数据库会自动检测事务间死锁并中止其中一个,让其他事务得以继续推进;被中止的事务由应用重试。
2PL 的性能
2PL 最大的缺点(也是它自 1970 年代以来没能成为大多数系统默认选项的原因)就是性能。2PL 下事务吞吐量与查询响应时间都明显差于弱隔离。
部分原因是取锁/放锁本身的开销,但更重要的是并发被设计性地降低了:两个并发事务一旦在任何方面可能产生竞态,就总有一方必须等另一方完成。
举例来说,事务要读整张表(如做备份、分析查询或完整性检查,详见第 293 页"快照隔离与可重复读"),就必须对整张表取共享锁。这个读事务要等所有正在进行的写事务完成;接下来的整表读取期间(大表可能要很久),所有想写该表的事务都会被阻塞、等这次大只读事务提交。事实上数据库会因此长时间不可写。
正因如此,跑 2PL 的数据库延迟可能相当不稳定,工作负载存在竞争时高分位延迟会非常慢(见第 37 页"描述性能")。一笔慢事务,或一个访问大量数据并取大量锁的事务,就足以让系统其余部分停摆。人们用事务超时和慢查询监控来发现并限制行为不当的查询。
虽然基于锁的读已提交也可能出现死锁,但在 2PL 可串行化下死锁要频繁得多(取决于事务的访问模式)。这是又一个性能问题:因死锁被中止后事务要重试,等于重做一遍工作。死锁频繁,浪费就相当可观。
谓词锁
前面对锁的描述里我们略过了一个微妙却重要的细节。第 307 页"引发写偏斜的幻影"讨论过幻影——一个事务改变另一个事务搜索查询的结果。提供可串行化的数据库必须防住幻影。
在会议室预订的例子里,这意味着:如果某事务在某时段为某房间搜索现有预订(示例 8-2),另一事务就不能并发地为同一房间同一时段插入或更新预订(同房间不同时段、或不同房间同一时段的并发插入仍可以,只要不与所拟预订冲突)。
要如何实现?概念上需要谓词锁[4]。它的工作方式和前面描述的共享/独占锁类似,但不附在某个具体对象(如表里的某一行)上,而是附在所有匹配某搜索条件的对象上,例如:
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2026-01-01 12:00' AND
start_time < '2026-01-01 13:00';谓词锁按以下方式限制访问:
- 事务 A 想读匹配某条件的对象时(如上面那条 SELECT),必须先在该查询条件上取共享模式的谓词锁。如果事务 B 当前对任何匹配该条件的对象持有独占锁,A 必须等 B 释放才能查询。
- 事务 A 想插入、更新或删除任何对象时,必须先检查它的旧值或新值是否匹配任何现有的谓词锁。如果有匹配的谓词锁被事务 B 持有,A 必须等 B 提交或中止才能继续。
关键思想是:谓词锁可以适用于数据库中尚不存在但将来可能加入的对象(幻影)。如果 2PL 包含谓词锁,数据库就能挡住所有形式的写偏斜与其他竞态,从而真正提供可串行化。
索引范围锁
可惜谓词锁性能不佳:当有大量活跃事务持有锁时,检查匹配的锁会很费时。因此多数采用 2PL 的数据库实现的是索引范围锁(index-range locking,也叫 next-key locking),它是谓词锁的简化近似 [56, 66]。
把谓词放宽到匹配更大的对象集合是安全的。例如已经有"中午到下午一点为 123 房间预订"这样的谓词锁时,可以放宽为"123 房间任意时段的预订都加锁",或放宽为"中午到下午一点所有房间的预订都加锁"。这种近似是安全的,因为任何匹配原谓词的写入也一定匹配这种近似。
会议室预订数据库多半会在 room_id 列上有索引,或在 start_time 与 end_time 上有索引(否则上面的查询在大数据库里会很慢):
- 假设索引在
room_id上,数据库就用它找 123 房间的现有预订。它可以直接给该索引项附上一把共享锁,标记此行已被某事务搜索过。 - 或者数据库用基于时间的索引找现有预订时,可以给该索引中某段值范围加共享锁,表明事务搜索过当天中午到一点重叠的预订。
无论哪种方式,搜索条件的近似都附在某个索引上。一旦另一个事务想为同一房间和/或重叠时间段插入、更新或删除预订,它就会更新到索引的同一部分、撞上这把共享锁,从而被迫等待。
这就能很好地挡住幻影与写偏斜。索引范围锁不像谓词锁那样精确(它们可能锁住比"严格保证可串行化所需"更多的对象),但开销低得多,是个不错的折中。
要是没有合适的索引可挂范围锁,数据库可以退回到对整张表加共享锁。这对性能不利,因为会阻塞所有想写该表的事务,但作为兜底是安全的。
可串行化快照隔离(SSI)
本章给数据库的并发控制画了一幅悲观图景:一边是性能差(2PL)或扩展性差(串行执行)的可串行化实现;另一边是性能好却容易出竞态(丢失更新、写偏斜、幻影等)的弱隔离级别。可串行化与高性能在根本上无法调和吗?
也许不是:有一种叫可串行化快照隔离(serializable snapshot isolation,SSI)的算法,能提供完整的可串行化,相比快照隔离仅有小幅性能损失。SSI 是较新的算法,2008 年才首次被描述 [55, 67]。
如今 SSI 及类似算法已被用于单节点数据库(PostgreSQL [56]、SQL Server 的 In-Memory OLTP/Hekaton [68]、HyPer [69] 的可串行化级别)、分布式数据库(CockroachDB [5]、FoundationDB [8]),以及 BadgerDB 这样的嵌入式存储引擎。
悲观与乐观并发控制
2PL 是一种悲观并发控制机制:它的信条是只要有可能出错(以另一事务持有的锁为标志),最好就等到安全再做事。这有点像多线程编程里用来保护数据结构的互斥。
某种程度上,串行执行是极致悲观:本质上等同于每个事务在它整个执行期间持有整个数据库(或某个分片)的独占锁。我们通过让每个事务执行得很快来补偿这种悲观。
可串行化快照隔离则是一种乐观并发控制技术。这里的"乐观"是指:发生某些可能危险的事时,事务不阻塞,而是继续往下走,盼着最终一切都好。当事务想提交时,数据库检查期间有没有出问题(即是否破坏了隔离),若有,事务就被中止重试。只有那些以可串行方式执行的事务才允许提交。
乐观并发控制是个老想法 [70],其优劣讨论多年 [71]。在高竞争下(许多事务都想访问同一对象)它表现不佳,因为会有相当比例的事务被迫中止。如果系统已接近最大吞吐,重试事务带来的额外负载只会让性能更糟。
但只要还有足够余量、事务间竞争不太高,乐观并发控制往往胜过悲观控制。竞争可以通过可交换的原子操作来减少:例如多个事务同时给计数器加 1,加的顺序无关紧要(只要本事务里没读它),所以并发的自增可以无冲突地全部应用。
顾名思义,SSI 基于快照隔离——也就是事务里所有读都来自数据库的一致快照(见第 293 页"快照隔离与可重复读")。在快照隔离之上,SSI 加了一种检测读写之间序列化冲突、判定哪些事务该被中止的算法。
基于过时前提的决策
我们前面讨论快照隔离下的写偏斜(见第 303 页"写偏斜与幻影")时,看到一个反复出现的模式:事务从数据库读取数据,检查查询结果,再根据看到的内容决定动作(向数据库写入)。但在快照隔离下,原查询的结果在事务提交时可能已不再最新,因为期间数据可能已被改动。
换句话说,事务基于一个前提(事务开始时为真的事实,例如"目前有两名医生在岗")来行动。等事务想提交时,原数据可能已变——前提不再成立。
应用做查询(例如"现在有多少医生在岗?")时,数据库并不知道应用打算如何使用查询结果。为安全起见,数据库必须假定:查询结果(前提)的任何变化都可能让该事务的写入失效。也就是说,事务里的查询和写入之间可能存在因果依赖。要提供可串行化隔离,数据库必须发现事务可能基于过时前提行动的情形,并中止该事务。
数据库怎么知道某查询结果可能已变?要看两种情况:
- 检测对过时 MVCC 对象版本的读(读之前曾发生过尚未提交的写);
- 检测影响先前读的写(写发生在读之后)。
检测陈旧 MVCC 读
回忆一下,快照隔离通常用 MVCC 来实现(见第 295 页"多版本并发控制")。事务从 MVCC 数据库的一致快照读时,会忽略所有在快照拍摄时尚未提交的事务的写入。
图 8-10 中,事务 43 把 Aaliyah 看作 on_call = true,因为修改 Aaliyah 在岗状态的事务 42 还没提交。但等到事务 43 想提交时,事务 42 已经提交了。这意味着原本读一致快照时被忽略的那条写入现在已经生效,事务 43 的前提不再成立。写者插入此前不存在的数据时,情况会更复杂(见第 307 页"引发写偏斜的幻影");下面会讨论 SSI 中对幻影写的检测。
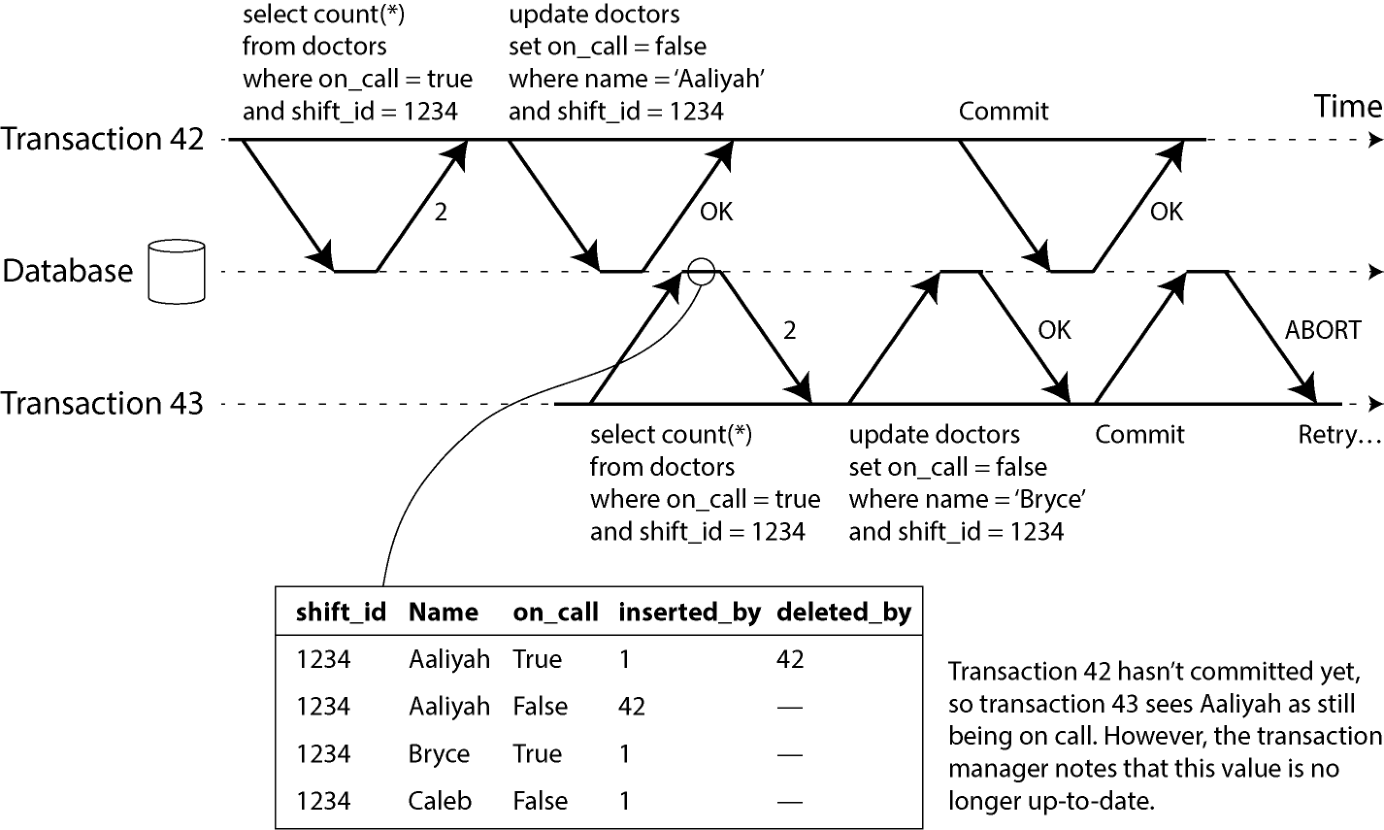
图 8-10. 检测事务从 MVCC 快照读到过时值。 要防住这种异常,数据库需要记录某事务何时因 MVCC 可见性规则忽略了另一事务的写入。等事务想提交时,数据库再检查这些被忽略的写入是否已经提交;如果是,该事务必须中止。
为什么要等到提交才中止?检测到陈旧读时为什么不立刻中止事务 43?因为如果事务 43 是只读事务,就无须中止——没有写偏斜风险。事务 43 做读时,数据库还不知道它后续是否会写。再者,事务 42 在事务 43 提交时也可能中止、或仍未提交,那次读未必真的陈旧。SSI 借助"避免不必要的中止",保留了快照隔离对长时间只读查询(基于一致快照)的良好支持。
检测影响先前读的写
第二种要考虑的情况是:另一个事务在某事务读完数据后修改了它。这种情况见图 8-11。
在 2PL 语境下,我们讨论过索引范围锁(见第 317 页"索引范围锁"),它能锁住所有匹配某查询条件的行,例如 WHERE shift_id = 1234。这里我们用类似的技术,只是 SSI 的锁并不阻塞其他事务。
图 8-11 中,事务 42 与事务 43 都搜索班次 1234 的在岗医生。如果 shift_id 上有索引,数据库可以在索引项 1234 上记录"事务 42 与事务 43 读了这条数据"(没有索引就在表级别记录)。这些信息只需保留一段时间;等到事务结束(提交或中止)、并且所有并发事务也结束后,数据库就可以忘掉它读了哪些。
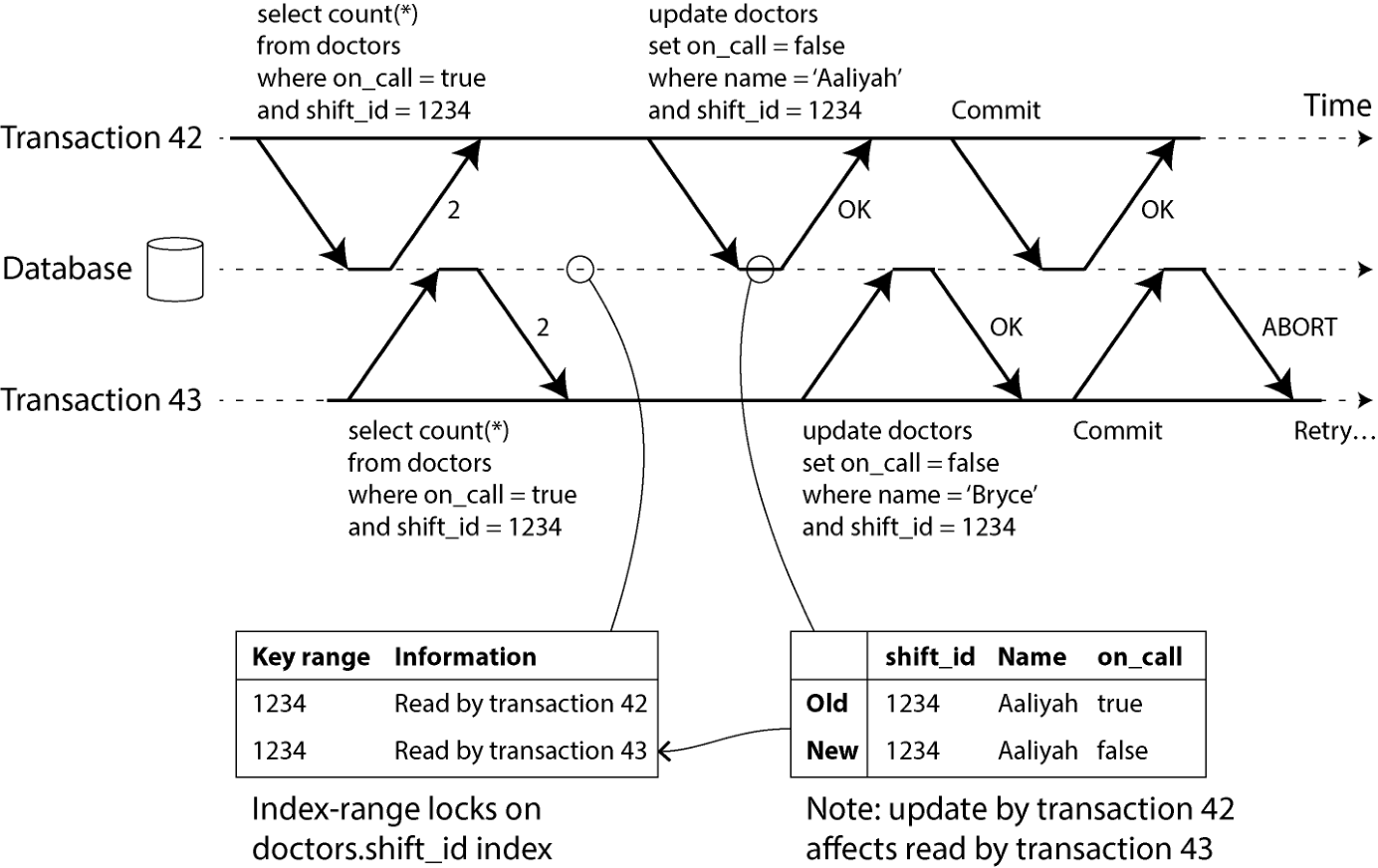
图 8-11. 可串行化快照隔离中检测一事务修改另一事务先前读的数据。 写入数据库时,事务必须查阅索引,看看是否有任何近期读过被影响数据的事务。这一过程类似在被影响的键范围上加写锁,但这种锁并不阻塞读者直到提交,而是充当绊网:只向相关事务发出"它读到的数据可能已不再最新"的通知。
图 8-11 中,事务 43 通知事务 42 它的先前读已过时,反之亦然。事务 42 先提交且成功;虽然事务 43 的写影响了事务 42,但 43 还没提交,写尚未生效。然而当事务 43 想提交时,42 的冲突写已经生效,于是 43 必须中止。
可串行化快照隔离的性能
一如既往,许多工程细节决定了算法在实际中的表现。例如有一个取舍是:跟踪事务读写的粒度。粒度越细,越能精确判断哪些事务需要中止,但簿记开销也越大;粒度越粗,速度越快,但可能引发更多本可避免的中止。
某些情况下,事务读到被另一事务覆盖的信息也无妨。视具体情形,有时仍可证明执行结果是可串行化的。PostgreSQL 就利用这一理论减少不必要的中止 [14, 56]。
相比 2PL,可串行化快照隔离最大的优点是:事务无需阻塞等待另一事务持有的锁。与快照隔离一样,写不阻塞读、读不阻塞写。这种设计让查询延迟更可预期、波动更小。尤其是只读查询可以在一致快照上跑、无需任何锁,对读重型工作负载非常有吸引力。
相比串行执行,可串行化快照隔离不受单 CPU 核吞吐量的限制——例如 FoundationDB 把序列化冲突检测分布到多台机器,可以扩展到极高的吞吐。即便数据被分片到多台机器上,事务也能跨多个分片读写,同时仍保证可串行化。
相比非可串行化的快照隔离,检查可串行化违例引入了一些性能开销。这开销有多大仍有争议:有人觉得不值得 [72],也有人认为可串行化的性能已经够好,没必要再用更弱的快照隔离 [69]。
中止率会显著影响 SSI 的整体性能。例如长时间读写数据的事务很容易撞上冲突而被中止,所以 SSI 要求读写事务相当短(长时间只读则无妨)。不过 SSI 对慢事务的敏感度比 2PL 或串行执行都要低。
分布式事务
单节点事务里,由单台机器负责执行事务逻辑(包括事务隔离的并发控制算法)。如果你的数据库采用单主复制,事务执行只发生在主节点上,从节点只是回放主节点提交的写日志。
但如果事务涉及多个节点呢?例如你的事务可能要触及一个分片数据库的多个分片,或一个全局二级索引(其索引项可能与主数据位于不同节点;见第 268 页"分片与二级索引")。这就叫分布式事务。
分布式事务里的并发控制算法与单节点的大致相似。我们前面讨论过分片数据库上的串行执行;2PL 在分布式环境也能用;针对 SSI 也已有分布式可串行化检查器 [8]。这里不再深入这些细节。
但在分布式事务中实现原子性是一个全新的挑战,本章其余部分就聚焦于此。
单节点事务里,原子性通常由存储引擎实现。客户端要求数据库节点提交事务时,数据库会让该事务的写入持久化(通常写到 WAL;见第 127 页"让 B 树可靠"),再把提交记录追加到磁盘日志末尾。要是数据库在这一过程中途崩溃,节点重启时会从日志中恢复——若提交记录在崩溃前已成功写到磁盘,事务就被视为已提交;否则该事务的所有写入都会被回滚。
因此在单节点上,事务提交的关键就在于数据落盘的顺序:先数据、再提交记录 [22]。决定事务提交还是中止的关键时刻,就是磁盘完成提交记录写入的那一瞬——在此之前仍可中止(因崩溃),在此之后事务即被视为已提交(即便数据库崩溃)。所以是某个单一设备(某个磁盘控制器、某个节点)让提交具备原子性。
而在分布式事务里,判断事务是否提交就没那么简单。比如事务想提交时,不能只是把提交请求发给所有节点、让它们各自独立提交——很容易出现一些节点提交成功、另一些失败(如图 8-12)的情况,原因可能有:
- 一些节点检测到约束违反或冲突,不得不中止;另一些却成功提交。
- 一些提交请求在网络中丢失,因超时最终中止;另一些则正常通过。
- 一些节点在提交记录写完前崩溃,恢复时回滚事务;另一些却成功提交。
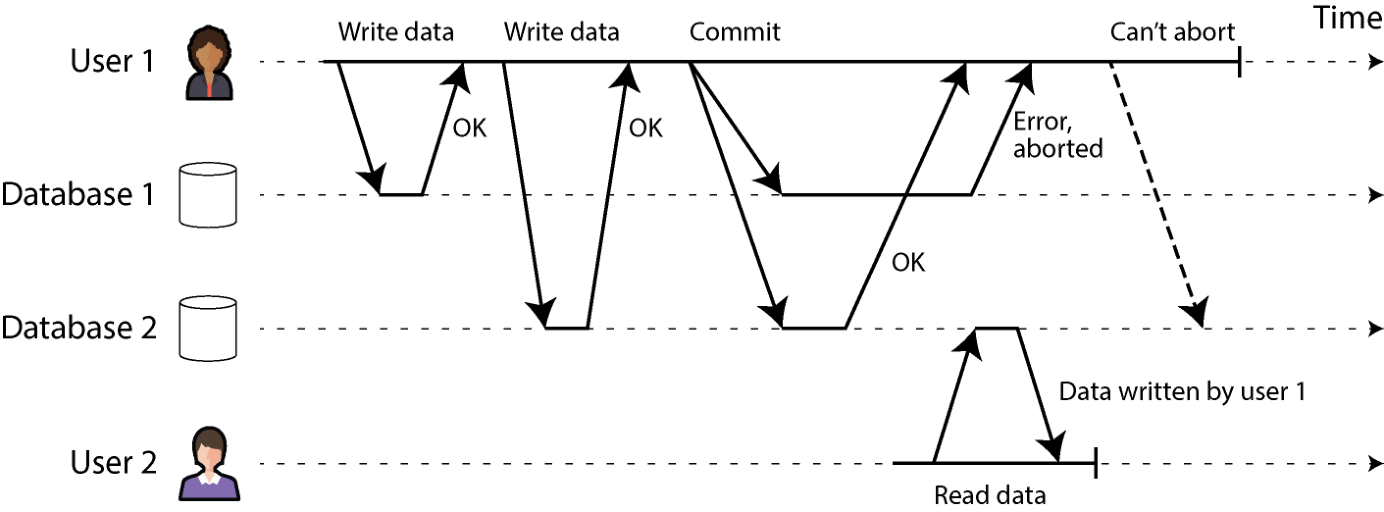
图 8-12. 当事务涉及多个数据库节点时,可能在一些节点提交、在另一些节点失败。 要是一些节点提交、另一些中止,节点间就会不一致。一旦事务在某节点已提交,就不能撤回——因为数据已对其他事务可见(在读已提交或更强隔离下)。例如图 8-12 中,等用户 1 发现它在 database 1 上提交失败时,用户 2 已经从 database 2 上读到了这次事务写入的数据。如果用户 1 的事务后来被中止,用户 2 的事务也得跟着回滚,因为它所依据的数据被追溯地宣告"从未存在"。
更好的做法是确保事务涉及的所有节点要么全部提交、要么全部中止,不能混杂。这就是原子提交问题。
两阶段提交(2PC)
两阶段提交(two-phase commit,2PC)是一种实现跨多节点原子事务提交的算法。它是分布式数据库里的经典算法 [13, 73, 74]。2PC 在某些数据库内部使用,也通过 XA 事务[75](例如由 Java Transaction API 支持)或面向 SOAP Web 服务的 WS-AtomicTransaction [76, 77] 暴露给应用使用。
2PC 的基本流程见图 8-13。与单节点事务那种一次提交请求不同,2PC 把提交/中止过程分成两个阶段(这正是名字的由来)。
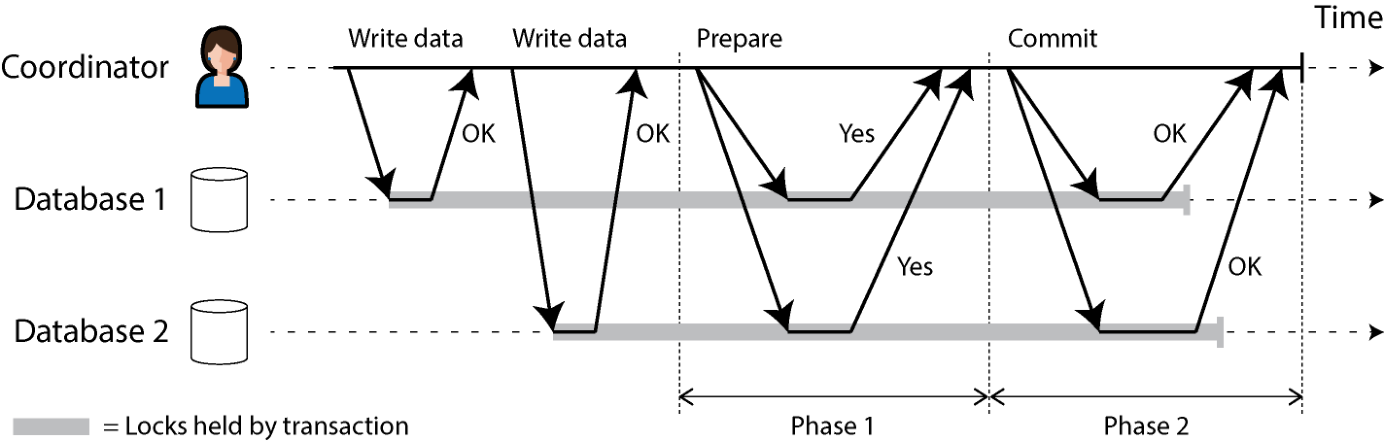
图 8-13. 2PC 的成功执行。 2PC 引入了单节点事务里没有的一个新组件:协调者(coordinator,又叫事务管理器)。协调者通常以库的形式嵌在发起事务的应用进程内(例如嵌在 Java EE 容器里),但也可以是独立的进程或服务。这类协调者的例子包括 Narayana、JOTM、BTM、MSDTC。
使用 2PC 时,分布式事务从应用在多个数据库节点上正常读写数据开始。我们把这些数据库节点称为参与者。应用准备好提交时,协调者开始第 1 阶段:向每个节点发出 prepare 请求,询问它们能否提交。然后协调者跟踪参与者的回复:
- 如果所有参与者都回 yes,表示愿意提交,协调者就在第 2 阶段发出 commit 请求,提交真正发生。
- 如果任一参与者回 no,协调者就在第 2 阶段向所有节点发出 abort 请求。
这一过程有点像西方传统婚礼:主持人分别问双方是否愿意结婚,得到双方的"我愿意"后宣布两人结合,事务被提交,喜事广而告之;如果任何一方不答应,仪式就此取消 [78]。
一个由承诺组成的系统
仅看上面这段简短描述,未必能看出为什么 2PC 能保证原子性,而把单阶段提交分别发到多个节点不行。两阶段情形下,prepare 和 commit 请求不一样会丢吗?2PC 到底有何不同?
要弄清楚这一点,就得把过程拆得更细:
- 应用想开启分布式事务时,向协调者请求一个事务 ID。这个事务 ID 是全局唯一的。
- 应用在每个参与者上开启一个单节点事务,把这个全局事务 ID 附在单节点事务上。所有读写都在这些单节点事务里完成。此阶段若出问题(例如节点崩溃或请求超时),协调者或任意参与者都可以中止。
- 应用准备提交时,协调者向所有参与者发送 prepare 请求,并带上全局事务 ID。任一请求失败或超时,协调者就向所有参与者发出该事务 ID 的 abort 请求。
- 参与者收到 prepare 请求后,必须保证它在任何情况下都能确定提交:把所有事务数据写到磁盘(崩溃、断电或磁盘满都不能成为日后拒绝提交的借口),并检查冲突或违反约束。它一旦向协调者回 yes,就承诺日后一定能按需提交事务——也就是说参与者放弃了中止权,但还没真正提交。
- 协调者收到所有 prepare 响应后,对"提交还是中止"做出最终决定(只有所有参与者都投 yes 时才提交)。协调者必须把这一决定写到磁盘上的事务日志,以便后续崩溃时仍知道决定。这就是提交点(commit point)。
- 协调者的决定写到磁盘后,commit 或 abort 请求就发给所有参与者。这一请求失败或超时时,协调者必须无限重试直到成功。再无回头路:一旦决定提交就必须执行,不管重试多少次。参与者若期间崩溃,恢复后会提交事务——因为它之前已投过 yes,恢复时不能再反悔。
因此协议有两个关键的"不可逆点":参与者投 yes 时承诺自己以后一定能提交(虽然协调者仍可选择中止);协调者一旦做出决定,就不可撤回。这些承诺保证了 2PC 的原子性。(单节点原子提交把这两件事合二为一:把提交记录写到事务日志。)
回到婚礼的类比:在说"我愿意"之前,你和伴侣都有自由说"不可能"(或类似话)来中止;但说了"我愿意"之后就不能反悔了。即便你刚说完就晕过去、没听到主持人宣布结合,事务实际上也已经被提交了。当你恢复意识,可以向主持人查询全局事务 ID 来弄清自己是否结婚,或等主持人下次重试 commit 请求(重试在你昏迷期间一直在进行)。
协调者失效
前面已经讨论了 2PC 期间某参与者或网络失败会怎样:任一 prepare 请求失败或超时,协调者就中止事务;任一 commit/abort 请求失败,协调者无限重试。但协调者崩溃时会怎样?情况就没那么明朗了。
如果协调者在发出 prepare 请求之前失效,参与者可以安全地中止事务。但参与者一旦收到 prepare 请求并投了 yes,就不能单方面中止——它必须等协调者告诉自己是提交还是中止。如果此时协调者崩溃或网络故障,参与者只能等。处于这种状态的参与者事务被称为疑虑(in doubt)或不确定(uncertain)。
图 8-14 给出了这种情形。例子里协调者其实已经决定提交、database 2 也收到了 commit 请求;但协调者在向 database 1 发 commit 请求前崩溃了。database 1 不知道该提交还是中止。即便超时也无济于事:要是 database 1 超时后单方面中止,就会与 database 2(已提交)不一致;同样,单方面提交也不安全,因为另一参与者也许已经中止。
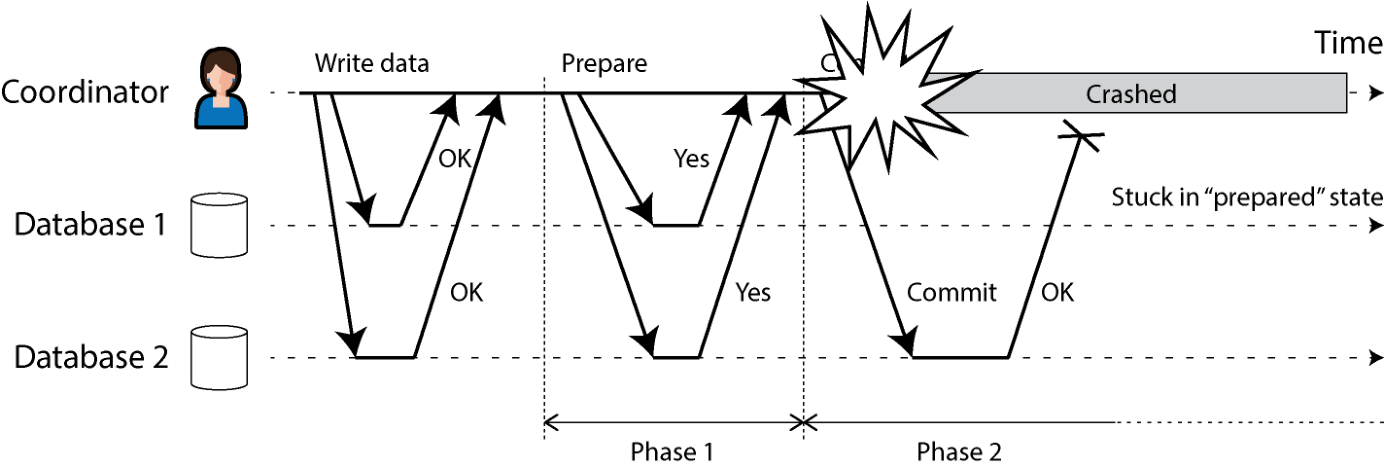
图 8-14. 参与者投 yes 后协调者崩溃。Database 1 不知道该提交还是中止。 参与者收不到协调者的消息,就无法判断该提交还是中止。原则上参与者之间可以互通、自行达成一致——但这并不属于 2PC 协议。
2PC 唯一可行的出路就是等协调者恢复。这正是为什么协调者必须先把提交/中止决定写到磁盘的事务日志,再发 commit/abort 请求:协调者恢复时,可以读事务日志来判断所有疑虑事务的状态——日志里没有提交记录的事务一律按中止处理。这样一来,2PC 的提交点最终就归结为协调者上的一次常规单节点原子提交。
而且一旦协调者磁盘失效、日志丢失,系统就无法自动恢复。唯一的选择是让管理员手动判定每个疑虑事务该提交还是回滚。如果丢的是事务日志的最新部分,恢复后的协调者可能误以为已提交的事务没提交、从而尝试中止它们,进而破坏原子性。
三阶段提交
2PC 被称作阻塞原子提交协议,因为它可能因为等协调者恢复而卡住。理论上可以让原子提交协议不阻塞,让节点失效时也不卡。然而实践里并不简单。
作为 2PC 的替代,业界提出了三阶段提交(3PC)[13, 79]。但 3PC 假设网络延迟有界、节点响应时间有界;而多数现实系统里网络延迟与进程暂停都没有上界(见第 9 章),所以 3PC 并不能保证原子性。
实践中更好的解法是用容错共识协议替换单节点协调者,第 10 章会讨论。
跨不同系统的分布式事务
分布式事务和 2PC 的口碑参差不齐。一方面,它们被视作能提供其他方式难以达到的重要安全保证;另一方面,又被诟病引发运维问题、扼杀性能、承诺大于实质 [80, 81, 82, 83]。许多云服务因运维麻烦索性不实现分布式事务 [84]。
某些分布式事务实现的性能代价沉重——2PC 固有的性能成本很大一部分来自崩溃恢复所需的额外 fsync 与额外网络往返。
不过与其一棒打死,我们应当再细看一番,因为里面有重要的教训。先把概念分清:所谓"分布式事务"常混淆两种截然不同的类型:
数据库内部分布式事务
某些分布式数据库(即默认就启用复制和分片的那种)在内部支持其节点之间的事务。例如 YugabyteDB、TiDB、FoundationDB、Spanner、VoltDB、Cassandra,以及 MySQL Cluster 的 NDB 存储引擎,都自带这种内部事务支持。这种情况下,参与事务的所有节点跑的都是同一份数据库软件。
异构分布式事务
异构事务里的参与者是两种或更多技术——例如来自不同厂商的两个数据库,甚至非数据库系统(如消息代理)。跨这些系统的分布式事务必须保证原子提交,即便底层完全不同。
数据库内部事务不需要兼容其他系统,可以使用任意协议、做特定优化。因此数据库内部分布式事务往往工作得相当好。而跨异构技术的事务挑战要大得多。这里我们聚焦后者,下一节再谈数据库内部分布式事务。
恰好一次的消息处理
异构分布式事务能让多种系统得到强有力的集成。例如,只在处理消息的数据库事务成功提交时,才向消息队列确认该消息已处理。把消息确认与数据库写入原子地合并到同一事务里就能做到。有了分布式事务支持,即便消息代理与数据库是分布在不同机器上、完全不相关的两种技术,也照样能做到。
要是消息投递或数据库事务任一失败,两者都会被中止,消息代理可以稍后安全地重投。这种"原子地提交消息及其处理副作用"的做法,能保证消息实际上被恰好一次处理,即使重试了若干次才成功。中止会丢弃部分完成事务的所有副作用。这就是恰好一次语义。
只有当事务影响到的所有系统都用同一原子提交协议时,这种分布式事务才可行。比如说,处理消息的副作用之一是发邮件,但邮件服务器不支持 2PC——一旦处理失败后重试,邮件就可能被发两次或更多。但只要事务中止能回滚所有副作用,处理步骤就可以像没发生过一样安全重试。
恰好一次语义的话题我们稍后再谈。先来看让这种异构分布式事务成为可能的原子提交协议。
XA 事务
X/Open XA(eXtended Architecture 的缩写)是跨异构技术实现 2PC 的标准 [75]。1991 年提出,至今已被广泛采用。许多传统关系数据库(包括 PostgreSQL、MySQL、Db2、SQL Server、Oracle)和消息代理(包括 ActiveMQ、HornetQ、MSMQ、IBM MQ)都支持 XA。
XA 不是网络协议——它只是一个与事务协调者打交道的 C API,其他语言也有相应绑定;例如 Java EE 应用世界里,XA 事务用 Java Transaction API(JTA)实现,进而被许多使用 Java Database Connectivity(JDBC)的数据库驱动以及使用 Java Message Service(JMS)API 的消息代理驱动所支持。
XA 假定应用通过网络驱动或客户端库与参与其中的数据库或消息服务通信。如果驱动支持 XA,那就意味着可以调用 XA API 判断某操作是否应作为分布式事务的一部分——若是,就把必要信息发给数据库服务器。驱动还暴露回调,让协调者可以调用它来要求参与者 prepare、commit 或 abort。
事务协调者实现 XA API。标准没规定它该如何实现,实践中协调者通常就是一个加载到与发起事务的应用同一进程的库(而不是单独的服务)。它跟踪事务的参与者,发完 prepare 后收集响应(通过对驱动的回调),并把每个事务的提交/中止决定写到本地磁盘的日志里。
应用进程崩溃,或运行应用的机器挂了,协调者也跟着挂。任何处于 prepared 但未提交状态的参与者就卡在疑虑状态。协调者的日志在应用服务器本地磁盘上,所以那台服务器必须重启,让协调者库读日志恢复每个事务的提交/中止结果,然后通过数据库驱动的 XA 回调要求参与者提交或中止。数据库服务器无法直接联系协调者——所有通信都必须走客户端库。
疑虑期间持有锁
为什么要对"事务卡在疑虑"这么在意?系统其余部分难道不能继续工作、忽略这个稍后会被清理的疑虑事务吗?
问题在于锁。如第 290 页"读已提交"所述,数据库事务通常会对修改的行取行级独占锁以防脏写。要可串行化隔离的话,使用 2PL 的数据库还要对读取的行取共享锁。
事务在提交或中止之前不能释放这些锁(图 8-13 中的灰色阴影区域)。所以使用 2PC 时,事务必须在整个疑虑期间一直持有这些锁。协调者要是崩溃了、20 分钟才重启回来,这些锁就被持有 20 分钟。要是协调者的日志因为什么原因彻底丢了,这些锁就被永远持有——或者至少要管理员手动来解决。
这些锁被持有期间,其他事务无法修改这些行;视隔离级别而定,其他事务可能连读都不被允许。也就是说,其他事务无法继续做自己的事——只要它们想访问那些数据就会被阻塞。这会让应用的大部分功能不可用,直到疑虑事务被解决。
从协调者失败中恢复
理论上,协调者崩溃后重启时,应该能干净地从日志恢复状态、解决疑虑事务。然而实践中确实会出现孤儿疑虑事务 [85, 86]——也就是协调者无论如何都决定不了的事务(例如事务日志因软件 bug 丢失或损坏)。这些事务无法自动解决,永远滞留在数据库里持锁、阻塞其他事务。
即便重启数据库服务器也解决不了,因为 2PC 的正确实现必须在重启之间也保留疑虑事务的锁(否则就有违反原子性的风险)。这是一处棘手的境地。
唯一的出路是管理员手动判定提交还是回滚事务。管理员要逐个排查每个疑虑事务的参与者,看是否有任一参与者已提交或中止,再对其余参与者套用同样的结果。解决这个问题可能需要大量人工,而且最有可能是在严重生产故障期间、压力山大时间紧迫的情况下进行(不然协调者怎么会落到如此糟糕的状态?)。
许多 XA 实现都有一种叫启发式决策(heuristic decisions)的紧急逃生口:允许参与者在没有协调者明确决定的情况下,单方面中止或提交疑虑事务 [75]。说白了,这里的 heuristic 是"很可能破坏原子性"的委婉说法,因为启发式决策违反了 2PC 的承诺系统。所以启发式决策只用于脱离灾难,常规情况下不该用。
XA 事务的问题
单节点协调者是整个系统的单点故障,把它塞在应用服务器里也很麻烦——协调者的日志成了关键的持久系统状态(与数据库本身同等重要)。
原则上 XA 事务的协调者也可以做高可用、做复制,就像我们对其他重要数据库的期望一样。可惜这并不能解决 XA 的一个根本问题:它没有办法让协调者与事务参与者直接互通。它们只能通过调用参与者的应用代码与数据库驱动来通信。
即便协调者做了复制,应用代码仍是单点故障。要解决这一点,就要彻底重新设计应用代码的运行方式,让它可复制或可重启,可能与持久执行类似(见第 187 页"持久执行与工作流")。但实践中似乎并没有走这条路的工具。
另一个问题是:由于 XA 要兼容广泛的数据系统,它注定是最低公分母。例如它无法跨不同系统检测死锁(这需要一个标准协议来交换"每个事务在等什么锁"的信息),也无法与 SSI 协同工作(这需要一个能识别跨不同系统冲突的协议;见第 317 页"可串行化快照隔离")。
这些问题中有一些是跨异构技术事务所固有的。然而让多个异构数据系统保持一致仍是一个真实而重要的问题,需要别的方案。下一节及第 12 章会讨论。
数据库内部分布式事务
如前所述,跨多种异构存储技术的分布式事务,与局限在单一系统内(即所有参与节点都属于同一数据库、跑同一份软件)的分布式事务有很大不同。这种内部分布式事务是 CockroachDB [5]、TiDB [6]、Spanner [7]、FoundationDB [8]、YugabyteDB 等"NewSQL"数据库的标志性特性。一些消息代理(如 Kafka)也支持内部分布式事务 [87]。
许多此类系统用 2PC 来保证写到多分片的事务的原子性,但它们没有 XA 事务的那些问题。因为它们的分布式事务不需要与其他技术对接,避免了最低公分母陷阱——这些系统的设计者可以自由采用更可靠、更快的协议。
XA 的最大问题可以这样修复:
- 对协调者做复制,主协调者崩溃时自动故障转移到另一协调者节点;
- 让协调者与数据分片直接通信,不经中间的应用代码;
- 对参与分片做复制,降低因某一分片故障而必须中止事务的风险;
- 把原子提交协议与分布式并发控制协议(支持死锁检测与跨分片一致读)耦合在一起。
共识算法常被用来对协调者和数据库分片做复制。第 10 章会看到分布式事务的原子提交如何用共识算法实现。这些算法通过自动从一个节点故障转移到另一个节点来容错,无需任何人工干预,同时仍能提供强一致性保证。
分布式事务能提供的隔离级别因系统而异,但快照隔离 [6] 与可串行化快照隔离 [5, 8] 都可以跨分片实现。
重新审视恰好一次消息处理
我们在第 329 页"恰好一次的消息处理"中看到,分布式事务的一个重要用例是确保操作恰好生效一次,即便处理过程中发生崩溃、需要重试。如果你能跨消息代理与数据库原子地提交事务,就可以做到:当且仅当处理产生的数据库写入成功提交时,才向代理确认消息。
但其实不靠分布式事务也能实现恰好一次语义。一种替代做法只需要数据库内的事务:
- 假设每条消息有唯一 ID,数据库里有一张已处理消息 ID 表。开始处理代理消息时,在数据库上开启新事务,检查消息 ID。若同 ID 已存在,说明已处理过,可直接向代理确认并丢弃该消息。
- 若 ID 不存在,把它加入表中。然后处理消息(可能在同一事务里产生其他写入)。处理完后提交事务。
- 数据库事务提交成功后,再向代理确认消息。
- 成功向代理确认后,你就知道它不会再被处理,可以在另一个独立事务里删掉该消息 ID。
如果消息处理器在数据库事务提交之前崩溃,事务被中止,代理会重投。崩溃发生在提交之后、但向代理确认之前的话,处理仍会重试,但重试时数据库里看到该 ID,会丢弃。崩溃发生在向代理确认之后、但删除消息 ID 之前的话,会在数据库里留下旧消息 ID 占点空间,但不会造成其他问题。代理与数据库通信中断导致重试发生在事务被中止之前的话,消息 ID 表上的唯一性约束就能阻止两个并发事务插入同一 ID。
因此实现恰好一次处理只需要数据库内的事务——不需要数据库与消息代理之间的原子性。在数据库里记录消息 ID,让消息处理变得幂等,便可以安全重试而不会引发重复副作用。Kafka Streams 等流处理框架也用类似做法实现恰好一次语义,第 12 章会讨论。
不过数据库内部分布式事务对这类模式的可扩展性仍很有用:例如可以让消息 ID 存到一个分片、处理产生的主数据更新到其他分片,并仍能保证跨分片事务的原子提交。
小结
事务是一层抽象,让应用可以假装某些并发问题以及某些软硬件故障不存在。一大类错误被简化为简单的事务中止,应用只需重试即可。
本章看了许多事务能帮你绕开的问题。并非所有应用都会撞上所有这些问题:访问模式很简单的应用(如只读写一条记录)大概不需要事务。但访问模式更复杂的应用,事务能极大减少需要考虑的潜在错误情形。
没有事务时,各种错误场景(进程崩溃、网络中断、断电、磁盘满、意外并发等)会让数据以多种方式失去一致性。例如反规范化数据可能与源数据失同步。没有事务,就很难推理复杂的交互式访问对数据库的影响。
本章特别深入了并发控制这一话题,讨论了几种被广泛使用的隔离级别:读已提交、快照(有时叫可重复读)和可串行化。我们通过讨论各种竞态例子来刻画这些隔离级别,总结见表 8-1。
| 隔离级别 | 脏读 | 读偏斜 | 幻读 | 丢失更新 | 写偏斜 |
|---|---|---|---|---|---|
| 读未提交 | ✗ 可能 | ✗ 可能 | ✗ 可能 | ✗ 可能 | ✗ 可能 |
| 读已提交 | ✓ 防止 | ✗ 可能 | ✗ 可能 | ✗ 可能 | ✗ 可能 |
| 快照隔离 | ✓ 防止 | ✓ 防止 | ✓ 防止 | ? 视实现 | ✗ 可能 |
| 可串行化 | ✓ 防止 | ✓ 防止 | ✓ 防止 | ✓ 防止 | ✓ 防止 |
简要回顾:
脏读
某客户端读到了另一客户端尚未提交的写入。读已提交及更强级别可以防止脏读。
脏写
某客户端覆盖了另一客户端已写入但尚未提交的数据。几乎所有事务实现都会防止脏写(因此未列入表中)。
读偏斜
客户端在不同时间点看到数据库的不同部分。有些读偏斜被称为不可重复读。这一问题最常用快照隔离来防止——它允许事务从某一时点对应的一致快照读。快照隔离通常用 MVCC 实现。
幻读
事务读取了匹配某搜索条件的对象。另一客户端做了影响该搜索结果的写入。快照隔离能防住直白的幻读,但写偏斜语境下的幻读需要特殊处理(如索引范围锁)。
丢失更新
两个客户端并发执行读-改-写循环,其中一个覆盖了另一个的写入、又没有合并它的更改,数据就此丢失。一些快照隔离实现会自动防住这一异常,另一些则需要手动加锁(SELECT FOR UPDATE)。
写偏斜
事务读到某值后据此做决定并写回数据库;但写入时该决定所依据的前提已不再为真。只有可串行化隔离能防住这一异常。
弱隔离级别能挡住一部分异常,但要求你(应用开发者)手动处理另一部分(例如显式加锁)。只有可串行化隔离能挡住所有这些问题。我们讨论了实现可串行化的三种方法:
字面意义上以串行顺序执行事务
如果能让每个事务执行得非常快(通常用存储过程),且事务吞吐量低到一个 CPU 核就能处理、或可以分片,这就是个简单有效的选项。
两阶段锁
几十年里 2PL 一直是实现可串行化的标准方式,但许多应用因其性能差而避免使用。
可串行化快照隔离
SSI 是相对较新的算法,绕开了前两种方法的大多数缺点。它以乐观方式让事务无阻塞地推进。事务想提交时再做检查,如果执行不可串行化就中止。
最后我们考察了用 2PC 跨多节点分布事务时如何实现原子性。如果这些节点都跑同一份数据库软件,分布式事务可以工作得很好。但跨不同存储技术(用 XA 事务)时,2PC 麻烦多多;它对协调者及发起事务的应用代码中的故障非常敏感,与并发控制机制的配合也不佳。所幸幂等性可以保证恰好一次语义,无需跨不同存储技术的原子提交;后续章节会进一步讨论。
本章的例子用的是关系数据模型。但正如第 287 页"对多对象事务的需要"所述,无论使用哪种数据模型,事务都是一项有价值的数据库特性。
参考文献
[1] Steven J. Murdoch. "What Went Wrong with Horizon: Learning from the Post Office Trial." benthamsgaze.org, July 2021. 归档于 perma.cc/CNM4-553F
[2] Donald D. Chamberlin, Morton M. Astrahan, Michael W. Blasgen, James N. Gray, W. Frank King, Bruce G. Lindsay, Raymond Lorie, James W. Mehl, Thomas G. Price, Franco Putzolu, Patricia Griffiths Selinger, Mario Schkolnick, Donald R. Slutz, Irving L. Traiger, Bradford W. Wade, Robert A. Yost. "A History and Evaluation of System R." Communications of the ACM, volume 24, issue 10, pages 632–646, October 1981. doi:10.1145/358769.358784
[3] Jim N. Gray, Raymond A. Lorie, Gianfranco R. Putzolu, Irving L. Traiger. "Granularity of Locks and Degrees of Consistency in a Shared Data Base." 见 Modelling in Data Base Management Systems: Proceedings of the IFIP Working Conference, edited by G. M. Nijssen, pages 364–394, Elsevier/North Holland Publishing, 1976. 也收录于 Readings in Database Systems, 4th edition, MIT Press, 2005. ISBN: 9780262693141
[4] Kapali P. Eswaran, Jim N. Gray, Raymond A. Lorie, Irving L. Traiger. "The Notions of Consistency and Predicate Locks in a Database System." Communications of the ACM, volume 19, issue 11, pages 624–633, November 1976. doi:10.1145/360363.360369
[5] Rebecca Taft 等. "CockroachDB: The Resilient Geo-Distributed SQL Database." 见 ACM SIGMOD International Conference on Management of Data (SIGMOD), June 2020. doi:10.1145/3318464.3386134
[6] Dongxu Huang 等. "TiDB: A Raft-Based HTAP Database." Proceedings of the VLDB Endowment, volume 13, issue 12, pages 3072–3084, August 2020. doi:10.14778/3415478.3415535
[7] James C. Corbett 等. "Spanner: Google's Globally-Distributed Database." 见 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012.
[8] Jingyu Zhou 等. "FoundationDB: A Distributed Unbundled Transactional Key Value Store." 见 ACM SIGMOD International Conference on Management of Data (SIGMOD), June 2021. doi:10.1145/3448016.3457559
[9] Theo Härder, Andreas Reuter. "Principles of Transaction-Oriented Database Recovery." ACM Computing Surveys, volume 15, issue 4, pages 287–317, December 1983. doi:10.1145/289.291
[10] Peter Bailis, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein, Ion Stoica. "HAT, not CAP: Towards Highly Available Transactions." 见 14th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2013.
[11] Armando Fox, Steven D. Gribble, Yatin Chawathe, Eric A. Brewer, Paul Gauthier. "Cluster-Based Scalable Network Services." 见 16th ACM Symposium on Operating Systems Principles (SOSP), October 1997. doi:10.1145/268998.266662
[12] Tony Andrews. "Enforcing Complex Constraints in Oracle." tonyandrews.blogspot.co.uk, October 2004. 归档于 archive.org
[13] Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman. Concurrency Control and Recovery in Database Systems. Addison-Wesley, 1987. ISBN: 9780201107159. 在线可读 microsoft.com。
[14] Alan Fekete, Dimitrios Liarokapis, Elizabeth O'Neil, Patrick O'Neil, Dennis Shasha. "Making Snapshot Isolation Serializable." ACM Transactions on Database Systems, volume 30, issue 2, pages 492–528, June 2005. doi:10.1145/1071610.1071615
[15] Mai Zheng, Joseph Tucek, Feng Qin, Mark Lillibridge. "Understanding the Robustness of SSDs Under Power Fault." 见 11th USENIX Conference on File and Storage Technologies (FAST), February 2013.
[16] Laurie Denness. "SSDs: A Gift and a Curse." laur.ie, June 2015. 归档于 perma.cc/6GLP-BX3T
[17] Adam Surak. "When Solid State Drives Are Not That Solid." blog.algolia.com, June 2015. 归档于 perma.cc/CBR9-QZEE
[18] Hewlett Packard Enterprise. "Bulletin: HPE SAS Solid State Drives—Critical Firmware Upgrade Required for Certain HPE SAS Solid State Drive Models to Prevent Drive Failure at 32,768 Hours of Operation." support.hpe.com, November 2019. 归档于 perma.cc/CZR4-AQBS
[19] Craig Ringer 等. "PostgreSQL's Handling of fsync() Errors Is Unsafe and Risks Data Loss at Least on XFS." Email thread on pgsql-hackers mailing list, postgresql.org, March 2018. 归档于 perma.cc/5RKU-57FL
[20] Anthony Rebello, Yuvraj Patel, Ramnatthan Alagappan, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau. "Can Applications Recover from fsync Failures?" 见 USENIX Annual Technical Conference (ATC), July 2020.
[21] Thanumalayan Sankaranarayana Pillai 等. "Crash Consistency: Rethinking the Fundamental Abstractions of the File System." ACM Queue, volume 13, issue 7, pages 20–28, July 2015. doi:10.1145/2800695.2801719
[22] Thanumalayan Sankaranarayana Pillai 等. "All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications." 见 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), October 2014.
[23] Chris Siebenmann. "Unix's File Durability Problem." utcc.utoronto.ca, April 2016. 归档于 perma.cc/VSS8-5MC4
[24] Aishwarya Ganesan 等. "Redundancy Does Not Imply Fault Tolerance: Analysis of Distributed Storage Reactions to Single Errors and Corruptions." 见 15th USENIX Conference on File and Storage Technologies (FAST), February 2017.
[25] Lakshmi N. Bairavasundaram 等. "An Analysis of Data Corruption in the Storage Stack." 见 6th USENIX Conference on File and Storage Technologies (FAST), February 2008.
[26] Richard van der Hoff. "How We Discovered, and Recovered from, Postgres Corruption on the matrix.org Homeserver." matrix.org, July 2025. 归档于 perma.cc/CDF5-NRBK
[27] Bianca Schroeder, Raghav Lagisetty, Arif Merchant. "Flash Reliability in Production: The Expected and the Unexpected." 见 14th USENIX Conference on File and Storage Technologies (FAST), February 2016.
[28] Don Allison. "SSD Storage—Ignorance of Technology Is No Excuse." blog.korelogic.com, March 2015. 归档于 perma.cc/9QN4-9SNJ
[29] Gordon Mah Ung. "Debunked: Your SSD Won't Lose Data If Left Unplugged After All." pcworld.com, May 2015. 归档于 perma.cc/S46H-JUDU
[30] Martin Kleppmann. "Hermitage: Testing the 'I' in ACID." martin.kleppmann.com, November 2014. 归档于 perma.cc/KP2Y-AQGK
[31] Vlad Mihalcea. "The Race Condition That Led to Flexcoin Bankruptcy." vladmihalcea.com, February 2025. 归档于 perma.cc/RRK5-TFAU
[32] Todd Warszawski, Peter Bailis. "ACIDRain: Concurrency-Related Attacks on Database-Backed Web Applications." 见 ACM International Conference on Management of Data (SIGMOD), May 2017. doi:10.1145/3035918.3064037
[33] Tristan D'Agosta. "BTC Stolen from Poloniex." bitcointalk.org, March 2014. 归档于 perma.cc/YHA6-4C5D
[34] bitcointhief2. "How I Stole Roughly 100 BTC from an Exchange and How I Could Have Stolen More!" reddit.com, February 2014. 归档于 archive.org
[35] Sudhir Jorwekar 等. "Automating the Detection of Snapshot Isolation Anomalies." 见 33rd International Conference on Very Large Data Bases (VLDB), September 2007.
[36] Michael Melanson. "Transactions: The Limits of Isolation." michaelmelanson.net, November 2014. 归档于 perma.cc/RG5R-KMYZ
[37] Edward Kim. "How ACH Works: A Developer Perspective—Part 1." engineering.gusto.com, April 2014. 归档于 perma.cc/7B2H-PU94
[38] Hal Berenson 等. "A Critique of ANSI SQL Isolation Levels." 见 ACM International Conference on Management of Data (SIGMOD), May 1995. doi:10.1145/568271.223785
[39] Atul Adya. "Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions." PhD thesis, Massachusetts Institute of Technology, March 1999. 归档于 perma.cc/E97M-HW5Q
[40] Peter Bailis 等. "Highly Available Transactions: Virtues and Limitations." Proceedings of the VLDB Endowment, volume 7, issue 3, pages 181–192, November 2013. doi:10.14778/2732232.2732237
[41] Natacha Crooks 等. "Seeing Is Believing: A Client-Centric Specification of Database Isolation." 见 ACM Symposium on Principles of Distributed Computing (PODC), July 2017. doi:10.1145/3087801.3087802
[42] Bruce Momjian. "MVCC Unmasked." momjian.us, July 2014. 归档于 perma.cc/KQ47-9GYB
[43] Peter Alvaro, Kyle Kingsbury. "MySQL 8.0.34." jepsen.io, December 2023. 归档于 perma.cc/HGE2-Z878
[44] Egor Rogov. PostgreSQL 14 Internals. Postgres Professional, April 2023. 归档于 perma.cc/FRK2-D7WB
[45] Hironobu Suzuki. "The Internals of PostgreSQL." interdb.jp, 2017.
[46] Rohan Reddy Alleti. "Internals of MVCC in Postgres: Hidden Costs of Updates vs Inserts." medium.com, March 2025. 归档于 perma.cc/3ACX-DFXT
[47] Andy Pavlo, Bohan Zhang. "The Part of PostgreSQL We Hate the Most." cs.cmu.edu, April 2023. 归档于 perma.cc/XSP6-3JBN
[48] Yingjun Wu 等. "An Empirical Evaluation of In-Memory Multi-Version Concurrency Control." Proceedings of the VLDB Endowment, volume 10, issue 7, pages 781–792, March 2017. doi:10.14778/3067421.3067427
[49] Nikita Prokopov. "Unofficial Guide to Datomic Internals." tonsky.me, May 2014. 归档于 perma.cc/ULM2-T2FW
[50] Daniil Svetlov. "A Practical Guide to Taming Postgres Isolation Anomalies." dansvetlov.me, March 2025. 归档于 perma.cc/L7LE-TDLS
[51] Nate Wiger. "An Atomic Rant." nateware.com, February 2010. 归档于 perma.cc/5ZYB-PE44
[52] James Coglan. "Reading and Writing, Part 3: Web Applications." blog.jcoglan.com, October 2020. 归档于 perma.cc/A7EK-PJVS
[53] Peter Bailis 等. "Feral Concurrency Control: An Empirical Investigation of Modern Application Integrity." 见 ACM International Conference on Management of Data (SIGMOD), June 2015. doi:10.1145/2723372.2737784
[54] Jaana Dogan. "Things I Wished More Developers Knew About Databases." rakyll.medium.com, April 2020. 归档于 perma.cc/6EFK-P2TD
[55] Michael J. Cahill, Uwe Röhm, Alan Fekete. "Serializable Isolation for Snapshot Databases." 见 ACM International Conference on Management of Data (SIGMOD), June 2008. doi:10.1145/1376616.1376690
[56] Dan R. K. Ports, Kevin Grittner. "Serializable Snapshot Isolation in PostgreSQL." Proceedings of the VLDB Endowment, volume 5, issue 12, pages 1850–1861, August 2012. doi:10.14778/2367502.2367523
[57] Douglas B. Terry 等. "Managing Update Conflicts in Bayou, a Weakly Connected Replicated Storage System." 见 15th ACM Symposium on Operating Systems Principles (SOSP), December 1995. doi:10.1145/224056.224070
[58] Hans-Jürgen Schönig. "Constraints over Multiple Rows in PostgreSQL." cybertec-postgresql.com, June 2021. 归档于 perma.cc/2TGH-XUPZ
[59] Michael Stonebraker 等. "The End of an Architectural Era (It's Time for a Complete Rewrite)." 见 33rd International Conference on Very Large Data Bases (VLDB), September 2007.
[60] John Hugg. "H-Store/VoltDB Architecture vs. CEP Systems and Newer Streaming Architectures." 见 Data @Scale Boston, November 2014.
[61] Robert Kallman 等. "H-Store: A High-Performance, Distributed Main Memory Transaction Processing System." Proceedings of the VLDB Endowment, volume 1, issue 2, pages 1496–1499, August 2008. doi:10.14778/1454159.1454211
[62] Rich Hickey. "The Architecture of Datomic." infoq.com, November 2012. 归档于 perma.cc/5YWU-8XJK
[63] John Hugg. "Debunking Myths About the VoltDB In-Memory Database." dzone.com, May 2014. 归档于 perma.cc/2Z9N-HPKF
[64] Xinjing Zhou, Viktor Leis, Xiangyao Yu, Michael Stonebraker. "OLTP Through the Looking Glass 16 Years Later: Communication Is the New Bottleneck." 见 15th Annual Conference on Innovative Data Systems Research (CIDR), January 2025. 归档于 perma.cc/Q33D-K9YE
[65] Xinjing Zhou 等. "Lotus: Scalable Multi-Partition Transactions On Single-Threaded Partitioned Databases." Proceedings of the VLDB Endowment (PVLDB), volume 15, issue 11, pages 2939–2952, July 2022. doi:10.14778/3551793.3551843
[66] Joseph M. Hellerstein, Michael Stonebraker, James Hamilton. "Architecture of a Database System." Foundations and Trends in Databases, volume 1, issue 2, pages 141–259, November 2007. doi:10.1561/1900000002
[67] Michael J. Cahill. "Serializable Isolation for Snapshot Databases." PhD thesis, University of Sydney, July 2009. 归档于 perma.cc/727J-NTMP
[68] Cristian Diaconu 等. "Hekaton: SQL Server's Memory-Optimized OLTP Engine." 见 ACM SIGMOD International Conference on Management of Data (SIGMOD), June 2013. doi:10.1145/2463676.2463710
[69] Thomas Neumann, Tobias Mühlbauer, Alfons Kemper. "Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems." 见 ACM SIGMOD International Conference on Management of Data (SIGMOD), May 2015. doi:10.1145/2723372.2749436
[70] D. Z. Badal. "Correctness of Concurrency Control and Implications in Distributed Databases." 见 3rd International IEEE Computer Software and Applications Conference (COMPSAC), November 1979. doi:10.1109/CMPSAC.1979.762563
[71] Rakesh Agrawal, Michael J. Carey, Miron Livny. "Concurrency Control Performance Modeling: Alternatives and Implications." ACM Transactions on Database Systems (TODS), volume 12, issue 4, pages 609–654, December 1987. doi:10.1145/32204.32220
[72] Marc Brooker. "Snapshot Isolation vs. Serializability." brooker.co.za, December 2024. 归档于 perma.cc/5TRC-CR5G
[73] B. G. Lindsay 等. "Notes on Distributed Databases." IBM Research, Research Report RJ2571(33471), July 1979. 归档于 perma.cc/EPZ3-MHDD
[74] C. Mohan, Bruce G. Lindsay, Ron Obermarck. "Transaction Management in the R* Distributed Database Management System." ACM Transactions on Database Systems, volume 11, issue 4, pages 378–396, December 1986. doi:10.1145/7239.7266
[75] X/Open Company Ltd. "Distributed Transaction Processing: The XA Specification." Technical Standard XO/CAE/91/300, December 1991. ISBN: 9781872630243, 归档于 perma.cc/Z96H-29JB
[76] Ivan Silva Neto, Francisco Reverbel. "Lessons Learned from Implementing WS-Coordination and WS-AtomicTransaction." 见 7th IEEE/ACIS International Conference on Computer and Information Science (ICIS), May 2008. doi:10.1109/ICIS.2008.75
[77] James E. Johnson 等. "Formal Specification of a Web Services Protocol." 见 1st International Workshop on Web Services and Formal Methods (WS-FM), February 2004. doi:10.1016/j.entcs.2004.02.022
[78] Jim Gray. "The Transaction Concept: Virtues and Limitations." 见 7th International Conference on Very Large Data Bases (VLDB), September 1981.
[79] Dale Skeen. "Nonblocking Commit Protocols." 见 ACM International Conference on Management of Data (SIGMOD), April 1981. doi:10.1145/582318.582339
[80] Gregor Hohpe. "Your Coffee Shop Doesn't Use Two-Phase Commit." IEEE Software, volume 22, issue 2, pages 64–66, March 2005. doi:10.1109/MS.2005.52
[81] Pat Helland. "Life Beyond Distributed Transactions: An Apostate's Opinion." 见 3rd Biennial Conference on Innovative Data Systems Research (CIDR), January 2007. 归档于 perma.cc/FC4F-AHGH
[82] Jonathan Oliver. "My Beef with MSDTC and Two-Phase Commits." blog.jonathanoliver.com, April 2011. 归档于 perma.cc/K8HF-Z4EN
[83] Oren Eini (Ahende Rahien). "The Fallacy of Distributed Transactions." ayende.com, July 2014. 归档于 perma.cc/VB87-2JEF
[84] Clemens Vasters. "Transactions in Windows Azure (with Service Bus)—An Email Discussion." learn.microsoft.com, July 2012. 归档于 perma.cc/4EZ9-5SKW
[85] Ajmer Dhariwal. "Orphaned MSDTC Transactions (-2 spids)." eraofdata.com, December 2008. 归档于 perma.cc/YG6F-U34C
[86] Paul Randal. "Real World Story of DBCC PAGE Saving the Day." sqlskills.com, June 2013. 归档于 perma.cc/2MJN-A5QH
[87] Guozhang Wang 等. "Consistency and Completeness: Rethinking Distributed Stream Processing in Apache Kafka." 见 ACM International Conference on Management of Data (SIGMOD), June 2021. doi:10.1145/3448016.3457556